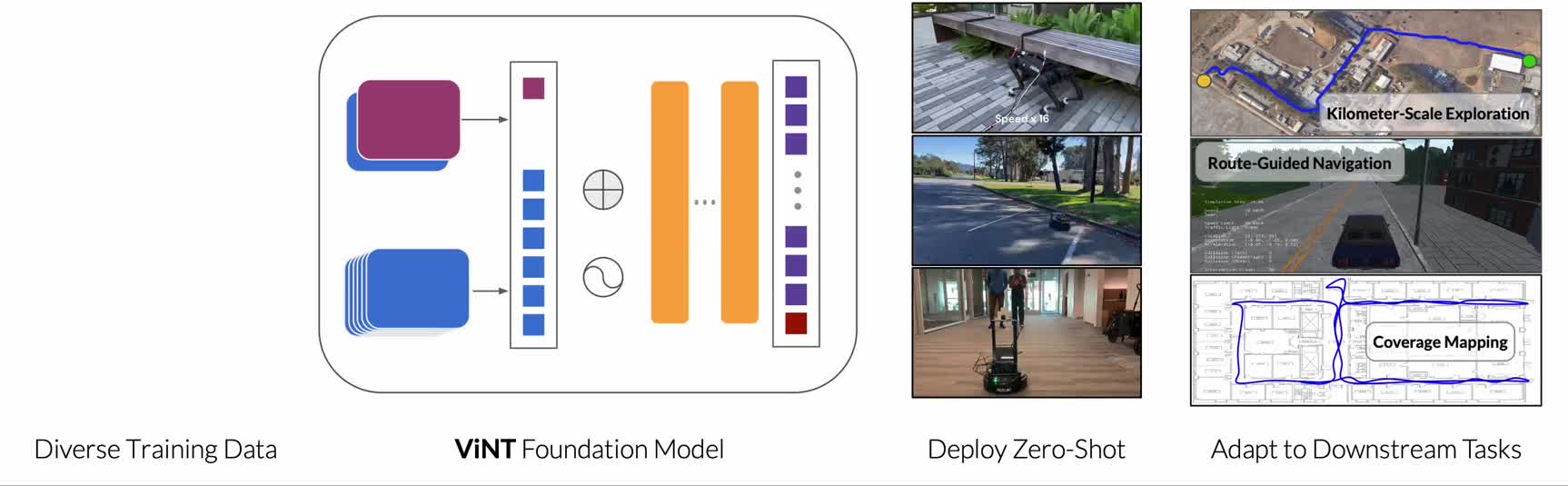
Từ goal image đến ngôn ngữ tự nhiên
Trong Part 3, chúng ta đã thấy cách GNM, ViNT, và NoMaD sử dụng goal image để chỉ dẫn robot: "hãy đến nơi trông như thế này". Nhưng trong thực tế, con người không giao tiếp bằng ảnh -- chúng ta nói: "đi đến phòng bếp", "rẽ trái ở ngã tư, rồi đi thẳng đến cuối hành lang".
Vision-Language Navigation (VLN) là bài toán robot hiểu và thực hiện chỉ dẫn bằng ngôn ngữ tự nhiên trong môi trường 3D. Đây là một trong những bài toán khó nhất tại giao điểm giữa NLP, Computer Vision, và Robotics.
Tại sao khó? Vì robot cần:
- Hiểu ngôn ngữ: parse chỉ dẫn phức tạp, hiểu tham chiếu ("cái bàn bên cạnh cửa sổ")
- Nhìn và nhận diện: match ngôn ngữ với những gì nhìn thấy (grounding)
- Ra quyết định: chọn hướng đi dựa trên hiểu biết về ngôn ngữ và visual
- Xử lý không chắc chắn: ngôn ngữ mơ hồ, môi trường không quen thuộc

Room-to-Room (R2R) -- Benchmark nền tảng
R2R Dataset
R2R (Anderson et al., CVPR 2018) là benchmark đầu tiên và quan trọng nhất cho VLN. Paper: Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments.
Setup:
- Môi trường: 90 buildings từ Matterport3D -- scan 3D của nhà thật, photorealistic
- Chỉ dẫn: 21,567 instructions, trung bình 29 từ, do người viết
- Task: agent bắt đầu tại một vị trí, đọc chỉ dẫn, đi đến đích
Ví dụ chỉ dẫn:
"Walk out of the bathroom. Turn left and walk down the hall. Turn left and wait in the doorway of the bedroom."
Metrics:
- Success Rate (SR): tỷ lệ đến đúng đích (< 3m)
- SPL (Success weighted by Path Length): SR * (shortest_path / actual_path) -- đánh giá hiệu quả đường đi
- nDTW: normalized Dynamic Time Warping -- đo mức "đi đúng đường" so với reference path
Navigation Graph
R2R sử dụng navigation graph -- tập hợp các viewpoints (nodes) được kết nối bởi edges. Tại mỗi bước, agent:
- Nhìn panorama 360 độ tại node hiện tại
- Chọn node tiếp theo để di chuyển (từ các neighbors)
- Lặp lại cho đến khi quyết định dừng lại
Đây là discrete navigation -- agent teleport giữa các nodes, không cần xử lý low-level control. Các benchmark mới (VLN-CE) chuyển sang continuous environments với low-level actions.
Các giai đoạn phát triển của VLN
Giai đoạn 1: Sequence-to-Sequence (2018-2020)
Các models đầu tiên xử lý VLN như bài toán seq2seq: encode chỉ dẫn thành vector, decode thành chuỗi actions.
Speaker-Follower (Fried et al., NeurIPS 2018):
- Follower: đọc chỉ dẫn, nhìn panorama, chọn action
- Speaker: nhìn trajectory, sinh chỉ dẫn -- dùng cho data augmentation
- Speaker generate chỉ dẫn mới cho các paths chưa có annotation -- tăng data gấp 10x
Giai đoạn 2: Transformer-based (2020-2023)
PREVALENT và HAMT (History Aware Multimodal Transformer) đưa Transformer vào VLN:
- Cross-attention giữa instruction tokens và visual features
- History encoding -- nhớ những gì đã thấy trước đó
- Pre-training trên image-text-action triplets
HAMT đạt SOTA trên R2R với 65% SR (2022), sử dụng hierarchical history encoding để xử lý long trajectories.
Giai đoạn 3: LLM-based Planning (2023-nay)
Sự bùng nổ của LLMs (GPT-4, LLaMA) mở ra hướng mới: sử dụng LLM như navigation planner.
LLM-based Navigation Planning
Ý tưởng chính
Thay vì train end-to-end model, dùng LLM làm "bộ não" suy luận:
Chỉ dẫn: "Đi đến phòng bếp, lấy cốc nước trên bàn"
│
▼
LLM (GPT-4V / LLaMA)
│
├── Hiểu chỉ dẫn: [đi đến phòng bếp] → [lấy cốc nước] → [trên bàn]
├── Nhìn ảnh hiện tại: "Tôi đang ở hành lang, phía trước có cửa"
├── Suy luận: "Phòng bếp thường có tủ lạnh, bếp -- chưa thấy → đi tiếp"
│
▼
Action: "Đi thẳng, qua cửa phía trước"
NavGPT và các công trình LLM-based
NavGPT (Zhou et al., 2023) là một trong những công trình đầu tiên dùng GPT-4 cho VLN:
- Perception module: mô tả scene hiện tại bằng text ("I see a hallway with a door on the left")
- LLM reasoning: GPT-4 đọc chỉ dẫn + scene description, suy luận action tiếp theo
- Action execution: chuyển LLM output thành navigation action
Điểm mạnh:
- Zero-shot: không cần train, chỉ cần prompt engineering
- Reasoning minh bạch: có thể đọc được suy luận của LLM (khác với neural network black box)
- Common sense: LLM biết "phòng bếp thường ở tầng 1", "toilet thường gần phòng ngủ"
Nhược điểm:
- Chậm: mỗi bước cần 1 LLM call (~1-2 giây với GPT-4)
- Hallucination: LLM có thể "tưởng tượng" thấy điều không có
- Cost: API calls đắt tiền cho real-time navigation
SayNav và Hierarchical Planning
SayNav tiếp cận theo hướng hierarchical: LLM tạo high-level plan, classic planner thực hiện:
LLM: "Để đến phòng bếp, tôi cần:
1. Ra khỏi phòng hiện tại
2. Đi dọc hành lang
3. Rẽ phải tại ngã tư
4. Phòng bếp ở cuối hành lang trái"
│
▼
Classical Planner (Nav2): thực hiện từng bước với obstacle avoidance
NaVILA -- Vision-Language-Action cho Legged Robots
Paper: NaVILA: Legged Robot Vision-Language-Action Model for Navigation (Cheng et al., RSS 2025)
NaVILA là công trình mới nhất, kết hợp VLA (Vision-Language-Action) model với locomotion skills cho legged robots (robot chân).
Kiến trúc 2 tầng
Tầng 1: VLA Model (low frequency ~2 Hz)
Input: camera image + language instruction
Output: mid-level command ("moving forward 75cm")
│
▼
Tầng 2: Locomotion Policy (high frequency ~50 Hz)
Input: mid-level command + proprioception
Output: joint torques
Tại sao 2 tầng?
- VLA model chạy chậm (inference ~0.5s) nhưng hiểu ngôn ngữ tốt
- Locomotion policy chạy nhanh, xử lý real-time obstacle avoidance
- Tách biệt cho phép mỗi tầng hoạt động ở tần số phù hợp
Kết quả
- 88% success rate trên 25 chỉ dẫn thực tế
- 75% success trên chỉ dẫn phức tạp (nhiều bước)
- Robot Unitree Go2 đi được trong môi trường cluttered (đầy đồ vật)
- Hiểu chỉ dẫn như "go to the kitchen and find the red cup on the counter"
So với NoMaD
| Tiêu chí | NoMaD | NaVILA |
|---|---|---|
| Input | Goal image | Language instruction |
| Robot | Wheeled | Legged (quadruped) |
| Architecture | ViT + Diffusion | VLA + RL locomotion |
| Speed | Fast (~20 Hz) | 2 Hz (VLA) + 50 Hz (locomotion) |
| Terrain | Flat | Rough terrain |
| Interaction | Image goal | Natural language |

VLN trong Continuous Environments
VLN-CE (Continuous Environments)
R2R sử dụng navigation graph (discrete). VLN-CE (Krantz et al., 2020) chuyển sang continuous environments -- robot phải tự điều khiển (linear + angular velocity), xử lý obstacle avoidance, và có thể đi lạc.
Khó hơn nhiều vì:
- Không có teleportation -- phải tự tránh vật cản
- Cumulative error -- sai số tích lũy theo thời gian
- Larger action space -- từ discrete choices sang continuous control
Embodied VLN
EmbodiedGPT và LEO (Large Embodied Model) là các công trình gần đây kết hợp:
- 3D scene understanding: hiểu không gian 3D từ depth/point cloud
- LLM reasoning: suy luận từ chỉ dẫn ngôn ngữ
- Continuous control: output trực tiếp velocity commands
Thách thức còn lại
1. Grounding -- Kết nối ngôn ngữ với visual
"Cái bàn bên cạnh cửa sổ" -- robot cần hiểu "bên cạnh" là spatial relation, "cửa sổ" là object, và match với những gì nhìn thấy. Đây là bài toán visual grounding, vẫn chưa được giải quyết hoàn toàn.
2. Ambiguity trong ngôn ngữ
"Đi đến phòng" -- phòng nào? "Rẽ ở ngã tư" -- ngã tư nào? Ngôn ngữ tự nhiên vốn mơ hồ. Robot cần học cách hỏi lại (ask for clarification) hoặc dùng common sense để suy luận.
3. Dynamic environments
Chỉ dẫn "đi qua hành lang" nhưng hành lang đang có người đi lại, xe đẩy hàng. Robot cần adapt real-time -- kết hợp VLN với reactive obstacle avoidance.
4. Long-horizon tasks
Chỉ dẫn dài ("đi đến phòng bếp, lấy cốc, đổ nước, mang đến bàn") cần robot nhớ đã làm gì và kế hoạch những gì còn lại. Đây là vấn đề memory và planning -- LLMs có thể giúp.
Thực hành: Bắt đầu với VLN
Option 1: R2R với Habitat Simulator
# Setup Habitat
pip install habitat-sim habitat-lab
# Clone VLN dataset
git clone https://github.com/peteanderson80/Matterport3DSimulator.git
# Download R2R data
python -c "from habitat.datasets.vln import download_r2r; download_r2r()"
Option 2: VLN-CE với Habitat 3.0
# Habitat 3.0 (continuous environments)
pip install habitat-sim==0.3.0 --extra-index-url https://aihabitat.org/pip
# VLN-CE dataset
python -m habitat.datasets.vln_ce.download
Option 3: Real robot với NaVILA
NaVILA codebase cho phép deploy trên Unitree Go2 hoặc robot tương tự. Cần:
- NVIDIA Jetson AGX Orin (hoặc GPU server)
- RGB camera (front-facing)
- Robot với locomotion controller
Tương lai của VLN
Multimodal Foundation Models
GPT-4o, Gemini 2.0, và các multimodal models đang làm mờ ranh giới giữa VLN và general AI. Tương lai, robot có thể:
- Hỏi lại khi chỉ dẫn không rõ
- Giải thích tại sao chọn đường này
- Học từ feedback: "không phải phòng đó, phòng bên cạnh"
Từ Navigation đến Manipulation
VLN hiện tại chỉ là di chuyển. Bước tiếp theo là di chuyển + thao tác: "đi đến phòng bếp và pha cà phê" -- cần kết hợp VLN với manipulation skills.
Tiếp theo trong series
Đây là Part 4 của series Navigation hiện đại:
- Part 1: SLAM từ A đến Z -- Nền tảng SLAM
- Part 2: ROS 2 Nav2 -- Navigation stack kinh điển
- Part 3: Learning-based Navigation: GNM, ViNT, NoMaD -- Foundation models
- Part 5: Outdoor Navigation và Multi-Robot -- GPS-denied nav, MAPF
Bài viết liên quan
- Foundation Models cho Robot: RT-2, Octo, OpenVLA -- VLA models cho manipulation
- AI Series Part 5: VLA Models -- Vision-Language-Action models tổng quan
- Learning-based Navigation: GNM, ViNT, NoMaD -- Foundation models cho navigation
- Humanoid Robotics Guide -- Robot hình người có thể dùng VLN