From Classic Navigation to Learning-Based
In Part 1 and Part 2 of this series, we explored SLAM and Nav2 -- classical navigation methods based on geometric reasoning and hand-crafted planners. They work well in structured environments (factories, warehouses) but struggle when:
- Environment has no map and cannot be pre-mapped
- Complex, changing terrain (outdoors, off-road)
- Need to generalize to new robots and environments without retraining
Learning-based navigation approaches differently: instead of hand-coding rules, learn from data. Just like NLP has foundation models (GPT, BERT), robotics navigation is getting its own foundation models.
In this post, I'll analyze 3 landmark papers from BAIR (Berkeley AI Research) research group under Sergey Levine: GNM, ViNT, and NoMaD -- sequence of works shaping learning-based navigation.

GNM -- General Navigation Model (2022)
Paper: GNM: A General Navigation Model to Drive Any Robot (Shah et al., ICRA 2023)
Problem GNM Solves
Before GNM, each robot needed its own navigation policy. A policy trained on TurtleBot didn't work on Jackal, and vice versa. GNM asks: can we train 1 model that works on multiple different robots?
Approach
GNM is a goal-conditioned navigation policy trained on data from multiple robot types. Core ideas:
- Data aggregation: collect navigation data from 6 different robot types (Jackal, TurtleBot, Spot, drone, etc.), ~60 hours total
- Goal representation: use goal image -- picture of destination robot should reach
- Temporal context: instead of just current frame, GNM uses sequence of images (observation history) to understand motion
- Normalized action space: normalize action space (linear vel, angular vel) across robots with different sizes and kinematics
Architecture
Observation images (t-k, ..., t) → CNN Encoder → ┐
├→ MLP → (v, ω) actions
Goal image → CNN Encoder → ┘
└→ MLP → temporal distance
GNM has 2 outputs:
- Action: linear and angular velocity (v, omega) -- what robot should do next
- Temporal distance: estimate how many steps until reaching goal -- used for planning
Key Results
- Cross-robot transfer: model trained on 6 robots, deployed on unseen robot (even quadrotor!) without fine-tuning
- Positive transfer: model trained on diverse data performs better than single-robot model
- Robustness: GNM robust to sensor degradation (blurry camera, vibration) thanks to diverse training data
Limitations
- Only outputs 1 action (deterministic) -- cannot model multiple feasible paths
- No exploration ability -- only reaches known goals
- Not yet optimized for long-range navigation
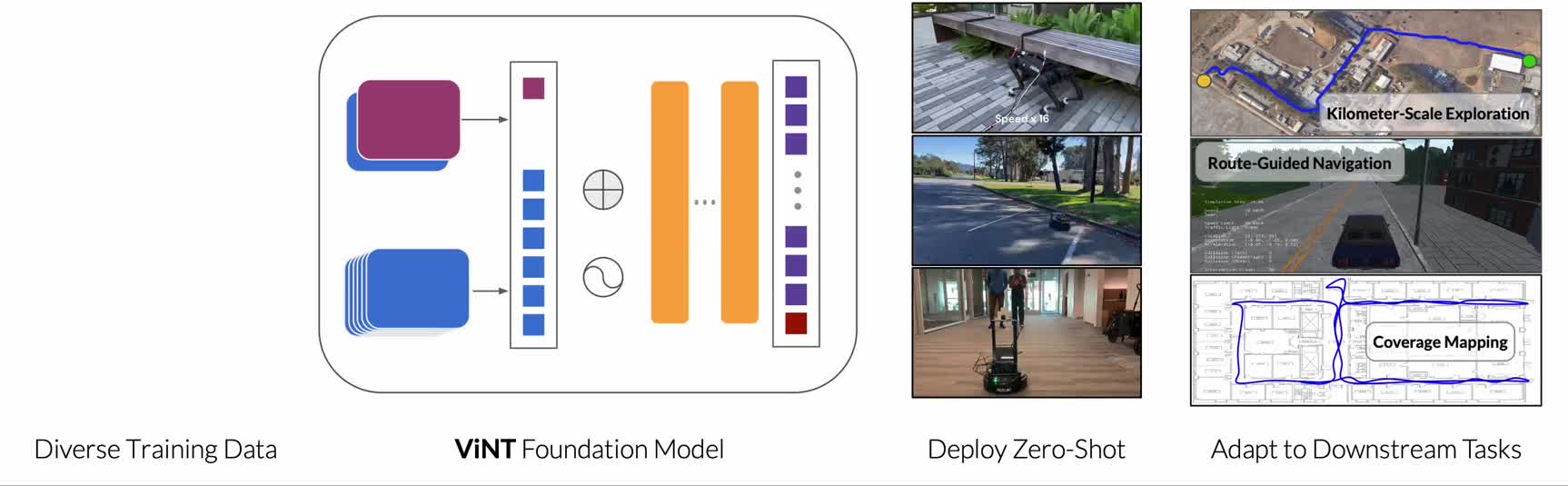
ViNT -- Visual Navigation Transformer (2023)
Paper: ViNT: A Foundation Model for Visual Navigation (Shah et al., CoRL 2023)
From GNM to ViNT
ViNT is evolution from GNM with 3 major improvements:
- Transformer architecture: replace CNN with EfficientNet + Transformer, allowing model to learn long-range dependencies in observation history
- Diffusion-based subgoal proposals: add exploration ability by generating subgoal images
- Massive dataset: train on much larger dataset -- hundreds of hours from many robots
ViNT Architecture
Observations (t-k, ..., t)
│
▼
EfficientNet Encoder (per frame)
│
▼
Transformer (cross-attention between frames)
│
├──→ Action Head → (v, ω) normalized actions
└──→ Distance Head → temporal distance to goal
Goal image → EfficientNet → Goal Token (inject into Transformer)
Difference from GNM:
- Transformer allows model to attend to important frames in history (e.g., frames with obstacles)
- Goal token injected into Transformer like prompt -- similar to prompt-tuning in NLP
Exploration with Diffusion Subgoals
Breakthrough feature of ViNT. When no goal image (robot needs to explore), ViNT uses diffusion model to generate subgoal images:
- Sample subgoal images from diffusion model (conditioned on current observation)
- Score each subgoal using ViNT distance head (choose most "feasible" subgoal)
- Navigate to selected subgoal
- Repeat -- creates frontier exploration behavior
This allows ViNT to explore novel environments without pre-built map -- something classical Nav2 cannot do.
Adaptation with Prompt-Tuning
ViNT can adapt to new tasks without full retraining:
- GPS waypoints: replace goal image with GPS encoding
- Routing commands: "turn left", "go straight" -- encode as goal token
- Only need to train new goal encoder (small), keep backbone frozen
Results
- Outperforms GNM on all benchmarks
- Navigate kilometer-scale with subgoal chaining
- Zero-shot transfer to 4 new robots (no fine-tune)
- Exploration behavior emerges from diffusion subgoals
NoMaD -- Goal Masked Diffusion Policies (2023)
Paper: NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration (Sridhar et al., ICRA 2024)
Problem NoMaD Solves
ViNT still has limitation: action output is deterministic (single action only). In reality, at a fork in the road, robot could turn left or right -- both valid. Deterministic policy outputs average of 2 directions, leading to walking straight into wall!
NoMaD solves this using diffusion model to generate actions -- can model multi-modal action distributions.
NoMaD Architecture
Observations (t-k, ..., t)
│
▼
ViT Encoder (Vision Transformer)
│
▼
Observation Token
│
├──→ Goal Masking Layer ← Goal image (or masked)
│
▼
Diffusion Decoder
│
▼
Action trajectory (sequence of future actions)
Goal Masking -- Unifying Navigation and Exploration
Core insight of NoMaD: goal masking. During training:
- 50% samples: provide goal image (goal-conditioned navigation)
- 50% samples: mask goal image (goal-agnostic exploration)
Single model learns both behaviors:
- With goal: navigate to goal
- Without goal: explore environment (visit new places)
# NoMaD pseudocode
def nomad_forward(observations, goal_image=None):
obs_token = vit_encoder(observations)
if goal_image is not None:
goal_token = vit_encoder(goal_image)
context = concat(obs_token, goal_token)
else:
# Mask goal -- exploration mode
context = concat(obs_token, mask_token)
# Diffusion generates multi-modal actions
action_trajectory = diffusion_decoder.sample(context)
return action_trajectory
Diffusion for Action Generation
Instead of single action, NoMaD generates trajectory (sequence of future actions) via diffusion:
- Start from noise (Gaussian random)
- Iteratively denoise conditioned on observation + goal context
- Output: trajectory with multiple steps (e.g., 8 future waypoints)
Advantages of diffusion:
- Multi-modal: can generate multiple feasible trajectories
- Smooth: trajectories naturally smooth, not jerky
- Flexible: easy to add constraints
Results
- Navigation: outperforms ViNT and GNM on real-world tests
- Exploration: explores efficiently (fewer collisions than ViNT)
- Smaller model: 70M parameters (smaller than ViNT) but more effective
- Real-time: runs on NVIDIA Jetson Orin
Comparing 3 Models
| Criterion | GNM | ViNT | NoMaD |
|---|---|---|---|
| Year | 2022 | 2023 | 2023 |
| Architecture | CNN + MLP | EfficientNet + Transformer | ViT + Diffusion |
| Action output | Single (v, omega) | Single (v, omega) | Trajectory (multi-modal) |
| Exploration | No | Yes (diffusion subgoals) | Yes (goal masking) |
| Cross-robot | 6 robots | More | More |
| Long-range | Limited | Km-scale | Km-scale |
| Real-time | Yes | Yes | Yes (Jetson Orin) |
| Training data | ~60h | Hundreds of hours | Hundreds of hours |
Evolution of Ideas
GNM (2022) ViNT (2023) NoMaD (2023)
───────── ────────── ──────────
CNN backbone → Transformer backbone → ViT backbone
Single action → Single action → Diffusion trajectory
No exploration → Diffusion subgoals → Goal masking
Basic dataset → Massive dataset → Same massive dataset

Real-World Applications and Limitations
When to Use Learning-Based Navigation?
Should use when:
- Environment is unstructured, cannot be pre-mapped (forest, outdoors)
- Need to generalize quickly to new robots
- Environment has many dynamic obstacles (people walking)
- Need exploration in unknown environments
Not yet ready when:
- Environment is structured, static map available (factory) -- Nav2 still better
- Need absolute safety guarantees (certified safety) -- learning-based doesn't provide
- Hardware constrained -- needs GPU (at least Jetson Orin)
Deploy on Real Robot
# Clone official codebase
git clone https://github.com/robodhruv/visualnav-transformer.git
cd visualnav-transformer
# Install
pip install -r requirements.txt
# Download pretrained checkpoint
# GNM, ViNT, NoMaD checkpoints available
# Run on robot
python deployment/deploy_nomad.py \
--model nomad \
--checkpoint checkpoints/nomad.pth \
--robot locobot # or jackal, turtlebot, custom
Hardware Requirements
- Minimum: NVIDIA Jetson Orin Nano (NoMaD runs ~10 Hz)
- Recommended: Jetson AGX Orin (NoMaD runs ~20 Hz)
- Camera: any RGB camera (RealSense, USB webcam)
Future Trends
Larger Foundation Models
Latest research scaling up navigation models:
- Train on more data: YouTube videos, driving datasets, indoor datasets
- Larger models: from 70M (NoMaD) to 300M+ parameters
- Multi-task: not just navigation but also manipulation, exploration
Combining with VLMs (Vision-Language Models)
Use natural language instead of goal image to direct robot: "go to kitchen" -- this is Vision-Language Navigation (VLN), topic of Part 4 in this series.
Sim-to-Real for Navigation
Train navigation policy in simulation then transfer to real robot -- combine GNM/ViNT backbone with simulated diverse environments.
Up Next in Series
This is Part 3 of Modern Navigation series:
- Part 1: SLAM A to Z -- SLAM Foundation
- Part 2: ROS 2 Nav2 -- Classical Navigation Stack
- Part 4: Vision-Language Navigation -- Language-Guided Navigation
- Part 5: Outdoor Navigation and Multi-Robot -- GPS-denied Nav, MAPF
Related Posts
- Foundation Models for Robots: RT-2, Octo, OpenVLA -- Foundation models for manipulation
- Sim-to-Real Transfer -- Train in simulation, run in reality
- AI Series Part 4: Diffusion Policy -- Diffusion models in robotics
- Edge AI with NVIDIA Jetson -- Deploy models to Jetson for real-time inference