Why VLA Models Need to Understand 3D
In previous post on Foundation Models for Robot, we analyzed RT-2, Octo, and OpenVLA — powerful VLA models that can take camera image + language instruction and output robot actions. However, all share one limitation: they process the world as flat 2D images.
Imagine telling robot "place cup on top shelf". Robot sees cup and shelf through camera — but from 2D image, doesn't know how far away shelf is, how heavy cup is relative to distance it needs to travel, or how much gripper needs to tilt to avoid hitting shelf below.
Core problem: Depth ambiguity. Object close to camera but small looks identical to object far away but large in 2D image. Without depth information, robot must "guess" — and in manipulation, guessing wrong by 2cm completely fails task.

Experimental Evidence
Benchmarks show when changing spatial layout (moving object to new position, changing shelf height), success rate of OpenVLA and policies without depth information drops below 50% — while humans barely affected. Shows 2D VLA models missing crucial component: spatial reasoning.
Situations where 2D VLA struggles:
| Situation | 2D Problem | Needs 3D |
|---|---|---|
| Stack objects | Don't know exact heights | Depth for each object |
| Place on shelf | Don't know distance to shelf | 3D target position |
| Avoid obstacles | Don't know if obstacle ahead or behind | Full spatial context |
| Precise insertion | mm-level error from 2D projection | 3D alignment |
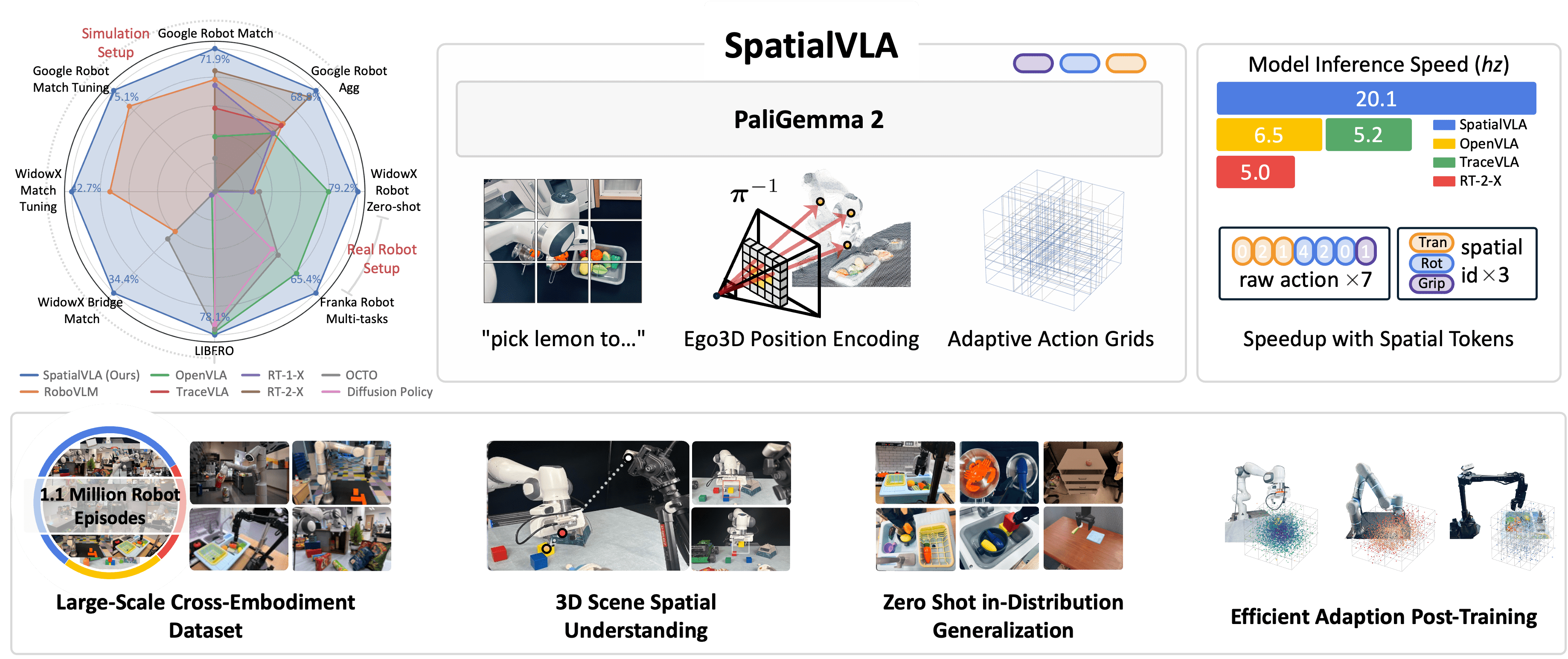
SpatialVLA: Architecture and Innovation
SpatialVLA (Qu et al., 2025, accepted at RSS 2025) solves this with two key innovations: Ego3D Position Encoding and Adaptive Action Grids. Trained on 1.1 million real-world robot episodes — significantly larger than Open X-Embodiment dataset (970K) that OpenVLA uses.
Ego3D Position Encoding — Viewing World Through Depth
Core idea: instead of just 2D positional encoding for image patches (traditional ViT), SpatialVLA adds 3D position information estimated from monocular depth.
Pipeline:
RGB Image (from robot camera)
↓
Monocular Depth Estimator (e.g., DPT/Depth Anything)
↓
Depth Map → 3D Point Cloud (in egocentric frame)
↓
Ego3D Position Encoding
↓
Fused with Visual Tokens in VLM backbone
Why "Egocentric"? Instead of using world coordinate frame (needs precise camera-robot calibration), SpatialVLA represents everything in camera frame — egocentric. Two major benefits:
- No camera-robot calibration needed — deploying on new robot requires no accurate extrinsic parameters
- Universally applicable — works with any robot embodiment as long as it has camera
Specifically, image patch at pixel (u, v) with depth d maps to 3D coordinate:
X = (u - cx) * d / fx
Y = (v - cy) * d / fy
Z = d
Ego3D_pos = MLP([X, Y, Z]) → positional embedding
Where (fx, fy, cx, cy) are camera intrinsics. This embedding added to visual tokens before transformer backbone, lets model "see" depth without changing architecture.
Adaptive Action Grids — Unifying Action Space
Second problem: each robot has different action space — Franka uses 7D joint positions, WidowX uses 6D end-effector velocity, ALOHA uses 14D bimanual actions. OpenVLA handles by tokenizing each dimension into 256 bins — but wastes resolution in rarely-used ranges.
Adaptive Action Grids solves by:
- Analyze statistical distribution of actions across entire dataset per robot
- Discretize actions into adaptive grids — more bins in frequently-used range, fewer bins in rare range
- Align action tokens with 3D spatial structure — action grids reflect spatial meaning
# Simplified example: Adaptive binning
import numpy as np
def adaptive_grid(actions, n_bins=256):
"""
Create adaptive bins based on actual distribution
instead of uniform bins
"""
# actions: shape (N, 7) — N episodes, 7 action dimensions
bins_per_dim = []
for dim in range(actions.shape[1]):
# Use quantiles instead of linspace
percentiles = np.linspace(0, 100, n_bins + 1)
bins = np.percentile(actions[:, dim], percentiles)
bins_per_dim.append(bins)
return bins_per_dim
# Uniform: bins evenly spaced from -1 to 1
# Adaptive: bins dense in action-heavy region (near workspace center)
# sparse in rare region (workspace boundary)
Result: higher action resolution where it matters without increasing total tokens.

Results: SpatialVLA vs OpenVLA
SpatialVLA evaluated on 7 robot learning scenarios, 16 real-robot tasks, 48 simulation setups. Results show clear advantage, especially for spatial reasoning tasks.
Real-world Franka Manipulation
| Task | OpenVLA | Octo | SpatialVLA |
|---|---|---|---|
| Pick spatial prompt (left/right/front/back) | < 50% | < 50% | 73% |
| Stack with height awareness | ~40% | ~35% | 68% |
| Place at specific location | ~45% | ~42% | 71% |
Zero-shot WidowX (out-of-distribution)
Harshest test — SpatialVLA never saw this specific WidowX robot layout:
- OpenVLA and Octo: consistently below 50% when spatial layout changes
- SpatialVLA: maintains 60-70% success rate thanks to 3D understanding
Inference Speed
SpatialVLA also improves inference speed via compact action representation:
| Model | Tokens per action | Inference (Hz) |
|---|---|---|
| OpenVLA | 7 tokens (7D) | ~6 Hz |
| Octo-Base | Diffusion steps | ~10 Hz |
| SpatialVLA | Fewer spatial tokens | ~8 Hz |
3D Representations in Robotics: The Big Picture
SpatialVLA uses monocular depth — simplest way to get 3D information. But just one part of broader landscape of 3D representations for robot perception.
Point Clouds
How it works: LiDAR or stereo camera creates 3D point set (x, y, z) for each surface in scene.
Advantages: Precise, explicit geometry, fast processing with PointNet/PointNet++.
Disadvantages: Sparse (no continuous surface info), no appearance/texture.
Applications: Grasping (Contact-GraspNet), navigation, bin picking in industry.
Neural Radiance Fields (NeRF)
How it works: Train neural network representing scene as continuous volumetric function — for any point (x, y, z) and viewing direction, outputs color and density.
Advantages: Photo-realistic novel view synthesis, smooth surfaces, compact representation.
Disadvantages: Slow training (minutes-hours), slow inference (seconds per render), hard to update real-time.
Applications in robotics: Scene understanding, sim-to-real transfer — use NeRF to create photorealistic training environments.
3D Gaussian Splatting (3DGS)
How it works: Represent scene as collection of 3D Gaussians, each with position, covariance, opacity and spherical harmonics coefficients for color. Render via differentiable rasterization instead of ray marching.
Advantages: Real-time rendering (100+ FPS), faster training than NeRF (minutes vs hours), explicit representation easy to manipulate.
Disadvantages: Memory-intensive (millions of Gaussians), not as smooth as NeRF.
Latest applications in robotics:
- RoboSplat (RSS 2025): Use 3DGS to generate novel demos for policy learning — create diverse training data from few demonstrations
- POGS (ICRA 2025): Track and manipulate irregular objects using Persistent Object Gaussian Splat
- SplatSim: Zero-shot sim-to-real transfer for RGB manipulation policies
Comprehensive Comparison
| Representation | Training | Rendering | Explicit? | Real-time? | Robot-friendly? |
|---|---|---|---|---|---|
| Point Cloud | N/A | N/A | Yes | Yes | High |
| NeRF | Slow (hours) | Slow (sec) | No | No | Medium |
| 3DGS | Fast (min) | Real-time | Yes | Yes | High |
| Monocular Depth | Pre-trained | Real-time | Yes | Yes | Highest |
SpatialVLA chose monocular depth because needs no extra hardware (LiDAR, stereo camera) and runs real-time — best fit for general-purpose VLA model.
Future: VLA + 3D Scene Understanding
SpatialVLA opens research direction combining VLA with deeper 3D understanding:
Short-term (2026-2027)
- Multi-view VLA: Instead of 1 camera, use multiple cameras or wrist + head camera to build richer 3D representation. Some labs already experimenting with stereo VLA.
- Better depth foundation models: Depth Anything V2 and metric depth models improving fast — SpatialVLA benefits directly.
- Tactile + 3D: Combine touch sensing with 3D vision for fine manipulation (assembly, soft object handling).
Medium-term (2027-2028)
- VLA + 3DGS real-time: Use Gaussian Splatting as world model for VLA — robot "imagines" action outcome before executing.
- 4D understanding: Not just 3D static but understand dynamics — how object moves when pushed, how liquid flows.
Long-term Vision
- Embodied 3D foundation model: Single model deeply understanding 3D world — can plan, manipulate, navigate, reason about physics — not just map pixel to action.
This among most exciting research directions in robot learning right now. SpatialVLA important first step — proves 3D spatial information measurably improves VLA models on real robots.
Takeaway for Practitioners
If building robot manipulation system:
- Using OpenVLA/Octo: Consider adding depth estimation to input pipeline — even simple monocular depth helps.
- Task needs spatial precision: SpatialVLA or similar should be first choice. Fine-tune on your robot data gives best results.
- Hardware: No LiDAR or stereo camera needed — monocular depth from pre-trained model sufficient for most manipulation.
- Next step: Watch SpatialVLA GitHub for weights and fine-tuning code when released.
Next article: hands-on tutorial fine-tune OpenVLA with LeRobot — from recording data to deploying on real robot.
Related Posts
- Foundation Models for Robot: RT-2, Octo, OpenVLA in Practice — VLA models overview
- Hands-on: Fine-tune OpenVLA with LeRobot — Tutorial: fine-tune VLA model
- Sim-to-Real Transfer: Train in Simulation, Run on Real Robot — Transfer models from sim to real
- Robotics Research Trends 2025 — Research landscape overview