Ψ₀ Hands-On (1): Overview & Key Ideas Behind the Foundation Model for Humanoids
Imagine you are standing in your kitchen. You walk back and forth between the fridge and the counter, grab a knife to chop vegetables, and keep your balance as you reach up to a high shelf for spices. For humans, this is so mundane that we do not even think about it. But for robots, this is one of the hardest unsolved problems in robotics: loco-manipulation — moving and manipulating objects at the same time.
And that is precisely the problem that Ψ₀ (pronounced "Psi-Zero") tackles. It is the first open-source foundation model that enables humanoid robots to perform loco-manipulation smoothly, developed by the USC Physical Superintelligence Lab (PSI Lab) in collaboration with NVIDIA.
In this Ψ₀ Hands-On series, we will go from understanding the core ideas to hands-on implementation, step by step. This first article gives you the big picture before we dive into the code.
Why Does Ψ₀ Matter?
Before we talk about architecture or algorithms, let us answer the most important question: why should you care about Ψ₀?

1. Superior Performance with Less Data
Ψ₀ outperforms the strongest current baselines — including NVIDIA's GR00T N1, Physical Intelligence's Pi0, and ACT — by a margin of over 40%, while using 10 times less robot data. Read that again: 10x less data, yet 40% better results. This runs counter to the "more data = better" intuition that the AI field typically assumes.
2. Solving a Genuinely Hard Problem
Loco-manipulation is not just adding locomotion and manipulation together. When a robot walks while holding an object, its center of gravity shifts continuously, reaction forces from the hands affect the legs, and every action must be coordinated within milliseconds. If you have read about whole-body control for humanoids, you know this is an extremely complex problem.
3. Fully Open-Source
Unlike many foundation models that publish a paper but keep the code private, Ψ₀ opens everything: model weights, training code, inference code, datasets, and the entire data processing pipeline. This means you — yes, you reading this article — can download, run, and fine-tune it for your own use case.
The Problem: Why Co-Training Fails
To understand what makes Ψ₀ special, we first need to understand why previous approaches struggled.
The Old Idea: Mixing Human and Robot Data
Many prior works attempted to train a single model on both human video data (abundantly available on the internet) and robot data (scarce and expensive). The idea sounds perfectly reasonable: humans and robots both manipulate objects, so human data should help robots learn faster.
But reality is far harsher. There is a problem called kinematic disparity — the mechanical differences between the human body and a robot body:
- The human hand has 27 degrees of freedom (DoF) with 5 dexterous fingers. Unitree's Dex3-1 hand has only 12 DoF with 3 fingers.
- The human arm is highly flexible, with the shoulder, elbow, and wrist forming a 7-DoF chain per side. A robot arm may have an entirely different kinematic structure.
- The camera viewpoint from a robot's head (egocentric) is completely different from a camera filming a person from the outside (exocentric).
When you force a model to learn simultaneously from two data sources with such different structures, it is like forcing someone to learn how to drive a car and fly a plane at the same time — both are "piloting," but the fundamental skills are so different that they interfere with each other.
Ψ₀'s New Idea: Divide and Conquer + Data Recipe
Ψ₀ does not try to throw everything into one pot. Instead, the research team realized that how you organize data and train in stages matters more than the amount of data you have. This is the core insight:
Staged training + data recipe > massive data
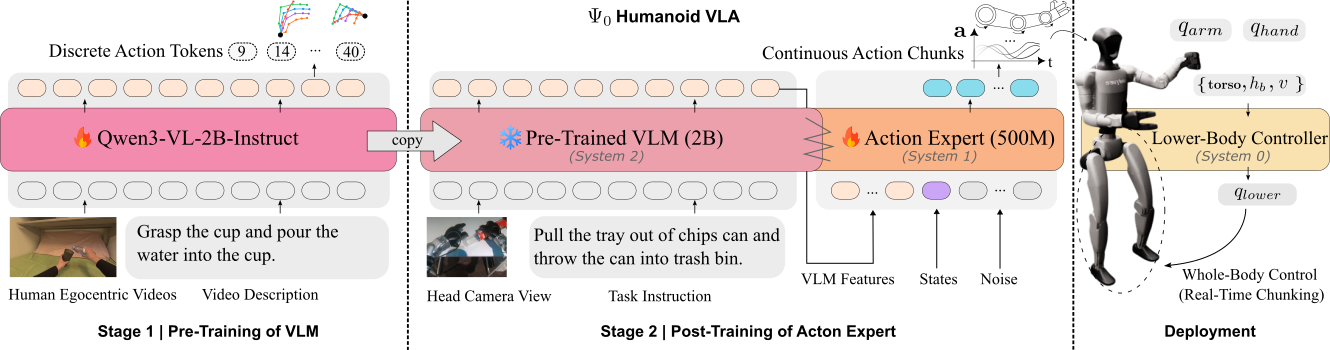
Specifically, Ψ₀ separates the problem into three distinct systems, each trained with the type of data best suited for it. And the magic lies in how they connect to each other.
Three Systems: Brain, Hands, and Legs
The easiest way to understand the Ψ₀ architecture is to think about how humans function. When you see a glass of water and decide to pick it up, three systems in your body coordinate:
-
Brain (System-2: Deliberation) — Your eyes see the glass, your brain processes the image, identifies the object, and makes the decision "pick up the glass." This is a slow process that requires thinking.
-
Hands (System-1: Action) — Once the brain decides, your hand automatically executes a sequence of actions: reach out, open the hand, grasp the glass, lift it up. This process is fast, nearly reflexive, requiring no step-by-step thinking.
-
Legs (System-0: Balance) — Throughout the process, your legs automatically adjust to maintain balance. You never think about your legs when picking up a glass — they operate entirely on autopilot.

Ψ₀ mirrors this structure precisely:
| System | Name | Model | Parameters | Role |
|---|---|---|---|---|
| System-2 | VLM (Vision-Language Model) | Qwen3-VL-2B | 2 billion | See + understand language |
| System-1 | Action Expert (MM-DiT) | Multi-Modal DiT | ~500 million | Generate actions for hands + upper body |
| System-0 | Locomotion Controller | RL Policy (AMO) | Small | Control legs + maintain balance |
The crucial point is that these three systems are trained separately, each with the data type that is optimal for it. This is the "divide and conquer" approach — rather than forcing a single massive model to learn everything, Ψ₀ splits the problem into three specialized parts.
If you want to learn more about VLA models in general, you can read our introduction to VLA models in the AI for Robots series.
Three Training Stages: From Watching YouTube to Professional Chef
To explain the 3-stage training pipeline of Ψ₀, let us use an analogy everyone can relate to: learning to cook.
Stage 1: Watching YouTube (Pre-training on egocentric video)
Before entering the kitchen, you watch hundreds of cooking videos on YouTube. You cannot cook yet, but you learn:
- How people hold a knife, hold a pot
- The sequence of operations: chop vegetables first, boil water before adding noodles
- Which object goes with which action (knife → cut, spoon → stir)
In Ψ₀, this stage uses EgoDex — a dataset of 829 hours of egocentric (first-person) video from public datasets like Ego4D, EpicKitchens, and HOI4D. The model learns to understand images and predict hand actions, but in a general form — not tied to any specific robot.
The key point: egocentric data is chosen deliberately because the viewpoint resembles the camera on a robot's head. This is why Ψ₀ does not use exocentric video (filmed from the outside) — the viewpoint difference would introduce noise.
Result: The model develops "intuition" about object manipulation, much like how watching enough YouTube gives you a rough idea of how to cook, even if you have never set foot in a kitchen.
Stage 2: Practicing in the Kitchen (Post-training on robot data)
Now you step into a real kitchen. You have 31 hours of practice (equivalent to 31 hours of teleoperation data on the Unitree G1 robot). You apply the knowledge from YouTube to reality, but must adjust because:
- Your hands (robot) are different from the chef's hands in the videos
- The real kitchen differs from the kitchens in the videos
- You need to learn to coordinate hands and legs
In Ψ₀, this stage fine-tunes the action expert on 31 hours of robot data — a surprisingly small amount. But because the model already has foundational knowledge from Stage 1, it can learn much faster than starting from scratch.
Result: The model knows how to control a specific robot (Unitree G1), but is not yet proficient at any specific task.
Stage 3: Mastering a Signature Dish (Fine-tuning with specific demos)
Finally, you want to cook one dish perfectly — say, pho. You need someone to cook it a few times while you watch (equivalent to 80 demonstrations per task). Since you already know how to cook in general, watching just a few times is enough to get it down.
In Ψ₀, this stage fine-tunes the model on just 80 demos per specific task (e.g., picking up a can, opening a drawer, wiping a table). The number 80 is remarkably small compared to the thousands of demos that other methods require.
Result: The model performs specific tasks with a high success rate — 82% on average, compared to 50% for GR00T N1 and 30% for Pi0.

Target Robot: Unitree G1 + Dex3-1
Ψ₀ was designed and validated on the Unitree G1 — a compact humanoid robot from China — paired with the dexterous Dex3-1 hand. The robot has a total of 43 degrees of freedom (DoF):
- 28 upper-body DoF: 2 arms (7-DoF each) + 2 Dex3-1 hands (7 actuated DoF each)
- 15 lower-body DoF: controlled via 8 velocity/direction commands by the RL controller
This division mirrors the three-system architecture exactly: System-1 generates commands for the 28 upper-body DoF, while System-0 receives 8 input commands and controls the 15 lower-body DoF.
What Will This Series Teach You?
Here is the roadmap for the entire Ψ₀ Hands-On series:
Part 1 (this article): Overview & Key Ideas
You are here. Understanding the problem, the ideas, and the architecture at the highest level.
Part 2: The Three-Tier Architecture in Detail
A deep-dive into each system: System-2 (VLM), System-1 (MM-DiT with Flow Matching), System-0 (RL Controller). You will understand exactly how data flows from camera to motor.
Part 3: EgoDex & the Data Pipeline
How the EgoDex dataset is built, how egocentric video is processed, and why the data recipe matters. You will process video data yourself.
Part 4: Pre-training the Action Expert
Training Stage 1 — from egocentric video to a model with "intuition." You will run actual pre-training code.
Part 5: Post-training & Fine-tuning
From a general model to a specialized one — training on robot data and fine-tuning for specific tasks.
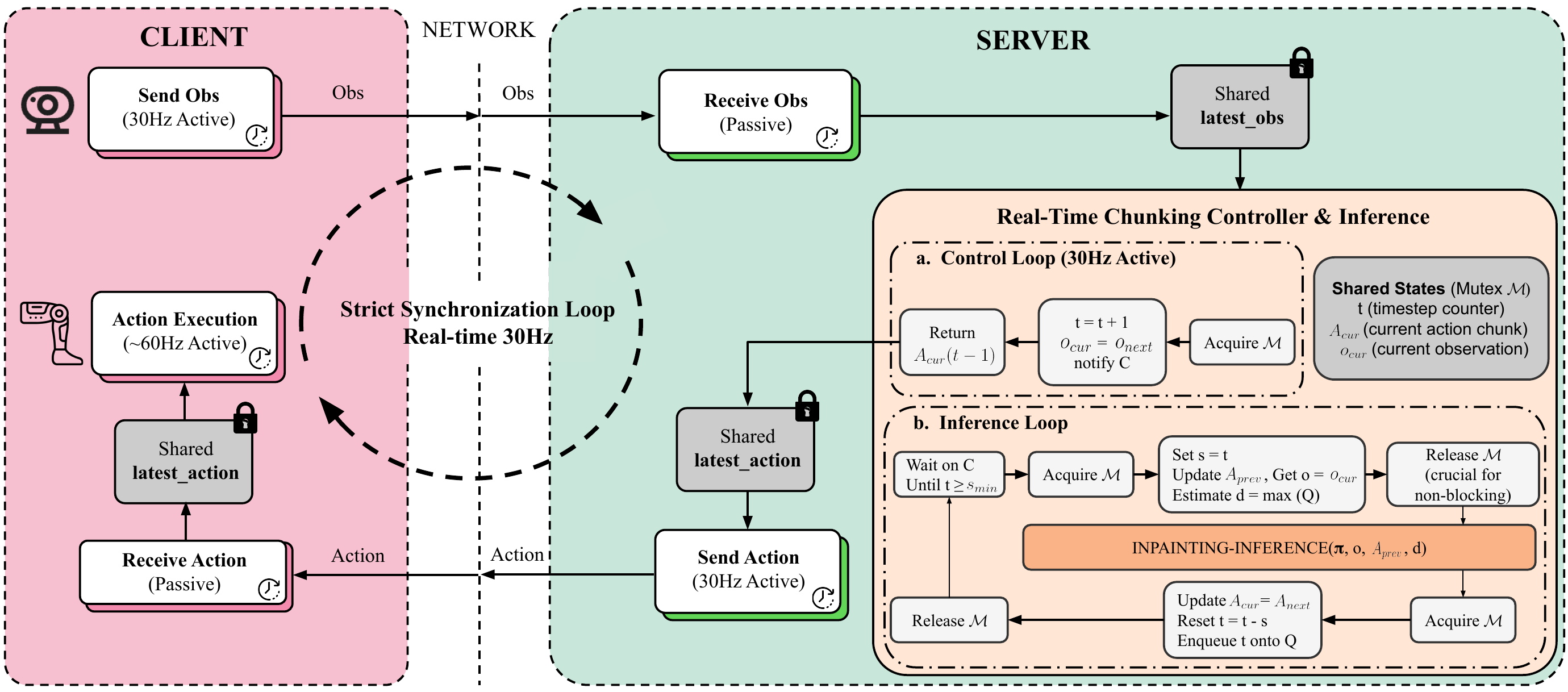
Part 6: Deployment & Real-Time Chunking
Deploying the model onto a real robot — handling 160ms latency, Real-Time Chunking, and practical tricks for running on real hardware.
What Do You Need to Prepare?
To follow along with this series, you will need:
Foundational Knowledge:
- Python — proficient, especially with PyTorch
- Basic Deep Learning — understanding of CNNs, Transformers, attention mechanisms
- Basic Reinforcement Learning — if unfamiliar, read our introduction to RL
- Diffusion Models — basic understanding of flow matching/diffusion (covered in detail in Part 2)
Hardware:
- A GPU with at least 24GB VRAM (RTX 4090 or A100) for training
- Inference can run on an 8GB GPU
Official Resources:
- Paper: Ψ₀: A Foundation Model for Humanoid Loco-Manipulation — Huang et al., USC PSI Lab + NVIDIA, 2026
- Code: github.com/physical-superintelligence-lab/Psi0
- Model weights: Available on HuggingFace (link in the GitHub repo)
- EgoDex dataset: Available on HuggingFace
Quick Comparison: Ψ₀ vs. Other Methods
To give you an overview of where Ψ₀ stands in the current research landscape:
| Ψ₀ | GR00T N1 | Pi0 | ACT | |
|---|---|---|---|---|
| Loco-manipulation | Yes | No | No | No |
| Robot data needed | 31h + 80 demo/task | ~300h+ | ~10,000h | ~50 demo/task |
| Pre-training data | 829h human video | In-house | In-house | None |
| Open-source | Yes | Partial | No | Yes |
| Avg. success rate | 82% | 50% | 30% | 45% |
| Latency | 160ms | ~200ms | ~100ms | ~50ms |
Note: Numbers are from the Ψ₀ paper on their benchmark. Results may differ on other benchmarks.
What stands out is that Ψ₀ is the only model in this table that truly tackles loco-manipulation — the others only handle manipulation on fixed robot arms or locomotion separately. This is an entirely new playing field where Ψ₀ is leading.
If you are interested in the broader landscape of AI for robotics, you can read our Embodied AI 2026 overview to see where Ψ₀ fits in the ecosystem.
Summary
Ψ₀ represents a significant leap in robotics for three reasons:
-
A novel approach: It decomposes the complex loco-manipulation problem into three specialized systems, each optimized independently.
-
Data efficiency: It demonstrates that how you organize data (staged training + egocentric video) matters more than sheer data volume.
-
Open-source: It releases all code, models, and data — enabling the community to build on this foundation.
In the next article, we will take a deep dive into the three-tier architecture — understanding exactly how each component works, from Qwen3-VL-2B (the brain) to MM-DiT Flow Matching (the hands) to the AMO RL Controller (the legs). You will see why each design decision was made and the tradeoffs behind them.
Related Articles
- VLA Models: When Robots Learn From Language and Vision — An overview of Vision-Language-Action models, the theoretical foundation that Ψ₀ builds upon.
- Loco-Manipulation for Humanoid Robots — The coordination of locomotion and manipulation — exactly the problem Ψ₀ solves.
- Reinforcement Learning Basics for Robotics — If you are unfamiliar with RL, this is a great starting point before exploring Ψ₀'s System-0.