Hãy tưởng tượng bạn là kỹ sư robotics, phụ trách ba hệ thống robot hoàn toàn khác nhau: cánh tay robot ALOHA dual-arm cho assembly, robot di động WidowX cho warehouse picking, và humanoid đi bộ qua hành lang. Với các VLA hiện tại, bạn cần ba model riêng biệt, ba pipeline training riêng, ba codebase riêng. Mỗi lần thêm robot mới là thêm một núi công việc.
Qwen-VLA của Alibaba muốn giải quyết chính vấn đề này: một bộ weights, nhiều robot, nhiều task.
Paper Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments (arXiv 2605.30280, submitted tháng 5/2026) đề xuất một khung thống nhất cho phép cùng một model thực hiện cả manipulation, navigation và trajectory prediction — chỉ cần thay một text prompt để chuyển đổi giữa các robot.
Vấn đề mà Qwen-VLA giải quyết
Robotics năm 2026 đang có nghịch lý: chúng ta có ngày càng nhiều VLA model mạnh — OpenVLA, π₀ (pi-zero), RDT-1B — nhưng mỗi model lại được thiết kế cho một task cụ thể hoặc một loại robot cụ thể. Muốn fine-tune cho robot mới? Train lại từ đầu. Muốn chuyển từ manipulation sang navigation? Dùng model khác.
Vấn đề ở chỗ:
- Hardware fragmentation: Mỗi robot có action space khác nhau — 7-DOF arm, differential drive, biped locomotion — nên output của model cần thay đổi theo hardware
- Task fragmentation: Manipulation (pick-and-place), navigation (waypoint following), trajectory prediction (motion planning) đều có cấu trúc output hoàn toàn khác nhau
- Data fragmentation: Dataset manipulation không thể dùng trực tiếp để train navigation và ngược lại
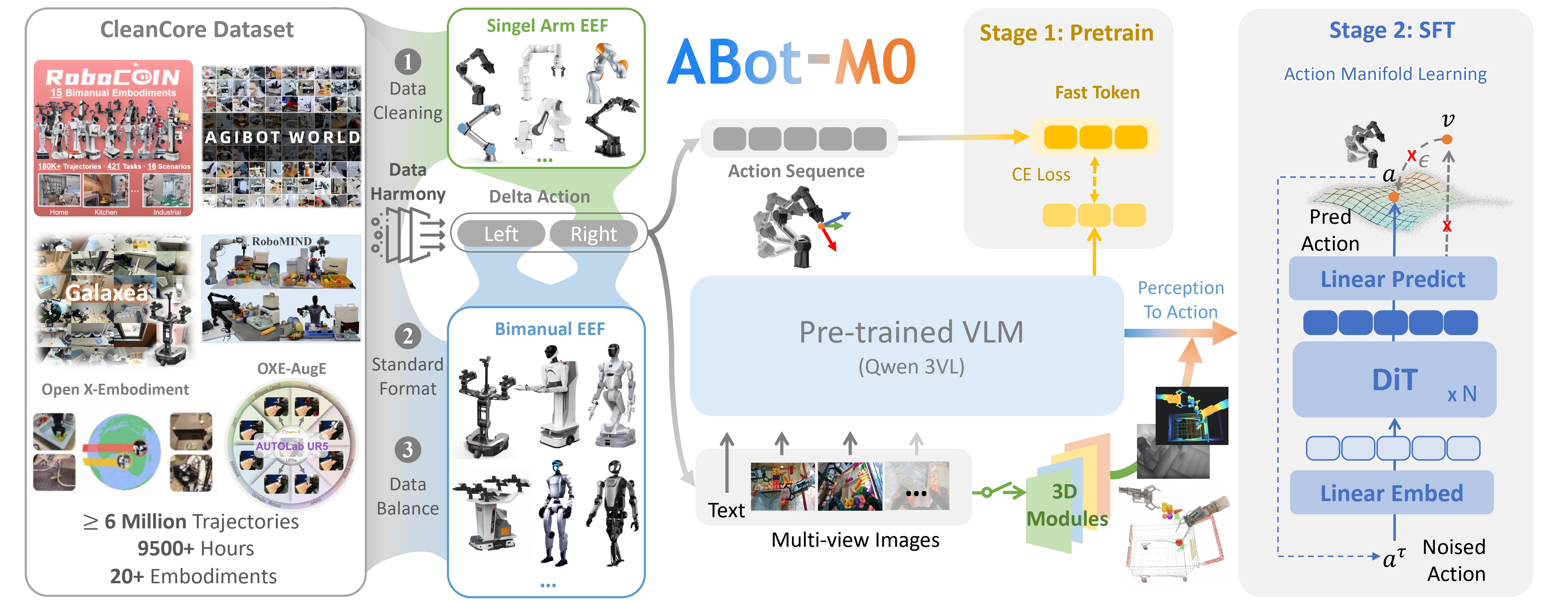
Qwen-VLA giải quyết bằng cách thiết kế một unified action-and-trajectory prediction framework — biểu diễn tất cả output (action, waypoint, trajectory) trong cùng một không gian, và dùng embodiment-aware prompt conditioning để model biết nó đang điều khiển loại robot nào.
Kiến trúc kỹ thuật
Qwen-VLA gồm hai thành phần chính ghép với nhau:
1. Vision-Language Backbone: Qwen3.5-4B
Phần "hiểu thế giới" của model dựa trên Qwen3.5-4B — mô hình ngôn ngữ-thị giác của Alibaba. Backbone này xử lý:
- Hình ảnh từ camera (RGB, depth, hoặc multi-view tùy cấu hình robot)
- Text instruction từ người dùng ("pick up the red cup and place it on the tray")
- Embodiment prompt — một đoạn text mô tả robot đang dùng, action space của nó, và convention điều khiển
Backbone Qwen3.5-4B đã được pretrain trên lượng lớn dữ liệu ngôn ngữ và thị giác, mang lại khả năng visual grounding (xác định vật thể trong không gian) và spatial reasoning (hiểu quan hệ không gian) cần thiết cho cả manipulation lẫn navigation.
2. Action Decoder: 1.15B DiT Flow-Matching
Đây là điểm đặc biệt nhất của Qwen-VLA. Thay vì dùng autoregressive decoding (predict token từng bước như LLM thông thường), họ dùng Diffusion Transformer (DiT) với flow-matching.
Flow-matching là một phương pháp generative học cách "chảy" từ noise distribution về action distribution trong ít bước hơn DDPM truyền thống. DiT action decoder có 1.15 tỷ tham số — lớn hơn nhiều so với action heads thông thường — cho phép model học các action distribution phức tạp.
Input (vision tokens + text tokens từ Qwen3.5-4B)
│
▼
DiT Action Decoder (1.15B params, flow-matching)
│
▼
Continuous action vector (7-DOF joint positions, base velocity, etc.)
Điểm mấu chốt: action decoder KHÔNG thay đổi giữa các robot. Thay vào đó, robot được phân biệt qua embodiment-aware prompt.
3. Embodiment-Aware Prompt Conditioning
Đây là cơ chế cho phép một model serve nhiều robot. Trước mỗi task, người dùng cung cấp một đoạn text mô tả robot hiện tại:
"You are controlling a 7-DOF ALOHA dual-arm robot.
The action space is [left_joint_0...6, right_joint_0...6, left_gripper, right_gripper].
Actions are in joint position space, range [-1, 1]."
Với robot navigation thì prompt khác:
"You are controlling a WidowX mobile manipulator.
The action space is [base_vx, base_vy, base_wz, arm_joint_0...5, gripper].
Navigate to the target location while avoiding obstacles."
Model học cách đọc prompt này và điều chỉnh output tương ứng. Không cần per-platform output head riêng biệt — chỉ cần thay text.
┌─────────────────────────────────────────────────────┐
│ QWEN-VLA MODEL │
│ │
│ [Camera RGB] [Depth] [Embodiment Prompt] │
│ │ │ │ │
│ └──────────────┴────────────┘ │
│ │ │
│ ┌──────────▼──────────┐ │
│ │ Qwen3.5-4B VLM │ ← Vision tokens │
│ │ Visual Grounding │ + Text tokens │
│ │ Spatial Reasoning │ │
│ └──────────┬──────────┘ │
│ │ Feature embedding │
│ ┌──────────▼──────────┐ │
│ │ DiT Action Decoder │ 1.15B params │
│ │ Flow-matching │ ← Noise input │
│ └──────────┬──────────┘ │
│ │ │
│ ┌──────────▼──────────┐ │
│ │ Action Vector │ │
│ │ (continuous, N-D) │ │
│ └─────────────────────┘ │
└─────────────────────────────────────────────────────┘
Training Pipeline
Qwen-VLA được train theo joint pretraining — tất cả loại dữ liệu cùng được dùng để train một model duy nhất. Dữ liệu bao gồm:
| Nguồn dữ liệu | Loại | Mục đích |
|---|---|---|
| Robot manipulation trajectories | Demos từ Open X-Embodiment, BridgeV2, RoboTwin | Học manipulation |
| Human egocentric videos | Video từ Ego4D, EPIC-Kitchens | Học hand-object interaction |
| Synthetic simulation data | Isaac Sim, MuJoCo rollouts | Augmentation, rare scenarios |
| Vision-language navigation data | R2R, RxR, NavInstruct | Học navigation |
| Trajectory-centric supervision | Keypoint tracks, optical flow | Học trajectory prediction |
| Auxiliary VLM data | VQA, captioning | Duy trì visual grounding |
Chiến lược train gồm hai giai đoạn:
-
Pretraining: Train trên toàn bộ dữ liệu trên với mixed-task batching. Model học các skill cơ bản: nhận diện vật thể, follow instruction, sinh action.
-
Instruction tuning (Instruct variant): Fine-tune trên high-quality task-specific data để cải thiện instruction following và generalization.
Kết quả: Qwen-VLA-Base (sau giai đoạn 1) và Qwen-VLA-Instruct (sau giai đoạn 2). Có thêm Qwen-VLA-aloha — biến thể pretrain thêm trên dữ liệu ALOHA real-robot.
Cài đặt và Sử dụng
Yêu cầu hệ thống
# Python 3.10+, CUDA 12.1+, GPU >= 24GB VRAM (cho Instruct)
# hoặc >= 16GB với quantization
# Clone repo
git clone https://github.com/QwenLM/Qwen-VLA.git
cd Qwen-VLA
# Tạo môi trường conda
conda create -n qwen-vla python=3.10
conda activate qwen-vla
# Cài dependencies
pip install -r requirements.txt
Load Model
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
# Load Qwen-VLA-Instruct
model_name = "Qwen/Qwen-VLA-Instruct"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="cuda"
)
Inference với Embodiment Prompt
from PIL import Image
import torch
# Embodiment prompt cho ALOHA robot
embodiment_prompt = """You are controlling a 7-DOF ALOHA dual-arm robot.
Action space: [left_joint_0..6, right_joint_0..6, left_gripper, right_gripper].
Actions are normalized joint positions in range [-1, 1]."""
# Task instruction
task = "Pick up the yellow cup and place it on the white plate."
# Chuẩn bị input
image = Image.open("camera_frame.jpg")
messages = [
{
"role": "system",
"content": embodiment_prompt
},
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": task}
]
}
]
# Tokenize
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = processor(
text=[text],
images=[image],
return_tensors="pt"
).to("cuda")
# Generate action (flow-matching inference)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=64,
do_sample=False
)
# Decode thành action vector
action = processor.decode_action(outputs[0])
print(f"Action: {action}")
# Output: tensor([0.12, -0.03, 0.45, ...]) — 14-dim ALOHA action
Chuyển sang Navigation Robot
# Chỉ cần thay embodiment prompt — model weights KHÔNG đổi
embodiment_prompt = """You are controlling a WidowX mobile robot.
Action space: [base_x_vel, base_y_vel, base_theta_vel, arm_joint_0..5, gripper].
Navigate to target location while avoiding obstacles."""
task = "Navigate to the kitchen counter and pick up the bottle."
# Inference hoàn toàn giống trên — chỉ prompt thay đổi
Xem thêm về fine-tuning model VLA cho task cụ thể trong bài hướng dẫn fine-tune Embodied-R1.5 trên LIBERO.
Kết quả Benchmark
Qwen-VLA-Instruct đạt kết quả ấn tượng trên cả ba loại task:
Manipulation Benchmarks
| Benchmark | Qwen-VLA-Instruct | Baseline tốt nhất | Cải thiện |
|---|---|---|---|
| LIBERO | 97.9% | 95.2% (π₀.5) | +2.7% |
| Simpler-WidowX | 73.7% | 71.6% (π₀.5) | +2.1% |
| RoboTwin-Easy | 86.1% | 81.0% | +5.1% |
| RoboTwin-Hard | 87.2% | 79.3% | +7.9% |
| DOMINO (zero-shot) | 26.6% | 18.2% | +8.4% |
DOMINO là benchmark đặc biệt thú vị — dynamic manipulation với vật thể chuyển động, test zero-shot. Cải thiện 8.4% điểm phần trăm so với baseline cho thấy Qwen-VLA generalize tốt hơn đáng kể.
Navigation Benchmarks
| Benchmark | Qwen-VLA-Instruct | Mô tả |
|---|---|---|
| R2R (OSR) | 69.0% | Vision-Language Navigation trong môi trường 3D |
| RxR (SR) | 59.6% | Multilingual navigation benchmark |
Điều đáng chú ý là đây là cùng một model thực hiện cả manipulation lẫn navigation — không phải hai model riêng biệt được fine-tune riêng.
Real-World ALOHA
| Điều kiện | Success Rate |
|---|---|
| In-distribution (in-domain) | 83.6% |
| Out-of-distribution (OOD) | 76.9% |
Qwen-VLA-aloha (với pretraining ALOHA) đạt 76.9% OOD success — tức là robot vẫn hoạt động tốt khi bàn được xê dịch, thay đổi màu vật thể, hay đổi vị trí camera. Điều này rất quan trọng cho deployment thực tế.
Qwen-RobotSuite: Bước tiến tiếp theo (tháng 6/2026)
Sau khi ra mắt Qwen-VLA, đội ngũ Qwen tiếp tục với Qwen-RobotSuite (tháng 6/2026) — bộ ba model chuyên biệt hơn:
Qwen-RobotManip
VLA cho manipulation, cải tiến từ Qwen-VLA:
- 80-dimensional canonical action space với per-dimension binary masking — một trick hay: action space được chuẩn hóa thành 80 chiều cố định, nhưng dimension nào không dùng sẽ bị mask. ALOHA dùng 14 chiều (7+7 joints), WidowX dùng 8 chiều — cùng model, khác mask.
- In-context policy adaptation: Cho model xem 1-3 demo ngắn của task mới để adapt mà không cần fine-tune
- Camera-frame delta pose parameterization: Action được tính theo góc nhìn camera thay vì base frame — giảm variance khi camera dịch chuyển
Kết quả: #1 trên RoboChallenge Table30-v1 (benchmark tổng hợp của cộng đồng); 91.4% trên LIBERO-Plus (so với 84.4% SOTA cũ); 69.4% trên RoboTwin-C2R Hard (so với 47.9%).
Qwen-RobotNav
Navigation model với Qwen3-VL backbone (2B/4B/8B):
- Dự đoán 8 waypoints cùng lúc thay vì từng bước một
- Cải thiện HM-EQA (Embodied QA) +10.8%, EXPRESS-Bench +15.4%
- Giảm 77% số bước navigation cần thiết
Qwen-RobotWorld
Video world model (20B tham số) — predict video tương lai từ action. Đây là thành phần thứ ba trong hệ sinh thái, cho phép robot "tưởng tượng" kết quả của action trước khi thực thi.
So sánh với các VLA Model khác
| Model | Backbone | Action Decoder | Cross-embodiment | Multi-task |
|---|---|---|---|---|
| OpenVLA | Prismatic-7B | MLP (discrete) | ❌ Không | ❌ Không |
| π₀ (pi-zero) | PaliGemma-3B | Flow-matching | ❌ Limited | ✅ Có |
| RDT-1B | T5-Large | DiT | ❌ Không | ✅ Có |
| HEX-VLA | Qwen3-VL | VQ-VAE | ✅ Có | ✅ Có |
| Qwen-VLA | Qwen3.5-4B | DiT Flow-matching | ✅ Có | ✅ Có |
Qwen-VLA nổi bật ở chỗ kết hợp được cả cross-embodiment lẫn multi-task trong một model. Đây là điều mà phần lớn VLA model trước đây không làm được đồng thời.
Về cross-embodiment, hãy so sánh với bài viết về HEX-VLA cross-embodiment humanoid — một hướng tiếp cận khác cũng đang được nghiên cứu mạnh trong cộng đồng.
Nhận xét và Hướng phát triển
Điểm mạnh:
- Một bộ weights thực sự phục vụ nhiều robot và nhiều task
- Embodiment-aware prompt đơn giản nhưng hiệu quả — không cần thay đổi kiến trúc khi thêm robot mới
- DiT action decoder cho phép action distribution phức tạp hơn so với MLP head
Điểm cần chú ý:
- Model lớn (Qwen3.5-4B backbone + 1.15B DiT = ~5.15B tham số) — cần GPU đủ VRAM
- Embodiment prompt phải được viết cẩn thận — nếu prompt mô tả sai action space, robot sẽ hành động sai
- DOMINO zero-shot 26.6% vẫn còn thấp — dynamic manipulation vẫn là thách thức lớn
Hướng phát triển tiếp theo:
- Tích hợp với Qwen-RobotWorld để có world model-based planning
- Quantization để deploy trên edge device (Jetson Orin) với model nhỏ hơn
- Thêm haptic feedback và proprioception vào input stream
Nếu bạn muốn hiểu thêm về cách các VLA model hiện đại được thiết kế, bài LabVLA với Qwen3-VL cung cấp một góc nhìn khác về việc dùng Qwen3 làm backbone cho robot.
Kết luận
Qwen-VLA đánh dấu một bước tiến quan trọng trong hướng "generalist robot brain" — thay vì mỗi robot có VLA riêng, một model duy nhất có thể phục vụ nhiều platform chỉ qua thay đổi text prompt. Kết quả benchmark ấn tượng (97.9% LIBERO, 76.9% ALOHA OOD) và mã nguồn mở hoàn toàn làm Qwen-VLA trở thành baseline quan trọng để tham khảo cho bất kỳ dự án VLA nào năm 2026.
GitHub: QwenLM/Qwen-VLA — Paper: arXiv 2605.30280