Hồi đầu năm 2026, giữa lúc các tập đoàn công nghệ lớn đang chạy đua phát triển robot thương mại, Xiaomi lặng lặng công bố một thứ bất ngờ: Xiaomi-Robotics-0 — một VLA (Vision-Language-Action) model 4.7 tỷ tham số, open-source hoàn toàn, chạy real-time với 80ms latency ngay trên chiếc RTX 4090 nằm trên bàn làm việc của bạn.
Không cần data center. Không cần thuê cloud. Không cần phải là Google hay DeepMind.
Bài viết này sẽ giải thích kiến trúc model, các đổi mới kỹ thuật quan trọng, và hướng dẫn bạn từng bước để cài đặt và chạy model này. Nếu bạn đã từng đọc về Diffusion Policy hay VLA models thế hệ trước, bạn sẽ thấy Xiaomi-Robotics-0 là một bước tiến thực sự thú vị.
Tại sao Xiaomi-Robotics-0 đáng chú ý?
Trước khi đi vào kỹ thuật, hãy hiểu vì sao model này được cộng đồng robotics để mắt:
1. Nhỏ gọn nhưng không tầm thường. 4.7B tham số là con số khiêm tốn so với các LLM "khủng" ngày nay, nhưng đây là một sự đánh đổi có chủ ý. Nhỏ hơn = inference nhanh hơn = chạy được trên hardware phổ thông. Với robot, tốc độ phản hồi là sống còn.
2. Open-source thực sự. Không chỉ là open weights — Xiaomi mở toàn bộ code, checkpoints, và tài liệu kỹ thuật chi tiết. Bạn có thể fine-tune, nghiên cứu, và deploy theo nhu cầu.
3. 30Hz control frequency. Robot cần điều khiển mượt mà. 30 lần/giây đủ để xử lý các task manipulation phức tạp như gấp khăn hay tháo lắp Lego.
4. Kết quả benchmark ấn tượng. 98.7% success rate trên LIBERO — bộ benchmark tiêu chuẩn trong giới robot learning.
Kiến trúc — Hai bộ não trong một model
Hãy tưởng tượng bạn đang học nấu ăn. Một phần não bạn nhìn vào nguyên liệu và hiểu "đây là cà rốt, kia là thớt, cần thái nhỏ". Phần kia điều khiển tay bạn thực hiện từng nhát dao mượt mà và liên tục. Xiaomi-Robotics-0 hoạt động theo cách tương tự, với hai module riêng biệt:

Module 1: VLM Backbone — Qwen3-VL-4B-Instruct
Qwen3-VL (Vision-Language Model của Alibaba) là "bộ não nhận thức" của model. Nó nhận vào:
- Ảnh từ camera của robot (góc nhìn tay, góc nhìn toàn cảnh)
- Language instruction từ người dùng ("nhặt hộp đỏ và đặt vào khay")
- Trạng thái proprioceptive (góc khớp, lực tác dụng, vị trí end-effector)
Từ những input đó, VLM tạo ra một KV cache (Key-Value cache) — hiểu nôm na là một "bản tóm tắt ngữ cảnh" mã hóa toàn bộ thông tin về tình huống hiện tại của robot. KV cache này rất quan trọng vì nó là cầu nối giữa "hiểu" và "làm".
Module 2: Diffusion Transformer (DiT) — Bộ não vận động
DiT là module sinh ra hành động cụ thể cho robot. Nó nhận KV cache từ VLM và dùng kỹ thuật flow matching — một biến thể hiệu quả của diffusion — để tạo ra một chuỗi T hành động liên tiếp (action chunk).
Nếu bạn đã quen với Diffusion Policy, đây là concept tương tự nhưng được tích hợp sâu với VLM thông qua cross-attention. DiT có 16 layer, mỗi layer được điều kiện hóa bởi KV cache từ 16 layer cuối của VLM.
Tại sao lại dùng flow matching thay vì DDPM gốc? Tốc độ. Flow matching cho phép chỉ cần 5 denoising steps thay vì hàng chục steps của DDPM truyền thống, giúp giữ latency ở mức 80ms.
[Camera views] ─────┐
[Language task] ────┤──→ Qwen3-VL-4B ──→ KV Cache ──┐
[Robot state] ─────┘ │
▼
DiT (16 layers)
│
▼
Action Chunk [a₁, a₂, ..., aₜ]
Ba đổi mới kỹ thuật quan trọng
Kiến trúc VLM + DiT không phải lần đầu xuất hiện (xem π0 fast). Điều làm Xiaomi-Robotics-0 nổi bật nằm ở ba cải tiến kỹ thuật sau:
1. Λ-shape Attention Mask (Lambda Attention)
Đây là trick thông minh nhất trong paper. Để hiểu tại sao cần nó, hãy hiểu vấn đề trước:
Trong asynchronous execution (robot thực hiện action A trong khi model đang tính action B), model có thể "lười biếng" — thay vì nhìn vào ảnh camera mới để quyết định action tiếp theo, nó có thể chỉ copy action cũ ra. Đây gọi là shortcut bias.
Λ-shape mask giải quyết bằng cách:
- Các action token sớm (noisy, chưa confirmed) được phép attend đến action đã commit trước đó → đảm bảo smooth transition
- Các action token muộn (clean, sắp execute) bị cấm attend đến action cũ → buộc phải nhìn vào visual input mới
Kết quả: model phải thực sự "nhìn" môi trường thay vì sao chép.
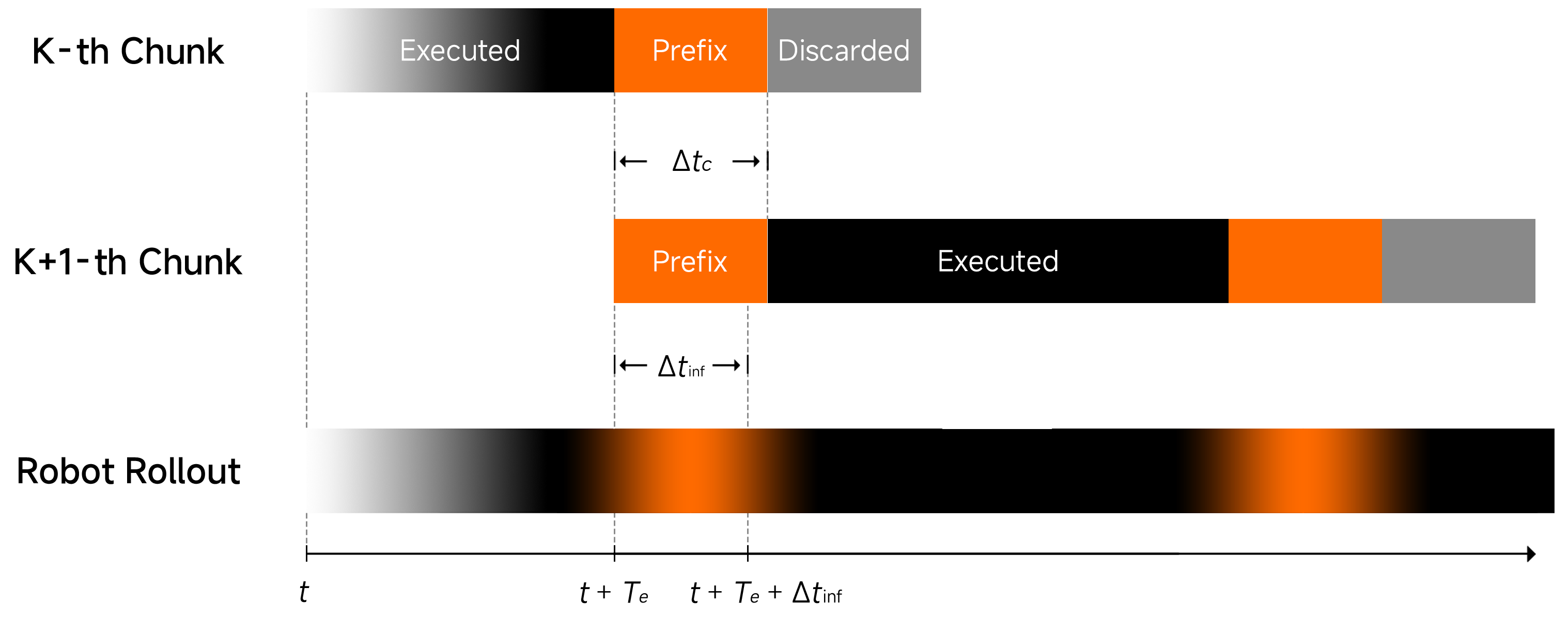
2. Action Prefixing
Thay vì mỗi lần inference tạo hoàn toàn một action chunk mới từ đầu, model tái sử dụng phần đầu của action chunk trước — gọi là "committed actions". Phần còn lại mới được tính lại.
Lợi ích kép:
- Smooth continuity: Robot không bị giật cục giữa các inference cycle
- Tốc độ: Chỉ cần tính lại phần nhỏ của action chunk
3. Asynchronous Execution

Thay vì: Robot đứng chờ → Inference → Robot thực hiện → Robot đứng chờ → ...
Xiaomi-Robotics-0 dùng: Robot thực hiện action chunk hiện tại → GPU đồng thời tính action chunk tiếp theo
Hai việc diễn ra song song, nên control frequency 30Hz được duy trì liên tục dù mỗi inference mất 80ms.
Dữ liệu huấn luyện — Nguồn gốc của "kinh nghiệm"
Model này không "tự nhiên" giỏi — nó cần được học từ dữ liệu khổng lồ:
| Loại dữ liệu | Khối lượng | Nguồn |
|---|---|---|
| Robot trajectories | ~200 triệu timesteps | DROID, MolmoAct, in-house bimanual |
| Vision-Language data | >80 triệu samples | VQA, captioning, grounding, embodied reasoning |
| Lego Disassembly demos | 338 giờ | Teleoperation in-house |
| Towel Folding demos | 400 giờ | Teleoperation in-house |
Tỉ lệ trộn VL:robot = 6:1 trong Stage 1 training — không để VLM "quên" khả năng hiểu ngôn ngữ trong quá trình học robot actions.
Quy trình Training 2 Giai đoạn
Stage 1 — VLM pretraining với robot data: VLM được huấn luyện joint trên cả VL tasks và robot trajectory prediction. Technique đặc biệt ở đây là Choice Policies: khi có nhiều trajectory hợp lệ cho cùng một task (robot có thể nhặt vật từ nhiều góc độ khác nhau), model học cách chọn một trajectory và commit thay vì "trung bình hóa" tất cả — điều này tránh mode collapse trong action distribution.
Stage 2 — DiT training: VLM bị đóng băng (frozen). Chỉ DiT được train từ đầu với flow-matching loss. Lý do đóng băng VLM: tránh catastrophic forgetting — nếu train toàn bộ model cùng lúc, VLM có thể "quên" language understanding.
Post-training: Fine-tune thêm với Λ-shape attention mask và RoPE positional index offsetting để enable asynchronous execution.
Kết Quả Benchmark
| Benchmark | Xiaomi-Robotics-0 | Ghi chú |
|---|---|---|
| LIBERO (Avg) | 98.7% | 4 suites: Spatial, Object, Goal, Long |
| SimplerEnv Visual Matching | 85.5% | Google Robot embodiment |
| SimplerEnv Visual Aggregation | 74.7% | Harder variant, more distractors |
| SimplerEnv WidowX | 79.2% | Bridge dataset evaluation |
| CALVIN ABCD→D | 4.80 avg tasks | Open-vocabulary manipulation |
Trên robot thật với dual-arm setup:
- Lego Disassembly (20 khối): tháo lắp liên tục, độ chính xác cao
- Towel Folding: task dài horizon với vải mềm (deformable object) — một trong những task khó nhất trong manipulation
Cài Đặt — Từng Bước
Yêu cầu hệ thống
- GPU: NVIDIA RTX 4090 (24GB VRAM) — khuyến nghị. RTX 3090 (24GB) cũng có thể chạy nhưng chậm hơn.
- RAM: 32GB+
- Python: 3.12
- CUDA: 12.x compatible
- OS: Ubuntu 22.04 LTS (khuyến nghị)
Bước 1: Tạo môi trường Python
# Dùng conda để tránh conflict dependencies
conda create -n xiaomi-robotics python=3.12 -y
conda activate xiaomi-robotics
Bước 2: Cài PyTorch và dependencies
# PyTorch 2.8.0 với CUDA support
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 \
--index-url https://download.pytorch.org/whl/cu128
# Transformers version cụ thể (quan trọng!)
pip install transformers==4.57.1
# Flash Attention 2 — tăng tốc inference đáng kể
pip install flash-attn==2.8.3 --no-build-isolation
# System libs (Ubuntu/Debian)
sudo apt-get install -y libegl1 libgl1 libgles2
Bước 3: Clone repo và cài package
git clone https://github.com/XiaomiRobotics/Xiaomi-Robotics-0.git
cd Xiaomi-Robotics-0
pip install -e .
Bước 4: Tải model weights
Model weights có trên HuggingFace tại XiaomiRobotics/Xiaomi-Robotics-0. Có nhiều checkpoint tùy mục đích:
from transformers import AutoModel, AutoProcessor
# Load base model (general purpose)
model = AutoModel.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0",
trust_remote_code=True,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
).cuda().eval()
processor = AutoProcessor.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0",
trust_remote_code=True,
)
Nếu muốn chạy benchmark LIBERO, tải checkpoint đã fine-tune:
# LIBERO-specific checkpoint
model = AutoModel.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0-LIBERO",
trust_remote_code=True,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
).cuda().eval()
Inference — Chạy Model Thực Tế
import torch
from transformers import AutoModel, AutoProcessor
from PIL import Image
# Khởi tạo model và processor
model = AutoModel.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0",
trust_remote_code=True,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
).cuda().eval()
processor = AutoProcessor.from_pretrained(
"XiaomiRobotics/Xiaomi-Robotics-0",
trust_remote_code=True,
)
# Chuẩn bị input
# images: list ảnh từ các camera góc nhìn khác nhau
wrist_image = Image.open("wrist_cam.jpg") # Camera trên tay robot
front_image = Image.open("front_cam.jpg") # Camera góc nhìn toàn cảnh
images = [wrist_image, front_image]
instruction = "Nhặt hộp màu đỏ và đặt vào khay bên phải"
# Proprioceptive state: góc khớp, vị trí end-effector, etc.
proprio_state = torch.zeros(1, 7).cuda() # Thay bằng state thực của robot
# Lấy action mask theo robot type
action_mask = processor.get_action_mask(robot_type="widowx") # hoặc "google_robot"
# Process input
inputs = processor(
images=images,
text=instruction,
return_tensors="pt",
).to("cuda", dtype=torch.bfloat16)
# Inference — sinh action chunk
with torch.inference_mode():
actions = model.generate_actions(
**inputs,
proprio_state=proprio_state,
action_mask=action_mask,
num_diffusion_steps=5, # 5 steps là đủ với flow matching
seed=42,
)
# actions shape: [1, T, action_dim]
# T = độ dài action chunk (thường 16-32 steps)
# action_dim = số chiều action (7 cho WidowX: 6 DoF + gripper)
print(f"Generated {actions.shape[1]} action steps")
print(f"First action: {actions[0, 0].cpu().numpy()}")

Tips để tăng tốc inference
# Dùng torch.compile để tăng tốc thêm ~20%
model = torch.compile(model, mode="reduce-overhead")
# Bật KV cache reuse cho asynchronous execution
model.enable_kv_cache(max_batch_size=1, max_seq_length=512)
So sánh với các VLA Models khác
| Model | Params | Inference | Control Hz | Open Source |
|---|---|---|---|---|
| Xiaomi-Robotics-0 | 4.7B | 80ms | 30Hz | ✅ Toàn bộ |
| π0 fast | ~3B | ~60ms | 50Hz | ❌ Weights only |
| OpenVLA | 7B | ~200ms | 5Hz | ✅ |
| SmolVLA | 450M | ~30ms | 33Hz | ✅ |
| GR00T N1.6 | >10B | >100ms | 15Hz | ❌ |
Nhận xét:
- Nếu cần siêu nhẹ để chạy trên edge device (Jetson Orin), SmolVLA là lựa chọn tốt hơn
- Nếu cần balance giữa performance và tốc độ với GPU consumer, Xiaomi-Robotics-0 là điểm ngọt
- Nếu cần tốt nhất không kể tốc độ (data center), các model lớn hơn sẽ thắng
Khi nào nên dùng Xiaomi-Robotics-0?
Phù hợp khi:
- Bạn có RTX 4090 hoặc GPU 24GB VRAM
- Cần control frequency ≥ 30Hz cho real-time manipulation
- Muốn fine-tune trên robot của mình (dual-arm bimanual tasks)
- Nghiên cứu kiến trúc VLM + DiT
Không phù hợp khi:
- GPU < 16GB VRAM → xem xét SmolVLA hoặc quantized versions
- Task cần ngôn ngữ rất phức tạp, multi-step planning dài → cần model lớn hơn
- Edge deployment trên Jetson Nano → quá nặng
Kết luận
Xiaomi-Robotics-0 không phải model tốt nhất trong mọi benchmark — nhưng nó đặt ra một tiêu chuẩn mới về tính thực dụng: real-time, open-source, chạy được trên GPU consumer. Với các kỹ sư robotics Việt Nam đang làm việc với budget hạn chế, đây là tin tốt.
Điều tôi thấy thú vị nhất là quyết định thiết kế của Xiaomi: thay vì chạy đua thông số, họ tập trung giải quyết một vấn đề rất thực tế — làm thế nào để VLA model có thể điều khiển robot mượt mà, liên tục, và không bị giật cục. Λ-shape attention mask và asynchronous execution là những giải pháp kỹ thuật thực sự tinh tế.
Bước tiếp theo? Fine-tune model này trên dữ liệu của robot bạn. Xiaomi cung cấp training scripts đầy đủ — đây là lợi thế lớn so với các model closed-source chỉ cho phép bạn chạy inference.