Vấn đề: VLA sau SFT đã chạm trần
Vision-Language-Action (VLA) models đang là hướng tiếp cận chủ đạo cho robot manipulation. Các mô hình như OpenVLA, RT-2, và Pi0 đã chứng minh rằng việc kết hợp vision, language và action trong một foundation model có thể tạo ra robot policies mạnh mẽ.
Tuy nhiên, hầu hết các VLA hiện tại đều được huấn luyện bằng Supervised Fine-Tuning (SFT) -- tức là bắt chước hành động từ dữ liệu demonstration của con người. Phương pháp này có một giới hạn cốt lõi: mô hình chỉ có thể tốt bằng dữ liệu huấn luyện, không bao giờ vượt qua được.
Điều này giống như việc bạn học lái xe chỉ bằng cách xem video người khác lái. Bạn có thể bắt chước được các thao tác cơ bản, nhưng khi gặp tình huống mới -- một con đường chưa từng thấy, một vật cản bất ngờ -- bạn sẽ không biết phải làm gì. Bạn cần tự lái và nhận phản hồi để thực sự giỏi lên.
Đó chính xác là điều mà SimpleVLA-RL giải quyết.

SimpleVLA-RL là gì?
SimpleVLA-RL là một framework được giới thiệu tại ICLR 2026, cho phép cải thiện VLA models thông qua online reinforcement learning với phần thưởng cực kỳ đơn giản: 0 hoặc 1 (thất bại hoặc thành công). Không cần thiết kế reward function phức tạp, không cần reward shaping, không cần dense rewards.
Ý tưởng cốt lõi:
- Bắt đầu từ một VLA đã qua SFT (ví dụ OpenVLA-OFT)
- Cho robot thử và sai trong simulation với binary reward
- Cập nhật policy bằng RL (cụ thể là PPO variant)
- Kết quả: VLA cải thiện vượt xa giới hạn SFT
Tại sao binary reward lại đủ?
Trong RL truyền thống cho robotics, thiết kế reward function là một nghệ thuật đen (và cũng là cơn ác mộng). Bạn cần phải:
- Đo khoảng cách gripper đến vật thể
- Thưởng cho mỗi bước tiến gần mục tiêu
- Phạt cho các hành động lãng phí năng lượng
- Cân bằng hàng chục hệ số reward
SimpleVLA-RL chứng minh rằng tất cả những thứ đó là không cần thiết nếu bạn bắt đầu từ một VLA đã có kiến thức nền tảng qua SFT. Mô hình đã biết cách gắp, cách di chuyển -- RL chỉ cần cho nó biết có thành công hay không để nó tự tối ưu.
Điều này tương tự như dạy một đầu bếp có tay nghề: bạn không cần chỉ dẫn từng bước cắt, từng lần khuấy. Bạn chỉ cần nếm món ăn và nói "ngon" hoặc "chưa ngon" -- đầu bếp sẽ tự biết cần điều chỉnh gì.
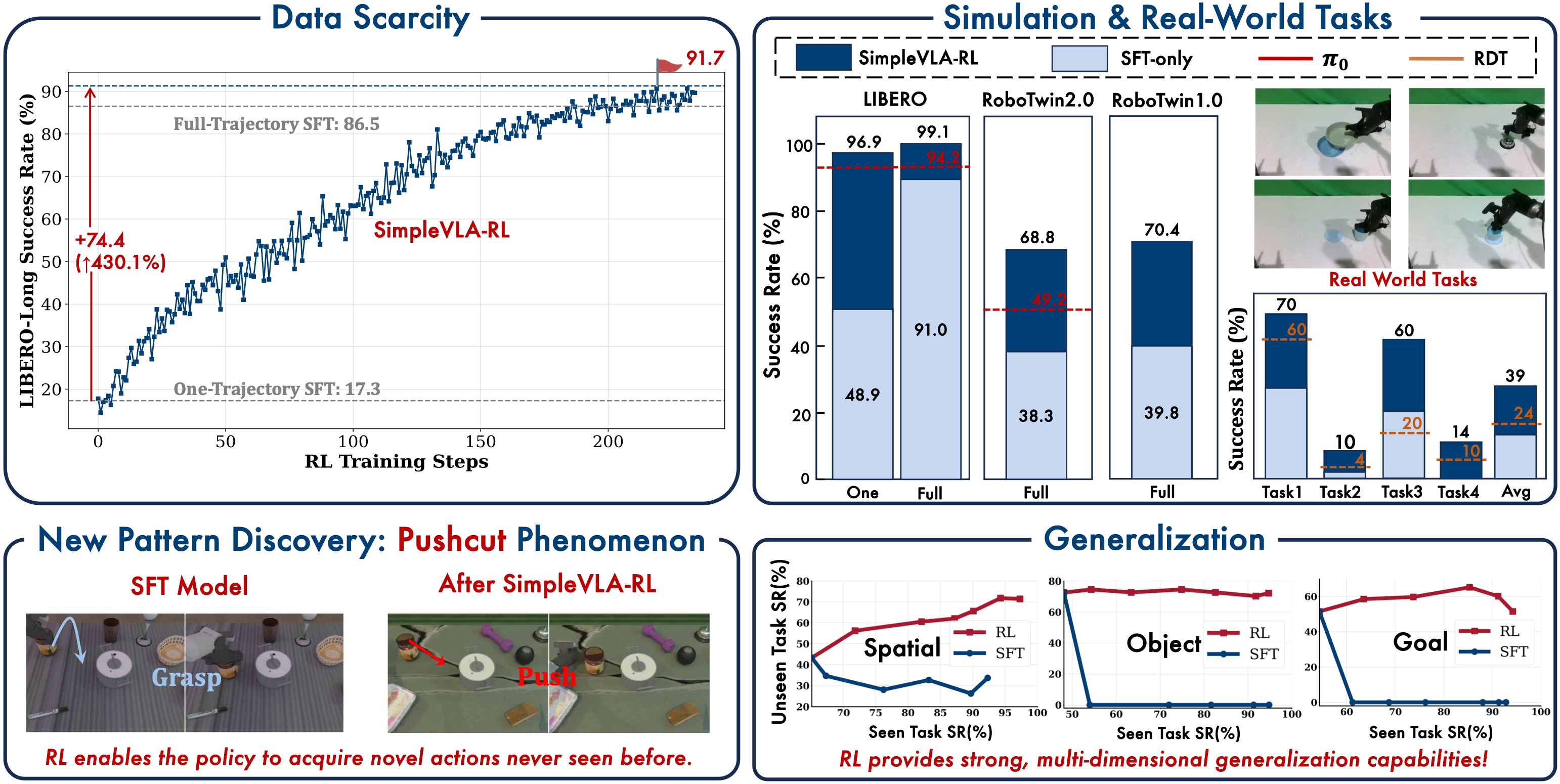
Hiện tượng "Pushcut": RL khám phá hành động mới
Một trong những phát hiện thú vị nhất của SimpleVLA-RL là hiện tượng "pushcut" -- RL tự khám phá ra các hành động hoàn toàn mới mà không có trong bất kỳ demonstration nào.
Cụ thể, trong các task cắt rau (cutting vegetables), con người demonstrate bằng cách dùng dao cắt theo cách truyền thống. Nhưng sau khi huấn luyện bằng RL, robot phát hiện ra rằng nó có thể đẩy dao qua vật thể (push + cut = pushcut) -- một kỹ thuật mà không có human demonstrator nào sử dụng, nhưng lại hiệu quả hơn cho robot với cấu hình gripper cụ thể.
Đây là bằng chứng mạnh mẽ rằng RL có thể giải phóng VLA khỏi giới hạn của dữ liệu con người. Robot không chỉ bắt chước tốt hơn -- nó sáng tạo ra cách làm mới phù hợp với khả năng vật lý của mình.
Kiến trúc: veRL + OpenVLA-OFT
SimpleVLA-RL được xây dựng trên hai thành phần chính:
OpenVLA-OFT (Policy base)
OpenVLA-OFT là phiên bản fine-tuned của OpenVLA, sử dụng Orthogonal Fine-Tuning để cải thiện hiệu suất trên các task cụ thể. Đây là điểm khởi đầu cho quá trình RL.
veRL (RL framework)
veRL là một framework RL hiệu suất cao, ban đầu được thiết kế cho việc huấn luyện Large Language Models (RLHF). SimpleVLA-RL mở rộng veRL để hỗ trợ:
- Multi-dimensional continuous action spaces (thay vì discrete token generation)
- Parallel environment rollouts trên nhiều GPU
- Reward từ simulation (LIBERO, RoboTwin)
Kiến trúc pipeline:
OpenVLA-OFT (SFT policy)
│
▼
veRL RL Training Loop
├── Rollout Workers (simulation environments)
├── Reward: binary 0/1 (task success/fail)
├── Policy Gradient (PPO-based)
└── KL Divergence constraint (tránh catastrophic forgetting)
│
▼
SimpleVLA-RL (improved policy)
Điểm quan trọng là KL divergence constraint -- giữ cho policy mới không đi quá xa so với policy SFT gốc. Điều này ngăn RL khiến mô hình "quên" những gì đã học từ SFT, một vấn đề phổ biến gọi là catastrophic forgetting.

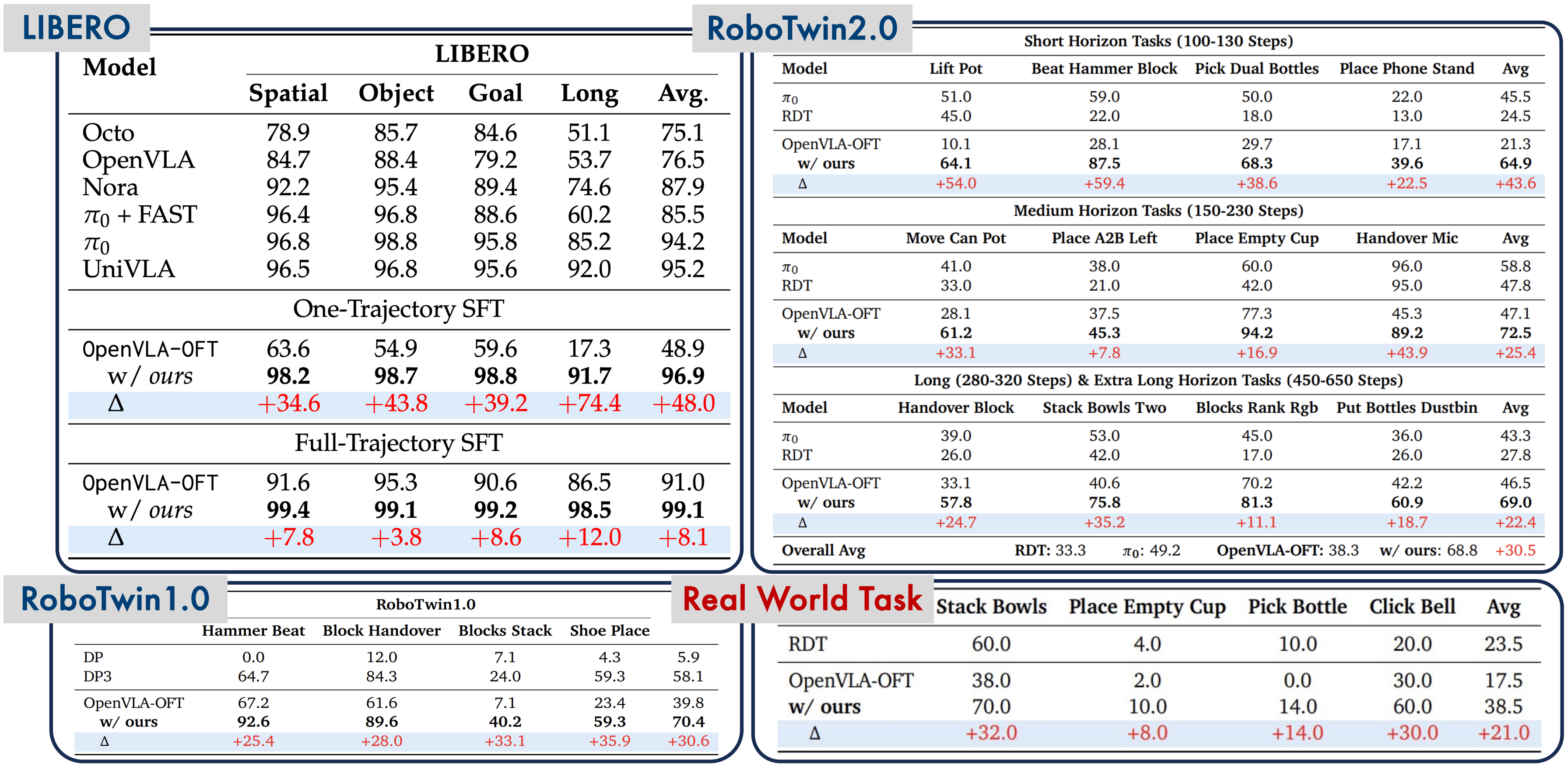
Kết quả: Con số nói lên tất cả
LIBERO-Long benchmark
| Method | Success Rate |
|---|---|
| OpenVLA-OFT (SFT only) | 85.4 |
| SimpleVLA-RL | 97.6 |
| Cải thiện | +12.2 điểm |
97.6% success rate trên LIBERO-Long là kết quả state-of-the-art, vượt xa tất cả các phương pháp SFT-only.
Cold-start: Phép màu từ 1 trajectory
Kết quả ấn tượng nhất là thí nghiệm cold-start: chỉ với 1 trajectory duy nhất cho mỗi task (thay vì hàng trăm demonstrations), SimpleVLA-RL đạt được:
| Setup | Success Rate |
|---|---|
| 1 demo + SFT only | 17.3 |
| 1 demo + SFT + RL | 91.7 |
| Cải thiện | +430% |
Từ 17.3 lên 91.7 -- cải thiện 430% -- chỉ với 1 demonstration. Điều này có ý nghĩa thực tiễn cực lớn: bạn không cần thu thập hàng nghìn demonstrations đắt đỏ. Chỉ cần 1 demo để "warm-start" policy, sau đó RL sẽ tự cải thiện.
Kết quả real-world
Trên các task dexterous manipulation thực tế (không phải simulation), SimpleVLA-RL đạt cải thiện khoảng 300% so với SFT baseline. Các task bao gồm:
- Gắp và đặt vật thể
- Mở nắp chai
- Thao tác với công cụ
Khoảng cách giữa simulation và real-world (sim-to-real gap) được thu hẹp đáng kể nhờ policy đã robust hơn sau RL training.
So sánh với các phương pháp khác
| Phương pháp | Ưu điểm | Nhược điểm |
|---|---|---|
| SFT thuần túy | Đơn giản, ổn định | Bị giới hạn bởi dữ liệu |
| DAgger | Iterative, có expert feedback | Cần expert liên tục |
| Offline RL | Không cần environment | Khó vượt qua dữ liệu |
| Online RL from scratch | Không cần demo | Sample inefficient, cần reward engineering |
| SimpleVLA-RL | Binary reward, vượt qua demo | Cần simulation environment |
SimpleVLA-RL chiếm vị trí "sweet spot": sử dụng kiến thức từ SFT nhưng không bị giới hạn bởi nó, đồng thời không cần reward engineering phức tạp như RL truyền thống.
Hướng dẫn cài đặt và huấn luyện
Yêu cầu phần cứng
- GPU: 8x NVIDIA A800 (80GB) hoặc tương đương (A100 80GB)
- RAM: 256GB+ recommended
- Storage: 500GB+ cho checkpoints và replay buffers
- Hỗ trợ multi-node training cho scale lớn hơn
Cài đặt
# Clone repository
git clone https://github.com/PRIME-RL/SimpleVLA-RL.git
cd SimpleVLA-RL
# Tạo conda environment
conda create -n simplevla-rl python=3.10
conda activate simplevla-rl
# Cài đặt dependencies
pip install -e .
# Cài đặt veRL (RL framework)
pip install verl
# Cài đặt simulation environment (LIBERO)
pip install libero
Huấn luyện
# Huấn luyện trên LIBERO benchmark
bash examples/run_openvla_oft_rl_libero.sh
Script này sẽ:
- Load OpenVLA-OFT pretrained checkpoint
- Khởi tạo LIBERO simulation environments
- Chạy RL training loop với binary reward
- Lưu checkpoints định kỳ
Cấu hình quan trọng
Trong file config, các hyperparameter chính:
# Số environments chạy song song
num_envs: 64
# Binary reward
reward_type: "binary" # 0 hoặc 1
# KL constraint (giữ policy gần SFT)
kl_coeff: 0.01
# Training steps
total_steps: 50000
Benchmarks được hỗ trợ
- LIBERO: Suite of long-horizon manipulation tasks
- RoboTwin: Bimanual manipulation benchmark
Ý nghĩa và tương lai
Tại sao SimpleVLA-RL quan trọng?
-
Phá vỡ ceiling của SFT: Lần đầu tiên chứng minh rõ ràng rằng online RL có thể đẩy VLA vượt xa giới hạn demonstration data.
-
Democratize robot learning: Binary reward = không cần chuyên gia reward engineering. Bất kỳ ai có simulation environment đều có thể dùng.
-
Data efficiency: Cold-start từ 1 demo thay đổi hoàn toàn bài toán data collection. Thu thập 1 demo mất vài phút, thay vì hàng nghìn demo mất hàng tháng.
-
Emergent behaviors: Hiện tượng pushcut cho thấy RL có thể tạo ra hành vi mới -- robot không chỉ bắt chước, mà sáng tạo.
Hướng phát triển
Nhóm tác giả đang nghiên cứu mở rộng SimpleVLA-RL cho:
- Flow-matching RL: Áp dụng cho các kiến trúc như Pi0 và Pi0.5 sử dụng flow matching thay vì autoregressive generation
- Nhiều VLA architectures hơn: Không chỉ OpenVLA mà còn các mô hình khác như Octo, LAPA
- Sim-to-real pipeline: Tự động transfer policy từ simulation sang robot thực
Đánh giá cá nhân
SimpleVLA-RL là một trong những paper quan trọng nhất tại ICLR 2026 cho lĩnh vực robot learning. Nó giải quyết đúng vấn đề mà cộng đồng đang đau đầu: làm sao cải thiện VLA sau khi SFT đã hết room.
Điểm tôi đánh giá cao nhất là tính đơn giản -- binary reward, không trick phức tạp, không magic hyperparameter. Đây là dấu hiệu của nghiên cứu thực sự tốt: giải pháp đơn giản cho vấn đề khó.
Điểm cần lưu ý: phương pháp này vẫn cần simulation environment chất lượng cao. Nếu sim-to-real gap lớn, kết quả RL trong simulation có thể không transfer tốt ra thực tế. Nhưng với sự phát triển nhanh chóng của các simulation platform như Isaac Sim và MuJoCo, đây ngày càng ít là vấn đề.
Paper: SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning -- ICLR 2026
GitHub: PRIME-RL/SimpleVLA-RL

Bài viết liên quan
- AI cho Robot: Reinforcement Learning cơ bản -- Nền tảng RL cần biết trước khi đọc SimpleVLA-RL
- VLA Models: Vision-Language-Action cho Robot -- Tổng quan các mô hình VLA hiện tại
- Embodied AI 2026: Toàn cảnh và xu hướng -- Bức tranh lớn của AI cho robotics