The Problem: VLA Models Hit a Ceiling After SFT
Vision-Language-Action (VLA) models are the dominant approach for robot manipulation today. Models like OpenVLA, RT-2, and Pi0 have demonstrated that combining vision, language, and action in a single foundation model can produce powerful robot policies.
However, nearly all current VLAs are trained using Supervised Fine-Tuning (SFT) -- learning to imitate actions from human demonstration data. This approach has a fundamental limitation: the model can only be as good as its training data, never better.
Think of it like learning to drive by watching videos of other people driving. You can pick up the basic maneuvers, but when you encounter a novel situation -- an unfamiliar road, an unexpected obstacle -- you won't know what to do. You need to actually drive and receive feedback to truly improve.
That is exactly what SimpleVLA-RL addresses.

What is SimpleVLA-RL?
SimpleVLA-RL is a framework presented at ICLR 2026 that improves VLA models through online reinforcement learning using an extremely simple reward signal: 0 or 1 (failure or success). No complex reward function design, no reward shaping, no dense rewards.
The core idea:
- Start from a VLA that has already been SFT-trained (e.g., OpenVLA-OFT)
- Let the robot explore through trial and error in simulation with binary reward
- Update the policy using RL (specifically a PPO variant)
- Result: The VLA improves far beyond SFT limits
Why is Binary Reward Sufficient?
In traditional RL for robotics, designing reward functions is a dark art (and a nightmare). You typically need to:
- Measure gripper-to-object distance
- Reward each step that moves closer to the goal
- Penalize energy-wasting actions
- Balance dozens of reward coefficients
SimpleVLA-RL proves that none of this is necessary if you start from a VLA that already has foundational knowledge from SFT. The model already knows how to grasp, how to move -- RL just needs to tell it whether it succeeded or not so it can self-optimize.
It's like coaching a skilled chef: you don't need to instruct every knife cut and every stir. You just taste the dish and say "good" or "not yet" -- the chef knows what to adjust.
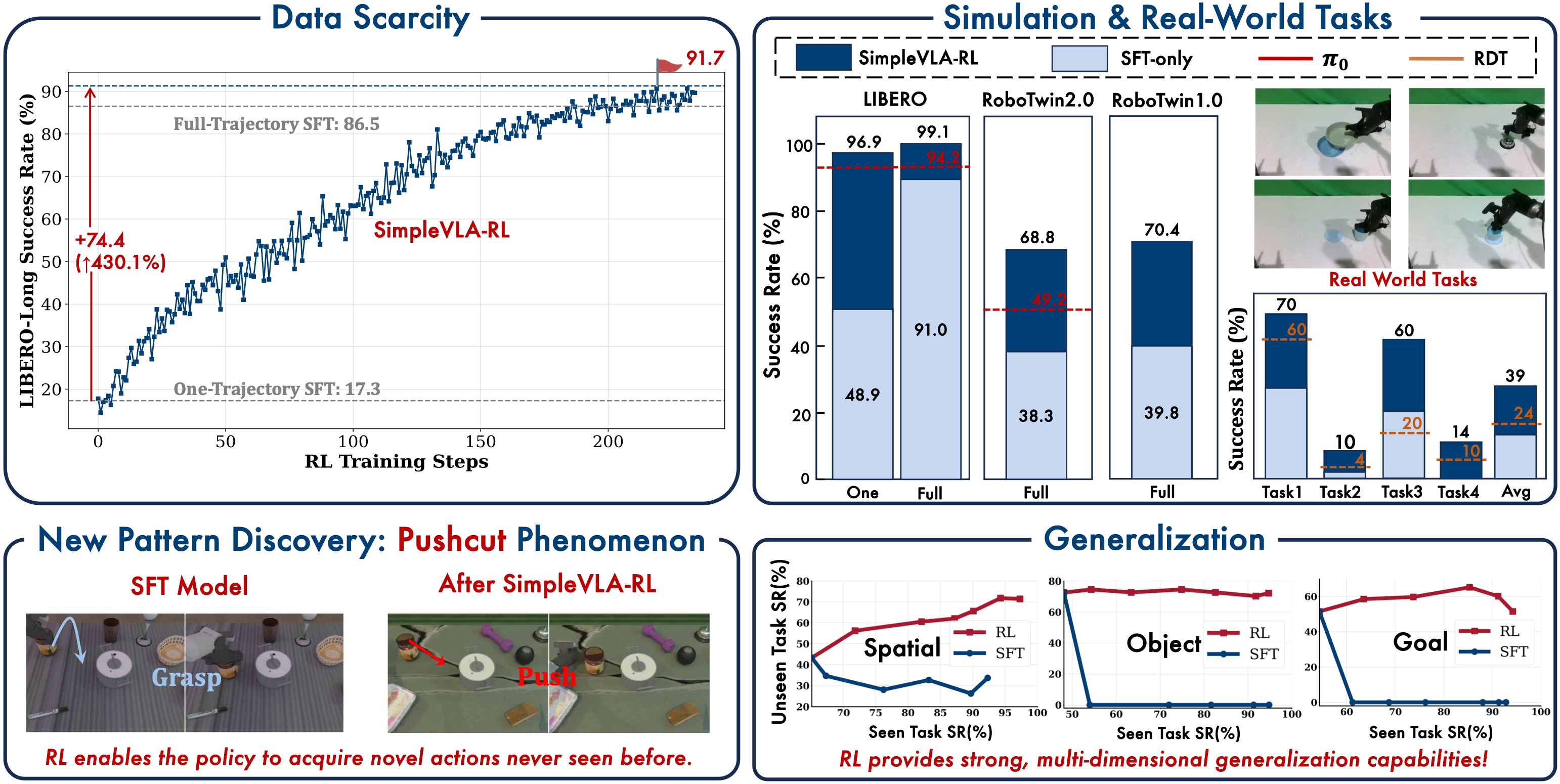
The "Pushcut" Phenomenon: RL Discovers Novel Actions
One of the most fascinating findings in SimpleVLA-RL is the "pushcut" phenomenon -- RL autonomously discovers entirely new actions that do not exist in any demonstration.
Specifically, in vegetable cutting tasks, humans demonstrated conventional knife-cutting motions. But after RL training, the robot discovered it could push the knife through the object (push + cut = pushcut) -- a technique no human demonstrator used, yet proved more effective for the robot given its specific gripper configuration.
This is powerful evidence that RL can liberate VLAs from the constraints of human data. The robot doesn't just imitate better -- it invents new approaches suited to its own physical capabilities.
Architecture: veRL + OpenVLA-OFT
SimpleVLA-RL is built on two core components:
OpenVLA-OFT (Policy Base)
OpenVLA-OFT is a fine-tuned version of OpenVLA using Orthogonal Fine-Tuning to improve performance on specific tasks. This serves as the starting point for RL training.
veRL (RL Framework)
veRL is a high-performance RL framework originally designed for Large Language Model training (RLHF). SimpleVLA-RL extends veRL to support:
- Multi-dimensional continuous action spaces (instead of discrete token generation)
- Parallel environment rollouts across multiple GPUs
- Reward signals from simulation (LIBERO, RoboTwin)
The training pipeline:
OpenVLA-OFT (SFT policy)
│
▼
veRL RL Training Loop
├── Rollout Workers (simulation environments)
├── Reward: binary 0/1 (task success/fail)
├── Policy Gradient (PPO-based)
└── KL Divergence constraint (prevent catastrophic forgetting)
│
▼
SimpleVLA-RL (improved policy)
A critical element is the KL divergence constraint -- it keeps the new policy from drifting too far from the original SFT policy. This prevents RL from causing the model to "forget" what it learned from SFT, a common problem known as catastrophic forgetting.

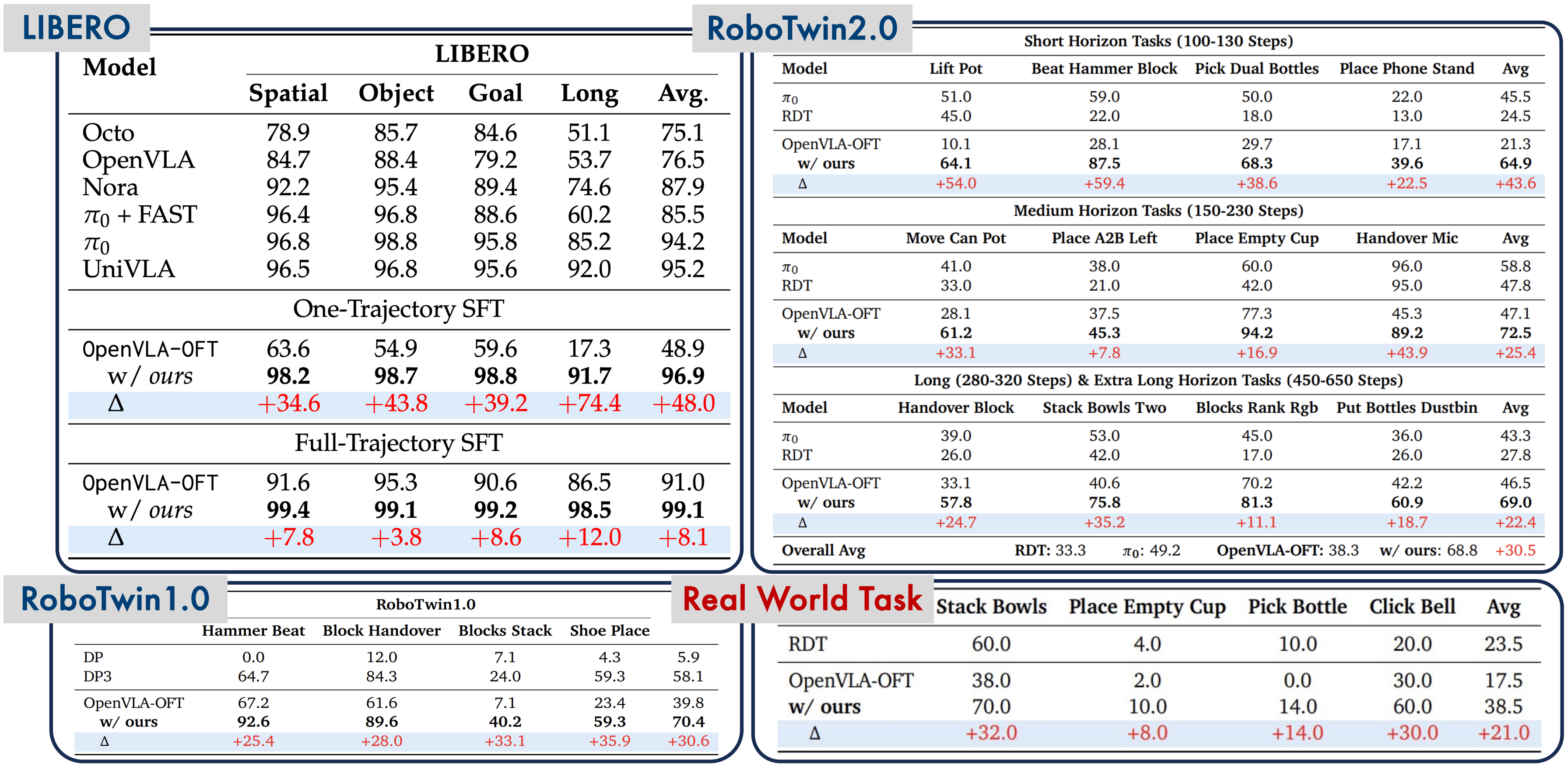
Results: The Numbers Speak for Themselves
LIBERO-Long Benchmark
| Method | Success Rate |
|---|---|
| OpenVLA-OFT (SFT only) | 85.4 |
| SimpleVLA-RL | 97.6 |
| Improvement | +12.2 points |
A 97.6% success rate on LIBERO-Long is state-of-the-art, significantly surpassing all SFT-only methods.
Cold-Start: The Miracle from 1 Trajectory
The most impressive result is the cold-start experiment: with only 1 trajectory per task (instead of hundreds of demonstrations), SimpleVLA-RL achieves:
| Setup | Success Rate |
|---|---|
| 1 demo + SFT only | 17.3 |
| 1 demo + SFT + RL | 91.7 |
| Improvement | +430% |
From 17.3 to 91.7 -- a 430% improvement -- with just 1 demonstration. The practical implications are enormous: you don't need to collect thousands of expensive demonstrations. Just 1 demo to "warm-start" the policy, then RL self-improves from there.
Real-World Results
On real-world dexterous manipulation tasks (not simulation), SimpleVLA-RL achieves approximately 300% improvement over the SFT baseline. Tasks include:
- Object grasping and placement
- Bottle cap opening
- Tool manipulation
The sim-to-real gap is significantly narrowed thanks to the more robust policy produced by RL training.
Comparison with Other Approaches
| Method | Strengths | Weaknesses |
|---|---|---|
| Pure SFT | Simple, stable | Limited by data quality |
| DAgger | Iterative, expert feedback | Requires continuous expert access |
| Offline RL | No environment needed | Hard to exceed data distribution |
| Online RL from scratch | No demos needed | Sample inefficient, needs reward engineering |
| SimpleVLA-RL | Binary reward, exceeds demos | Requires simulation environment |
SimpleVLA-RL occupies a "sweet spot": it leverages SFT knowledge without being constrained by it, while avoiding the complex reward engineering of traditional RL.
Installation and Training Guide
Hardware Requirements
- GPU: 8x NVIDIA A800 (80GB) or equivalent (A100 80GB)
- RAM: 256GB+ recommended
- Storage: 500GB+ for checkpoints and replay buffers
- Multi-node training supported for larger scale
Installation
# Clone repository
git clone https://github.com/PRIME-RL/SimpleVLA-RL.git
cd SimpleVLA-RL
# Create conda environment
conda create -n simplevla-rl python=3.10
conda activate simplevla-rl
# Install dependencies
pip install -e .
# Install veRL (RL framework)
pip install verl
# Install simulation environment (LIBERO)
pip install libero
Training
# Train on LIBERO benchmark
bash examples/run_openvla_oft_rl_libero.sh
This script will:
- Load the OpenVLA-OFT pretrained checkpoint
- Initialize LIBERO simulation environments
- Run the RL training loop with binary reward
- Save checkpoints periodically
Key Configuration
In the config file, the main hyperparameters:
# Number of parallel environments
num_envs: 64
# Binary reward
reward_type: "binary" # 0 or 1
# KL constraint (keep policy close to SFT)
kl_coeff: 0.01
# Training steps
total_steps: 50000
Supported Benchmarks
- LIBERO: Suite of long-horizon manipulation tasks
- RoboTwin: Bimanual manipulation benchmark
Significance and Future Directions
Why SimpleVLA-RL Matters
-
Breaks the SFT ceiling: First clear demonstration that online RL can push VLA far beyond demonstration data limits.
-
Democratizes robot learning: Binary reward = no reward engineering expertise needed. Anyone with a simulation environment can use it.
-
Data efficiency: Cold-starting from 1 demo fundamentally changes the data collection equation. Collecting 1 demo takes minutes instead of months for thousands.
-
Emergent behaviors: The pushcut phenomenon shows RL can generate novel behaviors -- robots don't just imitate, they create.
Future Development
The authors are working on extending SimpleVLA-RL to:
- Flow-matching RL: Applying to architectures like Pi0 and Pi0.5 that use flow matching instead of autoregressive generation
- More VLA architectures: Beyond OpenVLA to models like Octo and LAPA
- Sim-to-real pipeline: Automated policy transfer from simulation to physical robots
Personal Assessment
SimpleVLA-RL is one of the most important papers at ICLR 2026 for robot learning. It addresses exactly the problem the community has been struggling with: how to improve VLA after SFT has been exhausted.
What I appreciate most is the simplicity -- binary reward, no complex tricks, no magic hyperparameters. This is the hallmark of genuinely good research: a simple solution to a hard problem.
One caveat: this approach still requires high-quality simulation environments. If the sim-to-real gap is large, RL results in simulation may not transfer well to reality. But with the rapid advancement of simulation platforms like Isaac Sim and MuJoCo, this is becoming less of a concern.
Paper: SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning -- ICLR 2026
GitHub: PRIME-RL/SimpleVLA-RL

Related Posts
- AI for Robots: Reinforcement Learning Basics -- RL foundations to understand before reading SimpleVLA-RL
- VLA Models: Vision-Language-Action for Robots -- Overview of current VLA models
- Embodied AI 2026: Landscape and Trends -- The big picture of AI for robotics