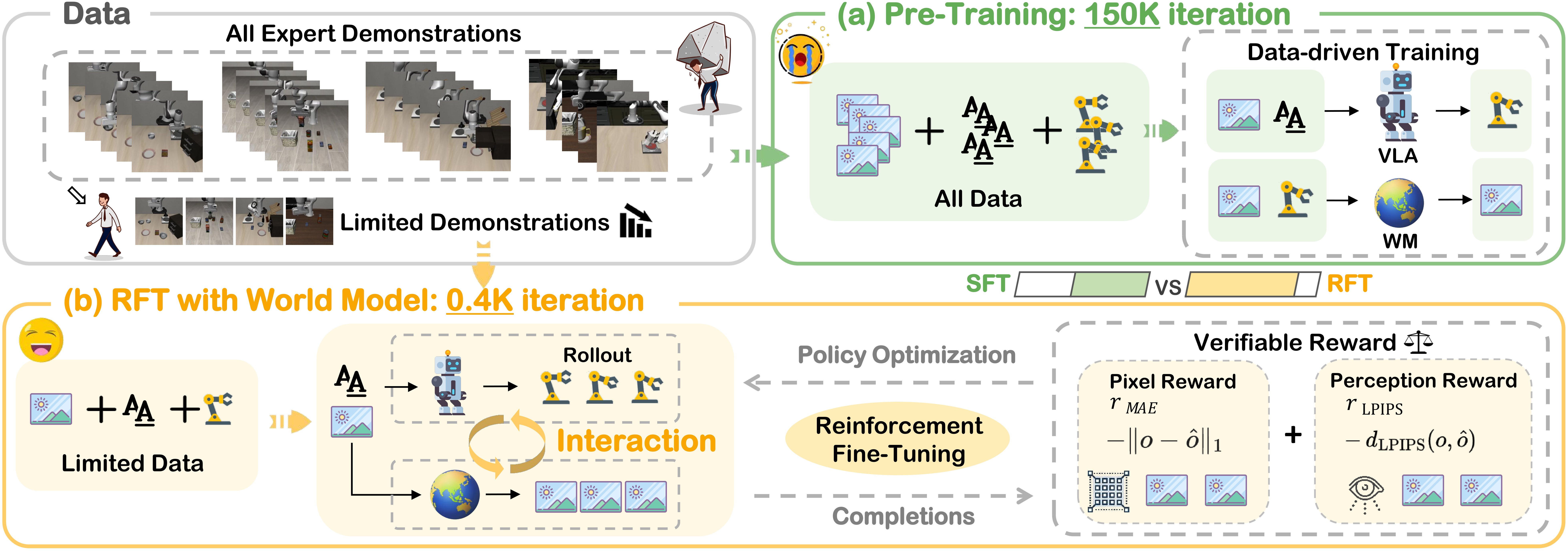
Bạn đã từng train một VLA model, kết quả SFT trên demo tốt nhưng khi robot ra đời thực thì thất bại? Đây là vấn đề cơ bản: SFT chỉ bắt chước thành công, không học từ thất bại. TGRPO (arXiv 2506.08440) từ Jilin University đề xuất một hướng khác — dùng online RL với hai lớp advantage và reward được LLM tự sinh, đưa OpenVLA-7B từ 86.4% lên 91.0% success rate trên LIBERO-Object mà chỉ cần 1 GPU A100.
Bài này phân tích chi tiết kỹ thuật của TGRPO: tại sao GRPO chuẩn không đủ cho robotics, LLM sinh dense reward như thế nào, và dual-level advantage hoạt động ra sao.
Vấn đề: SFT dạy robot bắt chước, không dạy robot thích nghi
Hãy tưởng tượng bạn học lái xe bằng cách xem 1000 video lái xe thành công. Bạn sẽ bắt chước được pattern, nhưng lần đầu gặp tình huống bất ngờ (xe khác cắt ngang, đường trơn) — bạn không biết phải làm gì vì chưa bao giờ trải nghiệm và vượt qua thất bại.
VLA model train bằng SFT cũng vậy. Khi gặp vật thể ở vị trí hơi lệch so với demo, ánh sáng khác, hoặc thứ tự nhiệm vụ thay đổi nhẹ — policy sụp đổ. Lý do kỹ thuật: SFT minimize behavior cloning loss trên demonstration thành công, không có tín hiệu nào về "tại sao thất bại" hay "làm sao để phục hồi".
Reinforcement learning (RL) giải quyết điều này bằng cách cho robot thực sự thử và nhận feedback. Nhưng áp dụng RL vào VLA có 3 thách thức:
- Reward design khó: Tabletop manipulation có nhiều sub-task phức tạp. Dùng sparse reward (0/1 cuối episode) → credit assignment cực kỳ khó cho 200+ bước.
- Credit assignment dài: Bước 50 dẫn đến thành công ở bước 150 — làm sao biết bước nào quan trọng?
- GRPO không được thiết kế cho trajectory dài: GRPO (Group Relative Policy Optimization) gốc sinh ra cho LLM reasoning, mỗi "trajectory" là vài chục token. Robot trajectory là hàng trăm bước hành động liên tục.
TGRPO giải quyết cả 3 vấn đề cùng lúc.
TGRPO là gì? — Big picture trước khi đào sâu
TGRPO = Trajectory-wise Group Relative Policy Optimization.
Ba thành phần chính:
[LLM] → Dense Reward Function
↓
[Robot runs N=4 parallel trajectories] → collect (state, action, reward) tuples
↓
[TGRPO] → compute step-level + trajectory-level advantage → update policy
Nói đơn giản: LLM đọc mô tả task → tự viết hàm reward chi tiết → robot chạy nhiều lần song song → so sánh relative performance cả ở từng bước lẫn toàn bộ trajectory → update policy.
Điểm khác biệt với GRPO chuẩn: GRPO chỉ so sánh ở mức group (trajectory nào tốt hơn). TGRPO thêm step-level comparison — ở timestep t cụ thể, action nào trong N parallel trajectory cho reward cao hơn?
Nguồn: TGRPO paper, Jilin University (arXiv 2506.08440)
Thành phần 1: LLM Dense Reward — Không cần hand-craft reward nữa
Đây là contribution thực dụng nhất của paper. Thay vì kỹ sư phải ngồi viết hàm reward cho từng task (tốn hàng tuần), TGRPO dùng LLM để tự động sinh reward.
Cách LLM sinh reward
LLM nhận vào prompt gồm:
- Mô tả task bằng ngôn ngữ tự nhiên (vd: "Pick up the milk and place it in the basket")
- Environment code của LIBERO (để LLM hiểu state space, object positions, success conditions)
- Yêu cầu cụ thể về format reward
Prompt cốt lõi (theo paper):
"Based on task description, LIBERO environment code, and RL robotics characteristics,
generate a multi-stage reward function where robot receives constant stage-specific
rewards at proximity thresholds, with progressively increasing values per stage
and significantly higher completion rewards."
LLM output là một hàm Python với cấu trúc multi-stage:
def compute_reward(state, info):
# Stage 1: Approach object
dist_to_obj = compute_distance(state.ee_pos, state.obj_pos)
if dist_to_obj < 0.05: # 5cm threshold
reward += 1.0
# Stage 2: Grasp
if info.is_grasped:
reward += 3.0
# Stage 3: Transport to goal
dist_to_goal = compute_distance(state.obj_pos, state.goal_pos)
if dist_to_goal < 0.1:
reward += 5.0
# Stage 4: Place (completion)
if info.task_success:
reward += 10.0
# End-effector pose shaping from demonstration
reward += alpha * pose_similarity(state.ee_pose, demo_ee_pose)
return reward
Reward function gồm 2 thành phần:
- f₁(P_object, P_pose_k): Object position tracking — phần thưởng khi object tiến gần mốc tiếp theo
- f₂(P_pose_k, s_t): End-effector pose shaping — khuyến khích pose tương tự demonstration
Công thức tổng: Rₜ = f₁(P_object(t), P_pose^k) + f₂(P_pose^k, s_t)
Điểm hay: LLM biết ngữ nghĩa của task ("milk vào basket") nên tự suy ra các sub-goal (approach → grasp → lift → place), không cần kỹ sư hard-code.
Thành phần 2: Trajectory-wise GRPO — Dual-level Advantage
Đây là phần toán học cốt lõi. GRPO chuẩn (dùng trong LLM) tính advantage bằng cách so sánh N parallel outputs với nhau. Với robotics, TGRPO mở rộng thành 2 lớp advantage:
Step-level advantage Sᵢ,ₜ
Ở mỗi timestep t, ta có N trajectories đang chạy. Step-level advantage so sánh reward tại timestep t cụ thể đó giữa N trajectories:
S_{i,t} = (R_{i,t} - mean({R_{j,t} for j in 1..N})) / std({R_{j,t} for j in 1..N})
"Tại bước này, tôi có reward cao hơn trung bình các trajectory khác không?"
Điều này capture local action quality — action cụ thể tại timestep t có tốt hơn các lựa chọn song song không?
Trajectory-level advantage Tᵢ
Nhìn toàn bộ trajectory i, so sánh tổng reward với N trajectories khác:
T_i = (R_i - mean({R_j for j in 1..N})) / std({R_j for j in 1..N})
"Nhìn tổng thể cả trajectory, tôi thực hiện tốt hơn hay tệ hơn nhóm?"
Điều này capture global task success — trajectory này nhìn chung đi đúng hướng không?
Fused Advantage
Kết hợp cả 2 lớp:
Adv_{i,t} = α₁ · S_{i,t} + α₂ · T_i
Paper thấy empirically: α₁ = 0.3, α₂ = 0.7 hoạt động tốt nhất cho hầu hết tasks. Trọng số trajectory-level cao hơn — có nghĩa là "bức tranh toàn cảnh" quan trọng hơn "điểm nhỏ lẻ".
Tại sao dual-level tốt hơn single-level?
Ablation study trong paper làm rõ:
| Method | LIBERO-Object avg |
|---|---|
| Step-level only | 73.6% |
| Trajectory-level only | 86.8% |
| TGRPO (cả hai) | 91.0% |
Step-level alone thất bại nặng vì: một action "ngẫu nhiên tốt" tại step t không có nghĩa là cả strategy tốt. Trajectory-level alone thiếu local guidance. Kết hợp cho cả 2 tín hiệu.

Kiến trúc đầy đủ
OpenVLA-7B (frozen)
└── LoRA adapter (trainable)
├── SigLIP encoder (visual features)
├── DINOv2 encoder (visual features)
└── Llama2-7B language backbone
Training loop:
For episode = 1..30:
Sample N=4 parallel trajectories from current policy π_θ
Collect (s_t, a_t, R_t) for each trajectory, max 200 steps
LLM Dense Reward:
R_t = f1(object_pos, keypose) + f2(ee_pose, demo_ee_pose)
Compute advantages:
S_{i,t} = normalize_step(R_{i,t}) # across N trajectories at t
T_i = normalize_traj(sum(R_i)) # across N trajectories total
Adv_{i,t} = 0.3 * S_{i,t} + 0.7 * T_i
Update LoRA with AdamW, lr=1e-5:
L = -E[Adv_{i,t} * log π_θ(a_{i,t} | s_{i,t})]
Cài đặt thực hành
Yêu cầu
- GPU: NVIDIA A100 (hoặc tương đương 40GB+ VRAM)
- LIBERO simulator đã cài
- OpenVLA-7B checkpoint
- LLM API access (để sinh reward function)
Setup LIBERO
# Cài LIBERO
pip install libero
# Download OpenVLA-7B
from huggingface_hub import snapshot_download
snapshot_download("openvla/openvla-7b", local_dir="./models/openvla-7b")
Sinh Reward Function bằng LLM
Trước khi train, dùng LLM để sinh reward cho từng task:
import anthropic # hoặc OpenAI
def generate_reward_function(task_description: str, env_code: str) -> str:
client = anthropic.Anthropic()
prompt = f"""Based on this task description and LIBERO environment code,
generate a multi-stage reward function for RL training.
Task: {task_description}
Environment code: {env_code}
Requirements:
- Multi-stage rewards with progressively increasing values
- Proximity thresholds for each stage
- High completion bonus at final stage
- End-effector pose shaping from demonstrations
- Return a Python function: def compute_reward(state, info) -> float
"""
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
Training với TGRPO
from tgrpo import TGRPOTrainer, TGRPOConfig
config = TGRPOConfig(
model_path="./models/openvla-7b",
lora_rank=16,
learning_rate=1e-5,
optimizer="adamw",
# TGRPO specific
n_parallel=4, # N parallel trajectories per step
alpha_step=0.3, # weight for step-level advantage
alpha_traj=0.7, # weight for trajectory-level advantage
# Training
max_episodes=30,
max_steps_per_episode=200,
n_test_episodes=50,
)
trainer = TGRPOTrainer(
config=config,
env_name="libero_object",
reward_fn=generated_reward_fn, # từ LLM
)
trainer.train()
Inference sau khi train
from openvla import OpenVLA
import torch
# Load fine-tuned model
model = OpenVLA.from_pretrained("./models/openvla-7b")
model.load_lora("./checkpoints/tgrpo-libero-object")
model.eval()
# Run inference
obs = env.reset()
for step in range(max_steps):
action = model.predict_action(
image=obs["rgb"],
instruction="Pick up the milk and place it in the basket"
)
obs, reward, done, info = env.step(action)
if done:
break
Kết quả chi tiết
LIBERO-Object (10 tasks)
| Method | Avg Success Rate |
|---|---|
| OpenVLA (zero-shot) | ~60% |
| SFT | 86.4% |
| PPO | 86.6% |
| GRAPE | ~89% |
| TGRPO | 91.0% |
4 suites LIBERO (từ Table 1 trong paper)
| Method | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|
| SFT | 84.7% | 88.4% | 79.2% | 51.1% | 76.5% |
| GRAPE | 88.5% | 92.1% | 83.1% | 57.2% | 80.2% |
| TGRPO | 90.4% | 92.2% | 81.0% | 59.2% | 80.7% |
Điểm đáng chú ý: LIBERO-Long (long-horizon tasks) TGRPO cải thiện nhiều nhất — +8.1% so với SFT. Đây chính xác là loại task mà dual-level advantage phát huy — trajectory-level advantage giúp robot "nhìn xa" hơn.
Ablation về group size N
| N (parallel trajectories) | LIBERO-Goal success |
|---|---|
| N=2 | 76.2% |
| N=4 | 81.0% |
| N=8 | 80.5% |
N=4 là sweet spot. N=2 không đủ diversity để so sánh. N=8 tốn GPU gấp đôi mà không cải thiện nhiều.
Hạn chế cần biết
1. Hyperparameter α₁, α₂ cần tune thủ công: Paper thấy α₁/α₂ tối ưu thay đổi theo từng task. Không có công thức chung tự động. Với tasks 1,7,8: α₁=10, α₂=1; với tasks 4,5,6: α₁≈0.3, α₂≈0.7. Thực tế deploy sẽ cần grid search.
2. Reward function từ LLM có thể sai: LLM generate reward dựa trên text description, nhưng environment state space có thể phức tạp hơn LLM hiểu. Cần verify reward bằng tay trước khi train.
3. Chỉ test trên LIBERO: Paper chưa validate trên real robot hay benchmark khác (RoboMimic, MetaWorld). Transfer performance chưa rõ.
4. Cần SFT checkpoint tốt làm baseline: TGRPO fine-tune từ SFT checkpoint, không train from scratch. Nếu SFT yếu thì RL cũng không cứu được.
Khi nào nên dùng TGRPO?
Phù hợp khi:
- Đã có SFT-trained VLA nhưng performance chưa đủ
- Có simulator để rollout (LIBERO, MuJoCo, Isaac Gym)
- Task có nhiều sub-stages rõ ràng (grasp → lift → place)
- Muốn tự động hóa reward design thay vì hand-craft
Chưa phù hợp khi:
- Không có simulator (real robot RL expensive)
- Task quá sparse, LLM không hiểu để sinh dense reward
- Ngân sách GPU ít (cần A100 ít nhất)
So sánh với các phương pháp khác
| Phương pháp | Reward | Advantage | GPU | Performance |
|---|---|---|---|---|
| SFT | Không có | N/A | Thấp | 86.4% |
| PPO | Hand-crafted | Value function | Cao | 86.6% |
| GRAPE | Sparse + shaped | Trajectory-level | Trung bình | ~89% |
| TGRPO | LLM dense | Step + Trajectory | Trung bình | 91.0% |
TGRPO đạt cân bằng tốt: không cần hand-craft reward (dùng LLM), không cần value network (critic-free như GRPO), hiệu quả GPU tốt hơn PPO.

Bài học lớn từ TGRPO
TGRPO thực ra dạy một bài học rộng hơn: trong RL cho robotics, reward design và credit assignment là 2 vấn đề khó nhất, và giải quyết cả 2 đồng thời mới có breakthrough.
- LLM dense reward giải quyết reward design: thay vì hand-craft, dùng LLM semantic understanding
- Dual-level advantage giải quyết credit assignment: nhìn cả local (step) và global (trajectory)
Xu hướng này sẽ mở rộng: thay vì engineer reward, ta sẽ "prompt" reward; thay vì chọn thuật toán RL, ta sẽ kết hợp nhiều lớp advantage cho task cụ thể.
Nếu bạn đang fine-tune VLA và muốn vượt performance SFT mà không cần viết reward thủ công — TGRPO là điểm xuất phát tốt.