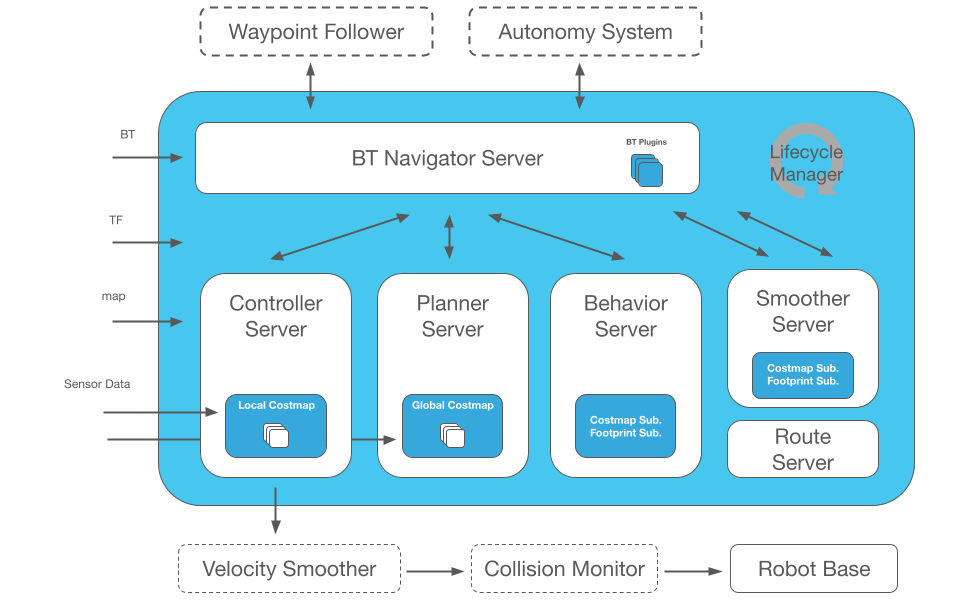
Từ classic navigation đến learning-based
Trong Part 1 và Part 2 của series này, chúng ta đã tìm hiểu SLAM và Nav2 -- những phương pháp navigation kinh điển dựa trên geometric reasoning và hand-crafted planners. Chúng hoạt động tốt trong môi trường có cấu trúc (nhà máy, kho hàng) nhưng gặp khó khăn khi:
- Môi trường không có bản đồ và không thể map trước
- Địa hình phức tạp, thay đổi (ngoài trời, off-road)
- Cần generalize sang robot và môi trường mới mà không retrain
Learning-based navigation tiếp cận vấn đề từ góc độ khác: thay vì hand-code rules, học từ data. Và giống như NLP đã có foundation models (GPT, BERT), robotics navigation cũng đang có foundation models của riêng mình.
Trong bài này, mình sẽ phân tích 3 công trình then chốt từ nhóm nghiên cứu BAIR (Berkeley AI Research) của Sergey Levine: GNM, ViNT, và NoMaD -- chuỗi công trình định hình hướng đi của learning-based navigation.

GNM -- General Navigation Model (2022)
Paper: GNM: A General Navigation Model to Drive Any Robot (Shah et al., ICRA 2023)
Vấn đề GNM giải quyết
Trước GNM, mỗi robot cần train riêng một navigation policy. Một policy train trên TurtleBot không chạy được trên Jackal, và ngược lại. GNM đặt câu hỏi: có thể train 1 model chạy được trên nhiều robot khác nhau không?
Cách tiếp cận
GNM là một goal-conditioned navigation policy được train trên dữ liệu từ nhiều loại robot khác nhau. Ý tưởng chính:
- Data aggregation: thu thập dữ liệu navigation từ 6 loại robot khác nhau (Jackal, TurtleBot, Spot, drone, v.v.), tổng cộng ~60 giờ
- Goal representation: sử dụng goal image -- ảnh của điểm đến mà robot cần tới
- Temporal context: thay vì chỉ dùng frame hiện tại, GNM sử dụng chuỗi ảnh (observation history) để hiểu motion
- Normalized action space: chuẩn hóa action space (linear vel, angular vel) giữa các robot có kích thước và kinematic khác nhau
Kiến trúc
Observation images (t-k, ..., t) → CNN Encoder → ┐
├→ MLP → (v, ω) actions
Goal image → CNN Encoder → ┘
└→ MLP → temporal distance
GNM có 2 outputs:
- Action: vận tốc tuyến tính và góc (v, omega) -- robot cần làm gì tiếp theo
- Temporal distance: ước lượng bao nhiêu bước nữa để tới goal -- dùng cho planning
Kết quả then chốt
- Cross-robot transfer: model train trên 6 robot, deploy trên robot chưa từng thấy (kể cả quadrotor!) mà không cần fine-tune
- Positive transfer: model train trên data đa dạng tốt hơn model chỉ train trên 1 robot
- Robustness: GNM robust với sensor degradation (camera bị mờ, rung) nhờ train trên dữ liệu đa dạng
Hạn chế
- Chỉ output 1 action (deterministic) -- không thể mô hình hóa nhiều cách đi khả thi
- Không có khả năng exploration -- chỉ đi đến goal đã biết
- Chưa tối ưu cho long-range navigation
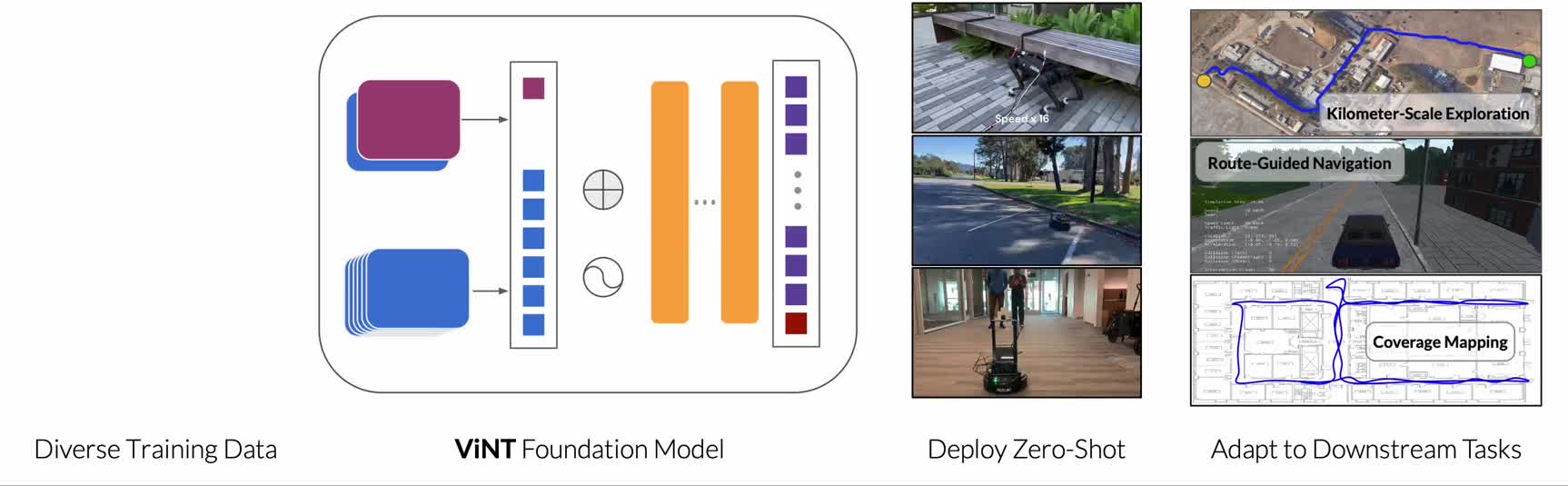
ViNT -- Visual Navigation Transformer (2023)
Paper: ViNT: A Foundation Model for Visual Navigation (Shah et al., CoRL 2023)
Từ GNM đến ViNT
ViNT là bước tiến hóa từ GNM, với 3 cải tiến lớn:
- Transformer architecture: thay CNN bằng EfficientNet + Transformer, cho phép model học long-range dependencies trong observation history
- Diffusion-based subgoal proposals: thêm khả năng exploration bằng cách generate subgoal images
- Massive dataset: train trên dataset lớn hơn nhiều -- hundreds of hours từ nhiều robot
Kiến trúc ViNT
Observations (t-k, ..., t)
│
▼
EfficientNet Encoder (per frame)
│
▼
Transformer (cross-attention giữa frames)
│
├──→ Action Head → (v, ω) normalized actions
└──→ Distance Head → temporal distance to goal
Goal image → EfficientNet → Goal Token (inject vào Transformer)
Điểm khác biệt với GNM:
- Transformer cho phép model attend đến các frame quan trọng trong history (ví dụ: frame có obstacle)
- Goal token được inject vào Transformer như một prompt -- tương tự prompt-tuning trong NLP
Exploration với Diffusion Subgoals
Đây là tính năng đột phá của ViNT. Khi không có goal image (robot cần explore), ViNT sử dụng diffusion model để generate subgoal images:
- Sample subgoal images từ diffusion model (conditioned on current observation)
- Score mỗi subgoal bằng ViNT distance head (chọn subgoal "khả thi" nhất)
- Navigate đến subgoal được chọn
- Repeat -- tạo frontier exploration behavior
Điều này cho phép ViNT explore novel environments mà không cần bản đồ trước -- điều mà Nav2 truyền thống không thể làm.
Adaptation với Prompt-Tuning
ViNT có thể adapt sang task mới mà không cần retrain toàn bộ model:
- GPS waypoints: thay goal image bằng GPS encoding
- Routing commands: "rẽ trái", "đi thẳng" -- encode thành goal token
- Chỉ cần train goal encoder mới (nhỏ), giữ nguyên backbone
Kết quả
- Vượt trội GNM trên mọi benchmark
- Navigate được kilometers-scale với subgoal chaining
- Zero-shot transfer sang 4 robot mới (không fine-tune)
- Exploration behavior emergent từ diffusion subgoals
NoMaD -- Goal Masked Diffusion Policies (2023)
Paper: NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration (Sridhar et al., ICRA 2024)
Vấn đề NoMaD giải quyết
ViNT vẫn có một hạn chế: action output là deterministic (1 action duy nhất). Trong thực tế, tại một ngã tư, robot có thể rẽ trái hoặc rẽ phải -- cả hai đều hợp lệ. Deterministic policy sẽ output trung bình của 2 hướng, dẫn đến đi thẳng vào tường!
NoMaD giải quyết bằng cách sử dụng diffusion model để generate actions -- có thể mô hình hóa multi-modal action distributions.
Kiến trúc NoMaD
Observations (t-k, ..., t)
│
▼
ViT Encoder (Vision Transformer)
│
▼
Observation Token
│
├──→ Goal Masking Layer ← Goal image (hoặc masked)
│
▼
Diffusion Decoder
│
▼
Action trajectory (sequence of future actions)
Goal Masking -- Thống nhất navigation và exploration
Ý tưởng then chốt của NoMaD: goal masking. Trong quá trình training:
- 50% samples: cung cấp goal image (goal-conditioned navigation)
- 50% samples: mask goal image (goal-agnostic exploration)
Một model duy nhất học cả 2 behaviors:
- Khi có goal: navigate đến goal
- Khi không có goal: explore môi trường (đi đến nơi chưa từng đến)
# NoMaD pseudocode
def nomad_forward(observations, goal_image=None):
obs_token = vit_encoder(observations)
if goal_image is not None:
goal_token = vit_encoder(goal_image)
context = concat(obs_token, goal_token)
else:
# Mask goal -- exploration mode
context = concat(obs_token, mask_token)
# Diffusion generates multi-modal actions
action_trajectory = diffusion_decoder.sample(context)
return action_trajectory
Diffusion cho action generation
Thay vì output 1 action, NoMaD generate trajectory (chuỗi actions tương lai) qua diffusion process:
- Bắt đầu từ noise (Gaussian random)
- Iteratively denoise conditioned on observation + goal context
- Output: trajectory có nhiều bước (ví dụ: 8 future waypoints)
Ưu điểm của diffusion:
- Multi-modal: có thể generate nhiều trajectory khả thi khác nhau
- Smooth: trajectory tự nhiên, không bị jerky
- Flexible: dễ dàng thêm constraints
Kết quả
- Navigation: vượt trội ViNT và GNM trên real-world tests
- Exploration: khám phá môi trường hiệu quả hơn ViNT (ít collision hơn)
- Model nhỏ hơn: 70M parameters (nhỏ hơn ViNT) mà hiệu quả hơn
- Real-time: chạy được trên NVIDIA Jetson Orin
So sánh 3 models
| Tiêu chí | GNM | ViNT | NoMaD |
|---|---|---|---|
| Năm | 2022 | 2023 | 2023 |
| Architecture | CNN + MLP | EfficientNet + Transformer | ViT + Diffusion |
| Action output | Single (v, omega) | Single (v, omega) | Trajectory (multi-modal) |
| Exploration | Không | Có (diffusion subgoals) | Có (goal masking) |
| Cross-robot | 6 robots | Nhiều hơn | Nhiều hơn |
| Long-range | Hạn chế | Km-scale | Km-scale |
| Real-time | Có | Có | Có (Jetson Orin) |
| Training data | ~60h | Hundreds of hours | Hundreds of hours |
Evolution của ý tưởng
GNM (2022) ViNT (2023) NoMaD (2023)
───────── ────────── ──────────
CNN backbone → Transformer backbone → ViT backbone
Single action → Single action → Diffusion trajectory
No exploration → Diffusion subgoals → Goal masking
Basic dataset → Massive dataset → Same massive dataset

Ứng dụng thực tế và hạn chế
Khi nào dùng learning-based navigation?
Nên dùng khi:
- Môi trường không có cấu trúc, không thể map trước (rừng, ngoài trời)
- Cần generalize nhanh sang robot mới
- Môi trường có nhiều dynamic obstacles (người đi lại)
- Cần exploration trong môi trường chưa biết
Chưa nên dùng khi:
- Môi trường có cấu trúc, bản đồ cố định (nhà máy) -- Nav2 vẫn tốt hơn
- Cần đảm bảo an toàn tuyệt đối (certified safety) -- learning-based không cung cấp độ chính xác safety guarantee
- Hardware hạn chế -- cần GPU (ít nhất Jetson Orin)
Deploy trên robot thật
# Clone official codebase
git clone https://github.com/robodhruv/visualnav-transformer.git
cd visualnav-transformer
# Install
pip install -r requirements.txt
# Download pretrained checkpoint
# GNM, ViNT, NoMaD checkpoints có sẵn
# Run trên robot
python deployment/deploy_nomad.py \
--model nomad \
--checkpoint checkpoints/nomad.pth \
--robot locobot # hoặc jackal, turtlebot, custom
Hardware requirements
- Minimum: NVIDIA Jetson Orin Nano (NoMaD chạy ~10 Hz)
- Recommended: Jetson AGX Orin (NoMaD chạy ~20 Hz)
- Camera: bất kỳ RGB camera (RealSense, USB webcam)
Xu hướng tiếp theo
Foundation models lớn hơn
Các nghiên cứu mới nhất đang scale up navigation models:
- Train trên nhiều data hơn: YouTube videos, driving datasets, indoor datasets
- Larger models: từ 70M (NoMaD) lên 300M+ parameters
- Multi-task: không chỉ navigation mà còn manipulation, exploration
Kết hợp với VLMs (Vision-Language Models)
Thay vì goal image, dùng ngôn ngữ tự nhiên để chỉ dẫn robot: "đi đến phòng bếp" -- đây là Vision-Language Navigation (VLN), chủ đề của Part 4 trong series này.
Sim-to-real cho navigation
Train navigation policy trong simulation rồi transfer sang robot thật -- kết hợp GNM/ViNT backbone với simulated diverse environments.
Tiếp theo trong series
Đây là Part 3 của series Navigation hiện đại:
- Part 1: SLAM từ A đến Z -- Nền tảng SLAM
- Part 2: ROS 2 Nav2 -- Navigation stack kinh điển
- Part 4: Vision-Language Navigation -- Robot đi theo chỉ dẫn ngôn ngữ
- Part 5: Outdoor Navigation và Multi-Robot -- GPS-denied nav, MAPF
Bài viết liên quan
- Foundation Models cho Robot: RT-2, Octo, OpenVLA -- Foundation models cho manipulation
- Sim-to-Real Transfer -- Train trong simulation, chạy ngoài thực tế
- AI Series Part 4: Diffusion Policy -- Diffusion models trong robotics
- Edge AI với NVIDIA Jetson -- Deploy models lên Jetson cho real-time inference