Giới thiệu UnifoLM-VLA-0
Tháng 1 năm 2026, Unitree Robotics chính thức công bố UnifoLM-VLA-0 — một Vision-Language-Action (VLA) model open-source được thiết kế riêng để chạy trên robot humanoid G1. Đây là bước ngoặt quan trọng trong lĩnh vực embodied AI: lần đầu tiên một mô hình VLA hoàn chỉnh được phát hành mã nguồn mở kèm theo dữ liệu huấn luyện, pipeline thu thập dữ liệu, và hướng dẫn triển khai thực tế trên phần cứng cụ thể.
Khác với các VLA model trước đó như RT-2 hay OpenVLA chủ yếu hoạt động trên cánh tay robot cố định, UnifoLM-VLA-0 được tối ưu cho manipulation trên humanoid — nghĩa là robot phải phối hợp toàn thân (whole-body coordination), cân bằng trọng tâm, và thực hiện các task phức tạp với bàn tay dexterous trong môi trường thực tế.

Kiến trúc mô hình
Nền tảng: Qwen2.5-VL-7B
UnifoLM-VLA-0 được xây dựng trên Qwen2.5-VL-7B — một Vision-Language Model 7 tỷ tham số do Alibaba phát triển. Lý do chọn Qwen2.5-VL thay vì các backbone khác (LLaMA, PaLM):
- Native vision encoder: Qwen2.5-VL tích hợp sẵn ViT (Vision Transformer) encoder có khả năng xử lý ảnh ở nhiều resolution khác nhau, không cần thêm adapter phức tạp.
- Kích thước phù hợp: 7B parameters đủ lớn để capture các pattern phức tạp, nhưng vẫn chạy được trên GPU cấp workstation (1x A100 hoặc 2x RTX 4090).
- Multilingual support: Hỗ trợ tiếng Trung và tiếng Anh — phù hợp với đội ngũ Unitree tại Hàng Châu.
Continued Pre-training trên Robot Data
Điểm khác biệt lớn nhất của UnifoLM-VLA-0 so với các VLA khác là phương pháp continued pre-training (CPT). Thay vì fine-tune trực tiếp từ pretrained VLM, Unitree thêm một giai đoạn CPT với dữ liệu robot:
Qwen2.5-VL-7B (pretrained VLM)
│
▼ Continued Pre-training (CPT)
│ - 500K robot interaction episodes
│ - Multi-task, multi-embodiment data
│ - Mixed với 10% original VLM data (tránh catastrophic forgetting)
│
▼ UnifoLM-VLA-0 (robot-aware VLM)
│
▼ Task-specific Fine-tuning
│ - 12 manipulation task categories
│ - G1 specific kinematics + dynamics
│
▼ Deployed UnifoLM-VLA-0
Action Space Design
UnifoLM-VLA-0 sử dụng tokenized action space — mỗi action được biểu diễn dưới dạng sequence of discrete tokens, tương tự cách LLM tokenize text:
# Action space cho G1 upper body
# Mỗi arm: 7 DOF (shoulder 3 + elbow 1 + wrist 3)
# Waist: 3 DOF (yaw, pitch, roll)
# Mỗi Dex3-1 hand: 7 DOF (thumb 3 + index 2 + middle 2)
# Tổng: 7*2 + 3 + 7*2 = 31 DOF
ACTION_DIM = 31 # Tổng số bậc tự do điều khiển
ACTION_BINS = 256 # Số bin rời rạc cho mỗi DOF
CHUNK_SIZE = 10 # Số action steps predict cùng lúc (action chunking)
# Mỗi timestep, model output:
# [action_token_1, action_token_2, ..., action_token_310]
# = 31 DOF × 10 steps = 310 tokens per prediction
Thông số kỹ thuật Unitree G1 Upper Body
Để hiểu cách UnifoLM-VLA-0 điều khiển G1, cần nắm rõ cấu hình phần cứng upper body:
| Bộ phận | DOF | Chi tiết |
|---|---|---|
| Vai (Shoulder) | 3 per arm | Pitch, roll, yaw — phạm vi chuyển động rộng |
| Khuỷu (Elbow) | 1 per arm | Flexion/extension |
| Cổ tay (Wrist) | 3 per arm | Pronation/supination, flexion, deviation |
| Thắt lưng (Waist) | 1-3 | Yaw (cơ bản), có thể thêm pitch + roll |
| Bàn tay Dex3-1 | 7 per hand | Ngón cái 3 DOF, ngón trỏ 2 DOF, ngón giữa 2 DOF |
Dex3-1 Hand là thiết kế đặc biệt của Unitree — chỉ 3 ngón (thay vì 5 ngón như tay người) nhưng đủ để thực hiện hầu hết manipulation task nhờ ngón cái đối diện (opposable thumb) với 3 DOF. Chiến lược này giảm complexity đáng kể so với bàn tay 5 ngón (từ ~20 DOF xuống 7 DOF) trong khi vẫn giữ được khả năng grasping đa dạng.
12 Loại Task Manipulation
UnifoLM-VLA-0 được huấn luyện trên 12 categories of manipulation tasks với single unified policy — nghĩa là một model duy nhất xử lý tất cả các task, không cần chuyên biệt hóa:
- Pick and Place — Nhặt và đặt vật thể vào vị trí chỉ định
- Pouring — Rót chất lỏng từ bình này sang bình khác
- Stacking — Xếp chồng các khối, hộp lên nhau
- Tool Use — Sử dụng công cụ (búa, kìm, tuốc nơ vít)
- Drawer Open/Close — Mở/đóng ngăn kéo
- Door Manipulation — Mở cửa bằng tay nắm tròn hoặc tay nắm đòn
- Button Press — Nhấn nút, bật công tắc
- Cloth Folding — Gấp vải, khăn
- Cable Routing — Luồn dây, cắm cáp
- Bimanual Tasks — Các task yêu cầu phối hợp hai tay
- In-hand Manipulation — Xoay, lật vật thể trong lòng bàn tay
- Dynamic Tasks — Bắt vật thể di chuyển, tung bắt

Hướng dẫn triển khai
1. Thiết lập môi trường
# Tạo conda environment
conda create -n unifolm python=3.10 -y
conda activate unifolm
# Cài đặt PyTorch với CUDA 12.1
pip install torch==2.3.1 torchvision==0.18.1 --index-url https://download.pytorch.org/whl/cu121
# Clone repository
git clone https://github.com/unitreerobotics/unifolm-vla.git
cd unifolm-vla
# Cài đặt dependencies
pip install -e ".[all]"
# Dependencies chính bao gồm:
# - transformers>=4.43.0 (cho Qwen2.5-VL)
# - accelerate>=0.33.0 (distributed training)
# - deepspeed>=0.14.0 (ZeRO optimization)
# - unitree-sdk2-python>=0.2.0 (điều khiển G1)
# - opencv-python>=4.9.0 (xử lý hình ảnh)
# - wandb (logging)
2. Kiến trúc Model — Code chi tiết
"""
UnifoLM-VLA-0 Model Architecture
Dựa trên Qwen2.5-VL-7B với action head cho robot control
"""
import torch
import torch.nn as nn
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
class ActionHead(nn.Module):
"""
Action prediction head: chuyển đổi hidden states của VLM
thành discrete action tokens cho robot.
Input: hidden_states từ Qwen2.5-VL (dim=3584)
Output: action_logits (batch, chunk_size * action_dim, num_bins)
"""
def __init__(
self,
hidden_dim: int = 3584, # Qwen2.5-VL-7B hidden size
action_dim: int = 31, # G1 upper body DOF
chunk_size: int = 10, # Action chunking window
num_bins: int = 256, # Discretization bins
dropout: float = 0.1,
):
super().__init__()
self.action_dim = action_dim
self.chunk_size = chunk_size
self.num_bins = num_bins
# MLP projector: VLM hidden → action space
self.projector = nn.Sequential(
nn.Linear(hidden_dim, 2048),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(2048, 1024),
nn.GELU(),
nn.Dropout(dropout),
)
# Per-DOF action predictors
# Mỗi DOF có classifier riêng → chính xác hơn shared head
self.action_heads = nn.ModuleList([
nn.Linear(1024, num_bins)
for _ in range(action_dim * chunk_size)
])
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
"""
Args:
hidden_states: (batch, hidden_dim) — lấy từ [ACT] token
Returns:
action_logits: (batch, chunk_size * action_dim, num_bins)
"""
# Project từ VLM space sang action space
features = self.projector(hidden_states) # (batch, 1024)
# Predict mỗi DOF tại mỗi timestep
logits = []
for head in self.action_heads:
logits.append(head(features)) # (batch, num_bins)
# Stack thành tensor
action_logits = torch.stack(logits, dim=1) # (batch, 310, 256)
return action_logits
class UnifoLMVLA(nn.Module):
"""
UnifoLM-VLA-0: End-to-end VLA model cho Unitree G1.
Pipeline:
1. Nhận image (camera wrist/head) + language instruction
2. Qwen2.5-VL encode thành hidden representations
3. ActionHead decode thành robot actions
"""
def __init__(self, model_name: str = "Qwen/Qwen2.5-VL-7B-Instruct"):
super().__init__()
# Load pretrained Qwen2.5-VL
self.vlm = Qwen2VLForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# Processor cho tokenization
self.processor = AutoProcessor.from_pretrained(model_name)
# Action prediction head
self.action_head = ActionHead(
hidden_dim=self.vlm.config.hidden_size, # 3584 cho 7B
action_dim=31, # G1 upper body
chunk_size=10, # 10 steps ahead
num_bins=256, # 256 discrete bins
)
# Special token [ACT] — đánh dấu vị trí extract action
self._add_action_token()
def _add_action_token(self):
"""Thêm special token [ACT] vào vocabulary"""
special_tokens = {"additional_special_tokens": ["[ACT]"]}
self.processor.tokenizer.add_special_tokens(special_tokens)
self.vlm.resize_token_embeddings(len(self.processor.tokenizer))
self.act_token_id = self.processor.tokenizer.convert_tokens_to_ids("[ACT]")
def forward(
self,
images: torch.Tensor,
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
action_labels: torch.Tensor = None,
):
"""
Forward pass: image + text → actions.
Args:
images: (batch, C, H, W) — camera observation
input_ids: (batch, seq_len) — tokenized instruction + [ACT]
attention_mask: (batch, seq_len) — attention mask
action_labels: (batch, chunk_size, action_dim) — ground truth
Chỉ dùng khi training
"""
# 1. Forward qua VLM để lấy hidden states
outputs = self.vlm(
input_ids=input_ids,
attention_mask=attention_mask,
pixel_values=images,
output_hidden_states=True,
)
# 2. Lấy hidden state tại vị trí [ACT] token
last_hidden = outputs.hidden_states[-1] # (batch, seq, hidden)
act_mask = (input_ids == self.act_token_id)
act_hidden = last_hidden[act_mask] # (batch, hidden)
# 3. Predict actions
action_logits = self.action_head(act_hidden)
# action_logits: (batch, 310, 256)
# 4. Compute loss nếu đang training
loss = None
if action_labels is not None:
# Flatten labels: (batch, chunk_size, action_dim) → (batch, 310)
flat_labels = action_labels.reshape(-1,
self.action_head.chunk_size * self.action_head.action_dim)
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(
action_logits.reshape(-1, self.action_head.num_bins),
flat_labels.reshape(-1).long(),
)
return {
"loss": loss,
"action_logits": action_logits,
}
def predict_action(
self,
image: torch.Tensor,
instruction: str,
) -> torch.Tensor:
"""
Inference: predict action từ observation + instruction.
Returns:
actions: (chunk_size, action_dim) — continuous actions
đã được de-discretize về [-1, 1]
"""
# Tokenize instruction với [ACT] token ở cuối
prompt = f"Task: {instruction} [ACT]"
inputs = self.processor(
text=prompt,
images=image,
return_tensors="pt",
).to(self.vlm.device)
with torch.no_grad():
outputs = self.forward(
images=inputs["pixel_values"],
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
)
# Argmax để lấy discrete action
action_tokens = outputs["action_logits"].argmax(dim=-1) # (1, 310)
# De-discretize: [0, 255] → [-1.0, 1.0]
actions = (action_tokens.float() / 255.0) * 2.0 - 1.0
# Reshape: (1, 310) → (10, 31)
actions = actions.reshape(
self.action_head.chunk_size,
self.action_head.action_dim,
)
return actions
3. Thu thập dữ liệu — Teleoperation trên G1
Thu thập dữ liệu là bước quan trọng nhất. UnifoLM-VLA-0 sử dụng teleoperation qua Unitree SDK để thu thập demonstration data:
"""
Data Collection Pipeline cho Unitree G1
Sử dụng Unitree SDK2 để teleoperate và ghi lại trajectories.
"""
import time
import json
import numpy as np
import cv2
from pathlib import Path
from unitree_sdk2py.core.channel import ChannelSubscriber, ChannelPublisher
from unitree_sdk2py.idl.unitree_hg import LowCmd_, LowState_
from unitree_sdk2py.utils.thread import RecurrentThread
class G1DataCollector:
"""
Thu thập demonstration data từ G1 qua teleoperation.
Workflow:
1. Kết nối với G1 qua ethernet
2. Nhận trạng thái hiện tại (joint angles, images)
3. Người điều khiển gửi lệnh qua VR controller / keyboard
4. Ghi lại toàn bộ trajectory (observation, action pairs)
"""
# Cấu hình DOF cho upper body G1
# Index mapping theo Unitree SDK convention
UPPER_BODY_JOINTS = {
# Left arm (7 DOF)
"left_shoulder_pitch": 12,
"left_shoulder_roll": 13,
"left_shoulder_yaw": 14,
"left_elbow": 15,
"left_wrist_yaw": 16,
"left_wrist_pitch": 17,
"left_wrist_roll": 18,
# Right arm (7 DOF)
"right_shoulder_pitch": 19,
"right_shoulder_roll": 20,
"right_shoulder_yaw": 21,
"right_elbow": 22,
"right_wrist_yaw": 23,
"right_wrist_pitch": 24,
"right_wrist_roll": 25,
# Waist (3 DOF)
"waist_yaw": 9,
"waist_pitch": 10,
"waist_roll": 11,
}
# Dex3-1 hand DOF (riêng channel)
HAND_JOINTS = {
"left_thumb_mcp": 0, "left_thumb_pip": 1, "left_thumb_dip": 2,
"left_index_pip": 3, "left_index_dip": 4,
"left_middle_pip": 5, "left_middle_dip": 6,
"right_thumb_mcp": 7, "right_thumb_pip": 8, "right_thumb_dip": 9,
"right_index_pip": 10, "right_index_dip": 11,
"right_middle_pip": 12, "right_middle_dip": 13,
}
def __init__(self, save_dir: str, fps: int = 30):
self.save_dir = Path(save_dir)
self.save_dir.mkdir(parents=True, exist_ok=True)
self.fps = fps
self.recording = False
self.episode_data = []
self.episode_count = 0
# Camera setup (G1 có camera ở đầu và cổ tay)
self.head_cam = cv2.VideoCapture(0) # Head camera
self.wrist_cam = cv2.VideoCapture(2) # Wrist camera
# Unitree SDK subscriber cho joint states
self.state_subscriber = ChannelSubscriber("rt/lowstate", LowState_)
self.state_subscriber.Init()
def get_observation(self) -> dict:
"""
Lấy observation hiện tại gồm:
- Joint positions (31 DOF)
- Camera images (head + wrist)
- Joint velocities
- Torques
"""
# Đọc joint state từ SDK
state = self.state_subscriber.Read()
# Extract upper body joint positions
joint_pos = np.zeros(31)
idx = 0
for name, sdk_idx in self.UPPER_BODY_JOINTS.items():
joint_pos[idx] = state.motor_state[sdk_idx].q
idx += 1
# Extract hand joint positions
for name, hand_idx in self.HAND_JOINTS.items():
joint_pos[idx] = state.motor_state[26 + hand_idx].q
idx += 1
# Capture camera frames
_, head_img = self.head_cam.read()
_, wrist_img = self.wrist_cam.read()
# Resize cho model input (Qwen2.5-VL chấp nhận dynamic resolution)
head_img = cv2.resize(head_img, (640, 480))
wrist_img = cv2.resize(wrist_img, (320, 240))
return {
"joint_positions": joint_pos.copy(),
"head_image": head_img.copy(),
"wrist_image": wrist_img.copy(),
"timestamp": time.time(),
}
def record_step(self, action: np.ndarray):
"""
Ghi lại 1 step: observation + action pair.
Args:
action: (31,) numpy array — target joint positions
từ teleoperation input
"""
if not self.recording:
return
obs = self.get_observation()
self.episode_data.append({
"observation": obs,
"action": action.copy(),
})
def start_episode(self, task_description: str, task_category: str):
"""Bắt đầu ghi 1 episode mới"""
self.recording = True
self.episode_data = []
self.current_task = task_description
self.current_category = task_category
print(f"[REC] Bắt đầu episode: {task_description}")
def end_episode(self, success: bool = True):
"""
Kết thúc episode và lưu data.
Format lưu trữ:
save_dir/
episode_000/
metadata.json — task description, category, success
observations.npz — joint states (compressed numpy)
actions.npz — actions (compressed numpy)
images/ — camera frames (JPEG)
"""
self.recording = False
if not self.episode_data:
print("[WARN] Episode trống, bỏ qua")
return
# Tạo thư mục episode
ep_dir = self.save_dir / f"episode_{self.episode_count:04d}"
ep_dir.mkdir(exist_ok=True)
img_dir = ep_dir / "images"
img_dir.mkdir(exist_ok=True)
# Tách data
joint_positions = []
actions = []
for i, step in enumerate(self.episode_data):
joint_positions.append(step["observation"]["joint_positions"])
actions.append(step["action"])
# Lưu images
cv2.imwrite(
str(img_dir / f"head_{i:05d}.jpg"),
step["observation"]["head_image"],
[cv2.IMWRITE_JPEG_QUALITY, 90],
)
cv2.imwrite(
str(img_dir / f"wrist_{i:05d}.jpg"),
step["observation"]["wrist_image"],
[cv2.IMWRITE_JPEG_QUALITY, 90],
)
# Lưu numpy arrays
np.savez_compressed(
ep_dir / "observations.npz",
joint_positions=np.array(joint_positions),
)
np.savez_compressed(
ep_dir / "actions.npz",
actions=np.array(actions),
)
# Metadata
metadata = {
"task": self.current_task,
"category": self.current_category,
"num_steps": len(self.episode_data),
"fps": self.fps,
"success": success,
"timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
}
with open(ep_dir / "metadata.json", "w") as f:
json.dump(metadata, f, indent=2)
print(f"[SAVE] Episode {self.episode_count}: "
f"{len(self.episode_data)} steps, success={success}")
self.episode_count += 1
4. Training Pipeline
Huấn luyện UnifoLM-VLA-0 gồm 2 giai đoạn: continued pre-training rồi task-specific fine-tuning. Dưới đây là code cho giai đoạn fine-tuning (giai đoạn mà người dùng thường cần chạy):
"""
Training pipeline cho UnifoLM-VLA-0.
Fine-tune trên dữ liệu G1 manipulation.
"""
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import get_cosine_schedule_with_warmup
from accelerate import Accelerator
import numpy as np
import cv2
import json
import wandb
from pathlib import Path
class G1ManipulationDataset(Dataset):
"""
Dataset loader cho G1 manipulation data.
Mỗi sample = (image, instruction, action_chunk)
"""
def __init__(
self,
data_dir: str,
processor, # Qwen2.5-VL processor
chunk_size: int = 10,
num_bins: int = 256,
action_range: tuple = (-1.0, 1.0),
):
self.data_dir = Path(data_dir)
self.processor = processor
self.chunk_size = chunk_size
self.num_bins = num_bins
self.action_range = action_range
# Scan tất cả episodes
self.episodes = sorted(self.data_dir.glob("episode_*"))
# Build index: (episode_idx, start_step)
self.index = []
for ep_idx, ep_dir in enumerate(self.episodes):
meta = json.load(open(ep_dir / "metadata.json"))
if not meta["success"]:
continue # Bỏ qua episode thất bại
num_steps = meta["num_steps"]
# Sliding window qua episode
for start in range(0, num_steps - chunk_size + 1):
self.index.append((ep_idx, start))
print(f"Dataset: {len(self.episodes)} episodes, "
f"{len(self.index)} training samples")
def discretize_action(self, action: np.ndarray) -> np.ndarray:
"""
Chuyển continuous action [-1, 1] → discrete bin [0, 255].
Discretization giúp model predict actions như classification
thay vì regression → training ổn định hơn.
"""
lo, hi = self.action_range
normalized = (action - lo) / (hi - lo) # [0, 1]
binned = np.clip(normalized * self.num_bins, 0, self.num_bins - 1)
return binned.astype(np.int64)
def __len__(self):
return len(self.index)
def __getitem__(self, idx):
ep_idx, start = self.index[idx]
ep_dir = self.episodes[ep_idx]
# Load metadata
meta = json.load(open(ep_dir / "metadata.json"))
# Load observation image (dùng head camera)
img = cv2.imread(str(ep_dir / "images" / f"head_{start:05d}.jpg"))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Load action chunk
actions_data = np.load(ep_dir / "actions.npz")
action_chunk = actions_data["actions"][start:start + self.chunk_size]
# Discretize
action_labels = self.discretize_action(action_chunk)
# Format instruction
instruction = f"Task: {meta['task']} [ACT]"
# Process qua Qwen2.5-VL processor
inputs = self.processor(
text=instruction,
images=img,
return_tensors="pt",
padding="max_length",
max_length=512,
truncation=True,
)
return {
"input_ids": inputs["input_ids"].squeeze(0),
"attention_mask": inputs["attention_mask"].squeeze(0),
"pixel_values": inputs["pixel_values"].squeeze(0),
"action_labels": torch.tensor(action_labels), # (10, 31)
}
def train_unifolm_vla(
data_dir: str = "./data/g1_manipulation",
output_dir: str = "./checkpoints/unifolm-vla",
num_epochs: int = 50,
batch_size: int = 8,
learning_rate: float = 1e-4,
weight_decay: float = 0.01,
warmup_ratio: float = 0.05,
gradient_accumulation_steps: int = 4,
use_wandb: bool = True,
):
"""
Main training function cho UnifoLM-VLA-0.
Recommended hardware:
- 1x A100 80GB: batch_size=8, gradient_accumulation=4 (effective=32)
- 2x RTX 4090: batch_size=4, gradient_accumulation=8 (effective=32)
"""
# Accelerator cho mixed precision + multi-GPU
accelerator = Accelerator(
mixed_precision="bf16",
gradient_accumulation_steps=gradient_accumulation_steps,
)
if use_wandb and accelerator.is_main_process:
wandb.init(project="unifolm-vla", name="g1-finetune")
# Model
model = UnifoLMVLA(model_name="unitreerobotics/unifolm-vla-0-base")
# Freeze VLM backbone (chỉ train action head + LoRA adapters)
for param in model.vlm.parameters():
param.requires_grad = False
# Unfreeze last 4 layers cho fine-tuning
for layer in model.vlm.model.layers[-4:]:
for param in layer.parameters():
param.requires_grad = True
# Action head luôn trainable
for param in model.action_head.parameters():
param.requires_grad = True
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
total = sum(p.numel() for p in model.parameters())
print(f"Trainable: {trainable/1e6:.1f}M / {total/1e6:.1f}M "
f"({trainable/total*100:.1f}%)")
# Dataset
dataset = G1ManipulationDataset(
data_dir=data_dir,
processor=model.processor,
chunk_size=10,
)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4,
pin_memory=True,
drop_last=True,
)
# Optimizer: AdamW với weight decay
optimizer = torch.optim.AdamW(
filter(lambda p: p.requires_grad, model.parameters()),
lr=learning_rate,
weight_decay=weight_decay,
betas=(0.9, 0.95),
)
# Learning rate scheduler
total_steps = len(dataloader) * num_epochs // gradient_accumulation_steps
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=int(total_steps * warmup_ratio),
num_training_steps=total_steps,
)
# Prepare with accelerator
model, optimizer, dataloader, scheduler = accelerator.prepare(
model, optimizer, dataloader, scheduler,
)
# Training loop
global_step = 0
best_loss = float("inf")
for epoch in range(num_epochs):
model.train()
epoch_loss = 0.0
for batch_idx, batch in enumerate(dataloader):
with accelerator.accumulate(model):
outputs = model(
images=batch["pixel_values"],
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
action_labels=batch["action_labels"],
)
loss = outputs["loss"]
accelerator.backward(loss)
# Gradient clipping — quan trọng để tránh divergence
accelerator.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
epoch_loss += loss.item()
global_step += 1
# Logging
if global_step % 50 == 0 and accelerator.is_main_process:
avg_loss = epoch_loss / (batch_idx + 1)
lr = scheduler.get_last_lr()[0]
print(f"Epoch {epoch} | Step {global_step} | "
f"Loss: {avg_loss:.4f} | LR: {lr:.2e}")
if use_wandb:
wandb.log({
"loss": avg_loss,
"lr": lr,
"epoch": epoch,
"step": global_step,
})
# Save checkpoint mỗi epoch
avg_epoch_loss = epoch_loss / len(dataloader)
if accelerator.is_main_process:
print(f"\n[Epoch {epoch}] Average Loss: {avg_epoch_loss:.4f}")
if avg_epoch_loss < best_loss:
best_loss = avg_epoch_loss
save_path = Path(output_dir) / "best_model"
accelerator.save_state(save_path)
print(f"[SAVE] Best model saved to {save_path}")
# Save periodic checkpoint
if (epoch + 1) % 10 == 0:
save_path = Path(output_dir) / f"checkpoint_epoch_{epoch+1}"
accelerator.save_state(save_path)
if use_wandb and accelerator.is_main_process:
wandb.finish()
print(f"\nTraining complete! Best loss: {best_loss:.4f}")
# Config file cho training (lưu thành config.yaml)
TRAIN_CONFIG = """
# UnifoLM-VLA-0 Training Configuration
model:
name: "unitreerobotics/unifolm-vla-0-base"
action_dim: 31
chunk_size: 10
num_bins: 256
freeze_backbone: true
unfreeze_last_n_layers: 4
data:
train_dir: "./data/g1_manipulation/train"
val_dir: "./data/g1_manipulation/val"
image_size: [640, 480]
max_text_length: 512
training:
num_epochs: 50
batch_size: 8
learning_rate: 1e-4
weight_decay: 0.01
warmup_ratio: 0.05
gradient_accumulation_steps: 4
max_grad_norm: 1.0
mixed_precision: "bf16"
# DeepSpeed ZeRO Stage 2 cho multi-GPU
deepspeed:
zero_stage: 2
offload_optimizer: false
logging:
wandb_project: "unifolm-vla"
log_every_n_steps: 50
save_every_n_epochs: 10
"""
5. Inference và Deploy trên G1
"""
Inference pipeline: chạy UnifoLM-VLA-0 trực tiếp trên Unitree G1.
Hardware requirements:
- NVIDIA Jetson AGX Orin (onboard G1) hoặc
- External workstation với GPU, kết nối ethernet tới G1
"""
import torch
import numpy as np
import cv2
import time
from unitree_sdk2py.core.channel import ChannelPublisher, ChannelSubscriber
from unitree_sdk2py.idl.unitree_hg import LowCmd_, LowState_
class G1VLAController:
"""
Controller chạy UnifoLM-VLA-0 để điều khiển G1 real-time.
Loop:
1. Capture camera image
2. Run VLA inference → action chunk (10 steps)
3. Execute actions via low-level control
4. Repeat khi hết action chunk hoặc có observation mới
"""
def __init__(
self,
model_path: str,
control_freq: int = 30, # Hz — tần số gửi lệnh
inference_freq: int = 3, # Hz — tần số chạy model
kp: float = 40.0, # PD controller P gain
kd: float = 5.0, # PD controller D gain
):
self.control_freq = control_freq
self.inference_freq = inference_freq
self.kp = kp
self.kd = kd
# Load model
print("[INIT] Loading UnifoLM-VLA-0...")
self.model = UnifoLMVLA()
checkpoint = torch.load(model_path, map_location="cuda")
self.model.load_state_dict(checkpoint["model_state_dict"])
self.model.eval().cuda()
# TensorRT optimization (optional, ~2x speedup)
# self.model = torch.compile(self.model, mode="reduce-overhead")
print("[INIT] Model loaded successfully")
# Camera
self.camera = cv2.VideoCapture(0)
# Unitree SDK channels
self.cmd_publisher = ChannelPublisher("rt/lowcmd", LowCmd_)
self.cmd_publisher.Init()
self.state_subscriber = ChannelSubscriber("rt/lowstate", LowState_)
self.state_subscriber.Init()
# Action buffer
self.action_buffer = None
self.buffer_idx = 0
def capture_image(self) -> torch.Tensor:
"""Capture và preprocess camera image"""
ret, frame = self.camera.read()
if not ret:
raise RuntimeError("Camera capture failed")
# BGR → RGB
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.resize(frame, (640, 480))
return frame
def run_inference(self, image, instruction: str) -> np.ndarray:
"""
Chạy VLA inference → action chunk.
Returns:
actions: (chunk_size, action_dim) numpy array
"""
actions = self.model.predict_action(image, instruction)
return actions.cpu().numpy()
def send_joint_command(self, target_positions: np.ndarray):
"""
Gửi lệnh joint position tới G1 qua PD controller.
Args:
target_positions: (31,) — target joint angles (radians)
"""
cmd = LowCmd_()
# Upper body joints
joint_mapping = G1DataCollector.UPPER_BODY_JOINTS
idx = 0
for name, sdk_idx in joint_mapping.items():
cmd.motor_cmd[sdk_idx].mode = 0x01 # Position mode
cmd.motor_cmd[sdk_idx].q = float(target_positions[idx])
cmd.motor_cmd[sdk_idx].kp = self.kp
cmd.motor_cmd[sdk_idx].kd = self.kd
cmd.motor_cmd[sdk_idx].tau = 0.0 # No feedforward torque
idx += 1
# Hand joints
hand_mapping = G1DataCollector.HAND_JOINTS
for name, hand_idx in hand_mapping.items():
cmd.motor_cmd[26 + hand_idx].mode = 0x01
cmd.motor_cmd[26 + hand_idx].q = float(target_positions[idx])
cmd.motor_cmd[26 + hand_idx].kp = self.kp * 0.5 # Softer cho hand
cmd.motor_cmd[26 + hand_idx].kd = self.kd * 0.3
idx += 1
self.cmd_publisher.Write(cmd)
def run(self, instruction: str, max_duration: float = 60.0):
"""
Main control loop.
Args:
instruction: Language instruction (VD: "Pick up the red cup")
max_duration: Thời gian tối đa chạy (giây)
"""
print(f"[RUN] Instruction: {instruction}")
print(f"[RUN] Control: {self.control_freq}Hz, "
f"Inference: {self.inference_freq}Hz")
start_time = time.time()
inference_interval = 1.0 / self.inference_freq
control_interval = 1.0 / self.control_freq
last_inference_time = 0
while time.time() - start_time < max_duration:
loop_start = time.time()
# Chạy inference khi cần (mỗi ~333ms nếu 3Hz)
if (time.time() - last_inference_time > inference_interval
or self.action_buffer is None):
image = self.capture_image()
self.action_buffer = self.run_inference(image, instruction)
self.buffer_idx = 0
last_inference_time = time.time()
# Lấy action tiếp theo từ buffer
if self.buffer_idx < len(self.action_buffer):
action = self.action_buffer[self.buffer_idx]
self.buffer_idx += 1
# Scale từ [-1, 1] về actual joint range
scaled_action = self.scale_to_joint_range(action)
# Gửi lệnh
self.send_joint_command(scaled_action)
# Control rate limiting
elapsed = time.time() - loop_start
sleep_time = control_interval - elapsed
if sleep_time > 0:
time.sleep(sleep_time)
print("[DONE] Task execution complete")
@staticmethod
def scale_to_joint_range(action: np.ndarray) -> np.ndarray:
"""
Scale action [-1, 1] → actual joint angle ranges (radians).
Mỗi joint có range khác nhau theo spec của G1.
"""
# Joint limits cho G1 upper body (radians)
# Format: (min, max) cho mỗi DOF
joint_limits = np.array([
# Left arm
(-3.1, 3.1), (-1.5, 1.5), (-1.5, 1.5), # shoulder
(-2.6, 0.0), # elbow
(-1.5, 1.5), (-0.5, 0.5), (-1.5, 1.5), # wrist
# Right arm
(-3.1, 3.1), (-1.5, 1.5), (-1.5, 1.5), # shoulder
(-2.6, 0.0), # elbow
(-1.5, 1.5), (-0.5, 0.5), (-1.5, 1.5), # wrist
# Waist
(-2.0, 2.0), (-0.5, 0.5), (-0.3, 0.3),
# Left hand (Dex3-1) — 7 DOF
(0.0, 1.6), (0.0, 1.2), (0.0, 1.0), # thumb
(0.0, 1.4), (0.0, 1.2), # index
(0.0, 1.4), (0.0, 1.2), # middle
# Right hand (Dex3-1) — 7 DOF
(0.0, 1.6), (0.0, 1.2), (0.0, 1.0),
(0.0, 1.4), (0.0, 1.2),
(0.0, 1.4), (0.0, 1.2),
])
# Scale: [-1, 1] → [min, max]
lo = joint_limits[:, 0]
hi = joint_limits[:, 1]
scaled = lo + (action + 1.0) / 2.0 * (hi - lo)
return np.clip(scaled, lo, hi)
# Ví dụ sử dụng
if __name__ == "__main__":
controller = G1VLAController(
model_path="./checkpoints/unifolm-vla/best_model/model.pt",
control_freq=30,
inference_freq=3,
)
# Chạy task
controller.run(
instruction="Pick up the red cup and place it on the tray",
max_duration=60.0,
)

Đánh giá và phân tích kết quả
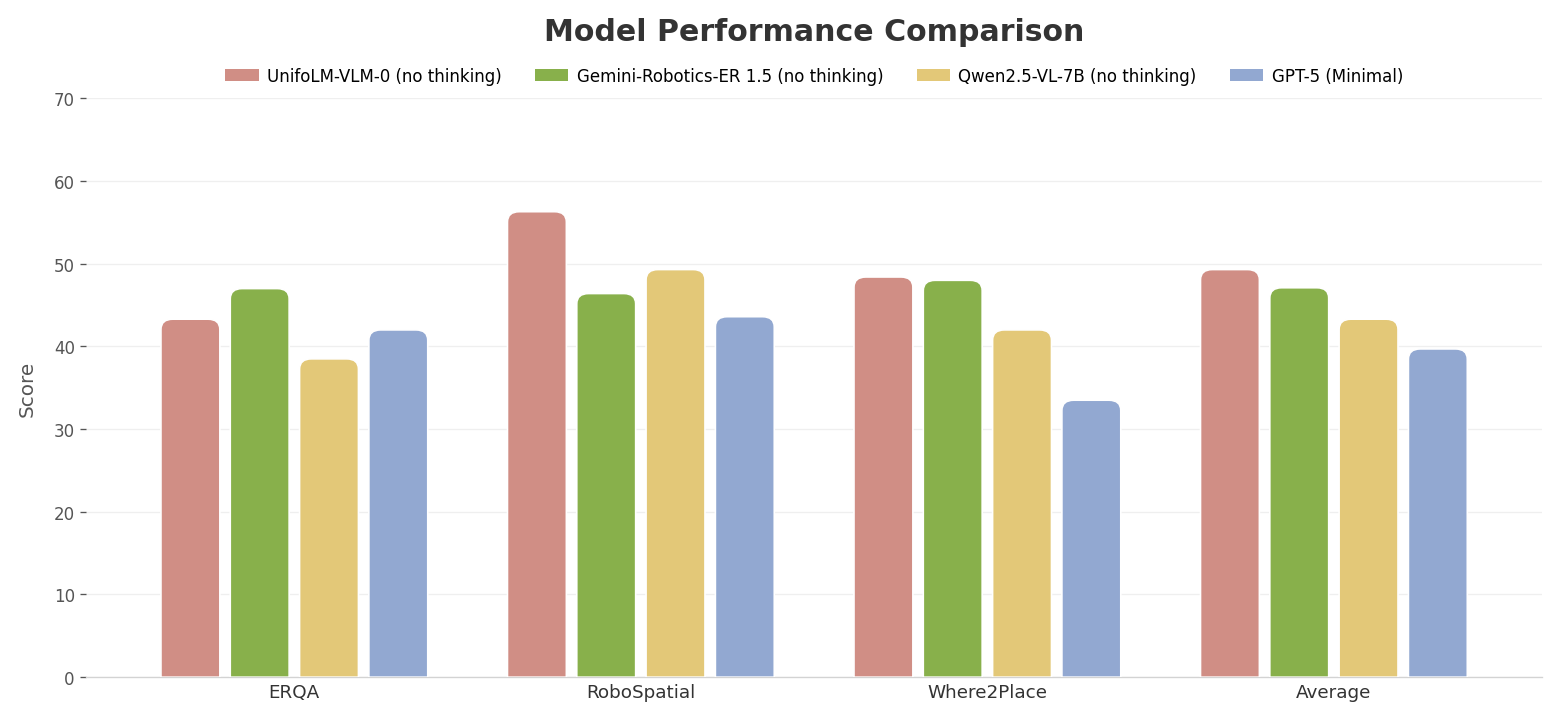
So sánh với các VLA khác
| Model | Params | Open-source | Humanoid | Task Categories | Action Space |
|---|---|---|---|---|---|
| RT-2 | 55B | Không | Không | ~10 | Continuous |
| OpenVLA | 7B | Có | Không | 5+ | Continuous |
| pi0 | 3B | Một phần | Không | 7+ | Flow matching |
| UnifoLM-VLA-0 | 7B | Có | Có (G1) | 12 | Discrete tokens |
Điểm mạnh
-
Single policy cho 12 task categories: Không cần train model riêng cho từng task — một model xử lý tất cả, từ pick-and-place đơn giản đến cloth folding phức tạp.
-
Open-source hoàn chỉnh: Bao gồm pretrained weights, training code, data collection pipeline, và inference code. Đây là điểm khác biệt lớn so với RT-2 (closed) hay pi0 (chỉ public weights).
-
Dexterous manipulation: Nhờ Dex3-1 hand với 7 DOF mỗi bàn tay, G1 có thể thực hiện các task yêu cầu sự khéo léo mà nhiều robot arm thông thường (gripper 2 ngón) không làm được.
-
Action chunking: Predict 10 steps cùng lúc giúp smooth trajectory và giảm latency (chỉ cần inference 3Hz thay vì 30Hz).
Hạn chế
-
Phụ thuộc vào Unitree G1: Model được train đặc thù cho G1 — transfer sang robot khác cần retrain hoặc ít nhất fine-tune lại action head.
-
Yêu cầu GPU mạnh: Inference realtime cần ít nhất Jetson AGX Orin hoặc RTX 4070+ — không chạy được trên edge device nhỏ.
-
Dữ liệu teleoperation tốn công: Thu thập demonstration data qua teleoperation đòi hỏi operator có kinh nghiệm và thiết bị VR.
-
Chưa có locomotion integration: UnifoLM-VLA-0 chỉ điều khiển upper body — chân vẫn cần controller riêng (thường là RL-based locomotion policy).
Ý nghĩa cho cộng đồng Robotics Việt Nam
UnifoLM-VLA-0 mở ra cơ hội lớn cho các nhóm nghiên cứu và startup robotics tại Việt Nam. Với mức giá G1 khoảng 16,000 USD (rẻ hơn nhiều so với Boston Dynamics Atlas hay Figure 02), kết hợp với VLA model open-source, rào cản gia nhập lĩnh vực humanoid manipulation đã giảm đáng kể.
Các hướng nghiên cứu tiềm năng:
- Fine-tune cho task đặc thù Việt Nam: Ví dụ manipulation trong nhà máy điện tử (lắp ráp linh kiện), nông nghiệp (thu hoạch trái cây), hay dịch vụ (pha chế đồ uống).
- Sim-to-real transfer: Kết hợp UnifoLM-VLA-0 với simulator (Isaac Sim, MuJoCo) để giảm lượng dữ liệu thực cần thu thập — xem thêm bài viết về sim-to-real pipeline.
- Multi-modal fusion: Thêm tactile sensor vào Dex3-1 hand để cải thiện grasping trong điều kiện thực tế.
Bài viết liên quan
- VLA Models: RT-2, Octo, OpenVLA, pi0 — Lịch sử phát triển — Tổng quan evolution của VLA từ 2023 đến nay.
- Spatial VLA — VLA với spatial reasoning — Phân tích mô hình VLA kết hợp spatial understanding.
- Imitation Learning — Nền tảng cho VLA — Hiểu cách robot học từ demonstration, là cơ sở của VLA.
- Humanoid Loco-Manipulation — Phối hợp di chuyển và thao tác — Thách thức kết hợp locomotion và manipulation trên humanoid.
Tài liệu tham khảo
- UnifoLM-VLA-0: A Unified Foundation Language Model for Vision-Language-Action on Humanoid Robots — Unitree Robotics, tháng 1/2026
- GitHub Repository: unitreerobotics/unifolm-vla — Mã nguồn, pretrained weights, dữ liệu mẫu
- Qwen2.5-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution — Wang et al., Alibaba Group, 2024
- OpenVLA: An Open-Source Vision-Language-Action Model — Kim et al., Stanford / UC Berkeley, 2024
- pi0: A Vision-Language-Action Flow Model for General Robot Control — Physical Intelligence, 2024