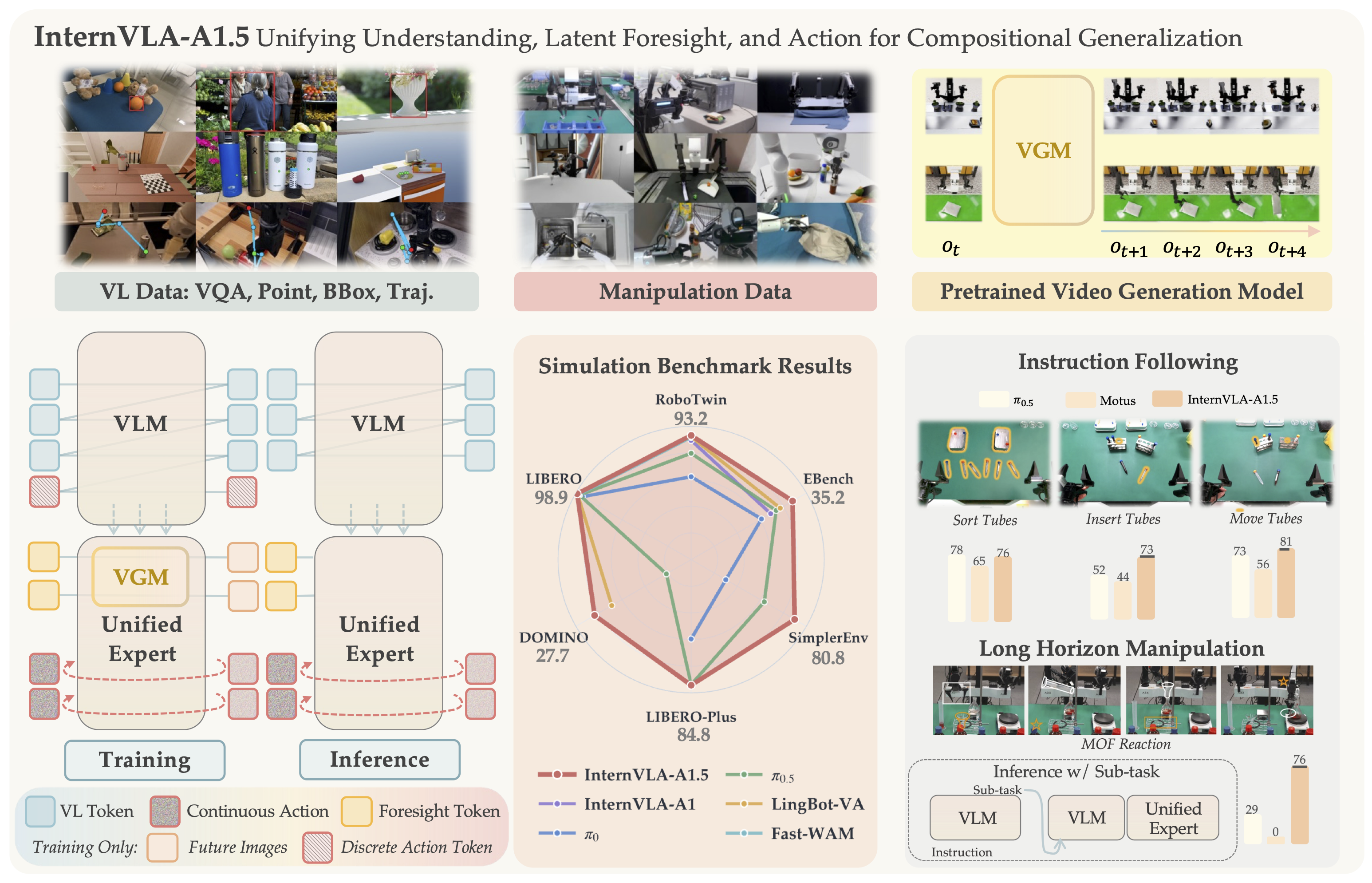
Most VLA frameworks today — including well-known ones like π₀ and GR00T — share a common weakness: they control each body part independently rather than modeling the coordinated whole-body motion a real human uses. The result is a robot that can move its arms skillfully but stumbles when it needs to walk, reach, and maintain balance simultaneously.
HEX (Humanoid-Aligned Experts for Cross-Embodiment Whole-Body Manipulation) is the first VLA framework designed from the ground up to solve exactly this — achieving 79.8% success rate across 7 real-world tasks, beating both π₀.₅ (71.8%) and GR00T N1.5 (70.2%).
The Problem HEX Solves
Imagine teaching a humanoid to carry a box from a conveyor belt to a shelf. The task requires:
- Both hands gripping and holding the box
- Torso adjusting for balance
- Legs stepping forward simultaneously
- Eyes tracking the shelf location
If the VLA model predicts actions for each joint independently, the robot will never learn this coordination. It needs a common language to describe the whole body — whether the robot is a Unitree G1, a Tienkung 2.0, or any other embodiment.
This is why HEX was built around two core innovations:
- Canonical body-part state representation — encoding body state into standardized "slots" instead of raw joint indices
- Mixture-of-Experts Unified Proprioceptive Predictor (UPP) — learning whole-body coordination from data across 7 different embodiments
HEX Architecture
┌─────────────────────────────────────────────────────────────┐
│ HEX Pipeline │
│ │
│ Camera frames ──► VLM (Qwen3-VL-2B) │
│ + Text command │ Temporal context cache │
│ ▼ │
│ Visual-Language Features │
│ │ │
│ Robot joints ──► UPP (MoE Transformer) │
│ (canonical slots) │ 16 routed experts + 2 shared │
│ ▼ │
│ Proprioceptive Features │
│ │ │
│ ┌───────┴───────┐ │
│ ▼ ▼ │
│ Action Expert (DiT-B, 16 layers) │
│ dual cross-attention fusion │
│ │ │
│ ▼ │
│ Action (flow-matching) │
└─────────────────────────────────────────────────────────────┘
1. Visual-Language Backbone: Qwen3-VL-2B
HEX uses Qwen3-VL-2B-Instruct as its vision-language backbone. The key addition is a lightweight history query feature cache — rather than feeding the full video stream into the model, HEX compresses temporal history into a compact context vector. This gives the model a sense of "what happened recently" without the memory cost of full video encoding.
2. Canonical State Representation
This is arguably HEX's most important contribution. Different robots have different joint structures (Unitree G1 has 43 DOF, Tienkung 3.0 has more), making it impossible to use raw joint indices for cross-embodiment learning.
HEX defines 7 standardized body-part slots:
| Slot | Description | Example joints |
|---|---|---|
left_arm |
Left arm | shoulder, elbow, wrist |
right_arm |
Right arm | shoulder, elbow, wrist |
left_hand |
Left hand (dexterous) | finger joints |
right_hand |
Right hand (dexterous) | finger joints |
legs |
Both legs | hip, knee, ankle |
head |
Head + neck | pan, tilt |
waist |
Torso | rotation joints |
If a robot lacks a body part (e.g., a wheeled robot without legs), HEX fills those slots with learned missing-part tokens — the model handles it gracefully without any special-case logic.
3. UPP — Unified Proprioceptive Predictor
UPP is the core of HEX. It is a 4-layer transformer (hidden size 768) with a Mixture-of-Experts architecture:
Input: canonical body-part embeddings
↓
MoE Layer × 4:
- 16 routed experts (embodiment-specific patterns)
- 2 shared experts (cross-embodiment common dynamics)
- Router selects top-K experts per token
↓
Output: temporal + whole-body coordination features
The idea: 16 "specialist" experts learn patterns specific to each robot's morphology, while 2 shared experts learn universal principles of balance and whole-body coordination. When deploying to a new robot, the router combines the right mix of experts.
4. Action Expert: DiT-B with Dual Cross-Attention
HEX's action head is a 16-layer DiT-B (Diffusion Transformer Base, hidden size 1024) with a dual cross-attention architecture:
# Simplified dual cross-attention in HEX Action Expert
class DualCrossAttention(nn.Module):
def forward(self, action_tokens, vl_features, prop_features):
# Branch 1: attend to visual-language context
x_vl = self.cross_attn_vl(action_tokens, vl_features)
# Branch 2: attend to proprioceptive context
x_prop = self.cross_attn_prop(action_tokens, prop_features)
# Adaptive fusion gate
alpha = self.gate(action_tokens)
return alpha * x_vl + (1 - alpha) * x_prop
Training uses flow-matching instead of standard diffusion — faster, more stable, and especially suited to tasks requiring fast reaction times.
Dataset and Training Data
HEX is pretrained on over 12 million frames from 4 data sources:
| Source | Type | Embodiments | Notes |
|---|---|---|---|
| HEX in-house dataset | Real-world | Tienkung, Tienyi | Diverse manipulation |
| Humanoid Everyday | Real-world | Multiple | Daily household tasks |
| AgiBot World Colosseo | Real-world | AgiBot | Wheeled humanoid |
| RoboCOIN | Real-world | Leju, G1, H1 | Multi-embodiment |
7 embodiments in total: Tienkung 2.0, Tienkung 3.0, Tienyi, Unitree G1, Unitree H1, AgiBot, Leju Kuavo.
Installation
System Requirements
- Ubuntu 20.04/22.04 + CUDA 11.8+
- GPU: at least 1× A100 40GB for inference, 8× A100 for fine-tuning
- Python 3.10
- RAM: 32GB+
Step 1: Clone and set up environment
git clone https://github.com/Open-X-Humanoid/HEX.git
cd HEX
conda create -n hex python=3.10 -y
conda activate hex
# System dependencies
sudo apt update && sudo apt install -y libegl1-mesa-dev libglu1-mesa
# Python dependencies
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
pip install -e .
Step 2: Download model weights
# Download HEX pretrained model (~2.4B params)
python hex/utils/download_model_hex.py
# Download base VLM (Qwen3-VL-2B)
python hex/utils/download_model_qwen.py
Both are hosted on Hugging Face. For slow connections, use hf_transfer:
pip install hf_transfer
HF_HUB_ENABLE_HF_TRANSFER=1 python hex/utils/download_model_hex.py
Step 3: Verify the install
# Run quick test in LIBERO simulation
bash scripts/libero/eval_libero.sh
# Or run the inference notebook
jupyter notebook notebooks/eval_model.ipynb
Fine-tuning HEX on Your Robot
If you have tele-op data from a real robot, fine-tuning takes two steps.
Step 1: Prepare your data
HEX uses LeRobot v2.1 format. If you already have a LeRobot dataset, you just need to map your joint names to canonical slots:
# configs/embodiment/unitree_g1.yaml
embodiment: unitree_g1
joint_mapping:
left_arm: [left_shoulder_pitch, left_shoulder_roll, left_shoulder_yaw,
left_elbow, left_wrist_roll, left_wrist_pitch, left_wrist_yaw]
right_arm: [right_shoulder_pitch, right_shoulder_roll, right_shoulder_yaw,
right_elbow, right_wrist_roll, right_wrist_pitch, right_wrist_yaw]
legs: [left_hip_pitch, left_hip_roll, left_hip_yaw,
left_knee, left_ankle_pitch, left_ankle_roll,
right_hip_pitch, right_hip_roll, right_hip_yaw,
right_knee, right_ankle_pitch, right_ankle_roll]
waist: [torso_joint]
# G1 has no dexterous hands → missing-part tokens fill automatically
Step 2: Run fine-tuning
# Fine-tune on your embodiment (2-4 A100s, ~6-12 hours)
bash scripts/fine_tune_hex.sh \
--embodiment unitree_g1 \
--data_path /path/to/your/lerobot_dataset \
--output_dir checkpoints/hex_g1_custom \
--num_epochs 50 \
--batch_size 8
# Full pretraining from scratch (~1000 A100 GPU-hours)
bash scripts/pretrain_hex.sh
Compute note: Full pretraining requires ~1000 A100 GPU-hours (200k steps, batch 16). With a limited budget, just fine-tune from the pretrained checkpoint — typically 6-12 hours on 2-4 A100s is enough for convergence.
Running Inference on a Real Robot
After fine-tuning, the inference loop looks like this:
from hex import HEXPolicy
from hex.utils import load_embodiment_config
# Load policy
policy = HEXPolicy.from_pretrained("checkpoints/hex_g1_custom")
config = load_embodiment_config("unitree_g1")
policy.set_embodiment(config)
policy.eval().cuda()
# Inference loop
obs = {
"image": camera_frame, # (H, W, 3) numpy array
"language": "pick up the bottle and place it on the shelf",
"joint_positions": robot.get_joint_positions(), # canonical slots
"joint_velocities": robot.get_joint_velocities()
}
with torch.no_grad():
actions = policy.predict(obs, num_steps=10) # predict 10-step chunk
# Execute
for action in actions:
robot.set_joint_targets(action)
Benchmark Results
HEX was evaluated on 7 real-world tasks ranging from simple pick-and-place to long-horizon multi-stage manipulation.
Overall comparison (seen scenarios)
| Model | Avg. Success Rate | Params | Method |
|---|---|---|---|
| HEX | 79.8% | 2.4B | MoE + DiT flow-matching |
| π₀.₅ | 71.8% | ~3B | Diffusion VLA |
| GR00T N1.5 | 70.2% | ~1.5B | DiT VLA |
| GR00T N1 | 52.4% | ~1.5B | DiT VLA |
Long-horizon task: Box Conveyance (4 stages)
This is particularly demanding: the robot must complete 4 sequential stages (approach → grasp → transport → place). Final-stage success rate:
HEX: 53.3% ████████████████████████████░░░░░░░░░░
π₀.₅: 40.0% ████████████████████░░░░░░░░░░░░░░░░░░
GR00T N1.5: 20.0% ██████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░
Generalization to unseen task variants
| Model | Unseen Success Rate |
|---|---|
| HEX | 61.8% |
| π₀.₅ | 44.3% |
| GR00T N1.5 | 41.0% |
The largest gap appears on fast-reaction tasks and long-horizon tasks — exactly the scenarios UPP's temporal dynamics modeling was designed for.
The Review-and-Forecast Mechanism
One of HEX's more subtle innovations is the review-and-forecast paradigm:
Past frames → Visual History Summary (review)
↓
VLM processes context
↓
Future state prediction ← UPP forecasts next body state (forecast)
↓
Action Expert generates actions
conditioned on predicted future state
Instead of only reacting to the current observation, HEX also predicts what the robot's body state will be after executing the action. This auxiliary loss forces UPP to learn genuine temporal dynamics — not just a frame-to-action mapping.
When to Use HEX
HEX is best suited when:
- ✅ You have a full-size humanoid robot (bipedal or wheeled)
- ✅ Tasks require simultaneous arms + legs + torso coordination
- ✅ You want one pretrained model fine-tuned across multiple embodiments
- ✅ Tasks are long-horizon (multiple sequential stages)
Less suitable when:
- ❌ Your robot is arm-only (no whole-body needed)
- ❌ You are resource-constrained: inference needs at least 1× A100 40GB
- ❌ You need real-time < 20ms (flow-matching has non-trivial latency)
For more context on the whole-body VLA ecosystem, see deploying WholebodyVLA on G1 and LeRobot + G1 + π₀Fast whole-body pipeline.
Related Posts
- WholebodyVLA ICLR 2026: Unified Latent VLA for Loco-Manipulation — Deep analysis of WholebodyVLA, the closest architectural peer to HEX
- GR00T N1 on G1: Architecture and Real-World Deploy — NVIDIA's GR00T N1 in detail — one of the main baselines HEX outperforms
- LeRobot + G1 + π₀Fast: Whole-Body Control End-to-End — Full practical pipeline using LeRobot v2.1, the same data format HEX uses