MPC-RL giải quyết vấn đề gì?
Repo junhengl/mpc-rl đi kèm paper Accelerating and Scaling MPC-Guided Reinforcement Learning for Humanoid Locomotion and Manipulation của Junheng Li, Liang Wu, Sergio A. Esteban, Lizhi Yang, Ján Drgoňa và Aaron D. Ames. Paper được đưa lên arXiv ngày 2026-06-04, tập trung vào một câu hỏi rất thực tế: có thể dùng Model Predictive Control (MPC) để hướng dẫn Reinforcement Learning (RL) trong lúc training, nhưng không phải chạy MPC khi deploy robot thật hay không?
Đây là một hướng rất đáng chú ý cho humanoid. Pure RL có thể tạo ra policy mạnh, nhưng reward cho humanoid thường khó thiết kế: chỉ thưởng tracking velocity thì robot có thể học dáng đi không tự nhiên; phạt foot slip thì chưa chắc hiểu constraint contact; thưởng đứng thẳng thì chưa đủ để robot biết nên đặt chân ở đâu sau 0,5 giây nữa. MPC thì ngược lại: nó có mô hình dynamics, biết contact force, biết constraint friction, biết nhìn trước theo horizon. Nhưng MPC online cho humanoid full-body rất nặng, nhất là khi cần chạy real-time.
MPC-RL trong paper này chọn một cách kết hợp khá pragmatic:
- Trong training, một centroidal MPC chạy song song cho từng environment.
- MPC sinh ra trajectory tham chiếu: CoM, linear momentum, angular momentum, ground reaction force, foot placement và trong task pushing có thêm hand force.
- Những trajectory này được chuyển thành reward và privileged critic input cho PPO.
- Khi deploy, policy chỉ cần proprioception, command và phase clock. Không cần MPC trong loop inference.
Nếu bạn đã đọc bài RL cho Robotics: PPO, SAC và cách chọn algorithm, có thể xem MPC-RL là một cách làm reward shaping có cấu trúc vật lý rõ hơn. Nếu đã quen với Whole-Body MPC, điểm mới ở đây là MPC không trực tiếp điều khiển robot ở runtime, mà đóng vai trò "teacher" trong training.
Kiến trúc tổng thể
Paper gọi phương pháp này là training-time MPC guidance. Sơ đồ dưới đây từ repo cho thấy pipeline chính: simulator tạo rollout, MPC tạo reference theo từng environment, reward dùng các landmark từ MPC, PPO update actor/critic, rồi policy cuối cùng được export để chạy độc lập.
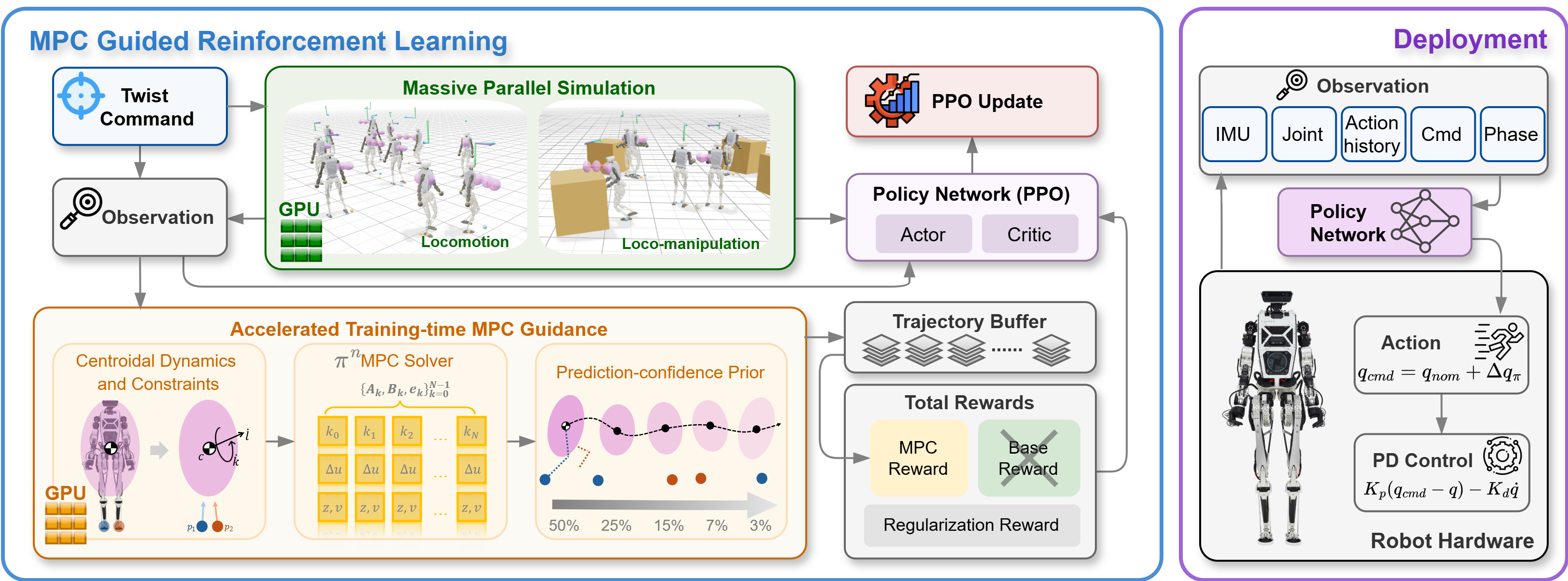
Hãy tách kiến trúc thành bốn khối để beginner dễ follow.
Khối 1: Humanoid environment. Repo dùng mjlab, MuJoCo, mujoco-warp, PyTorch và rsl_rl. Robot mục tiêu là Westwood Robotics Themis V2, có 29 action dimensions trong policy. Action không phải torque thô, mà là joint-position delta quanh default pose, sau đó được joint PD controller tracking. Cách này quan trọng vì nó làm policy dễ deploy hơn: actor output giống lệnh position offset, còn motor-level stabilization do PD lo.
Khối 2: Centroidal Dynamics MPC. MPC không mô phỏng full body với toàn bộ joint. Nó dùng centroidal state 9 chiều:
xi = [ CoM position c,
centroidal linear momentum l_G,
centroidal angular momentum k_G ]
Với locomotion, control của MPC là contact wrench ở hai bàn chân. Với loco-manipulation, MPC mở rộng thêm lực tay trái và tay phải khi robot đẩy vật. Mô hình này giảm độ phức tạp rất nhiều so với full-body MPC, nhưng vẫn giữ thông tin quan trọng nhất cho balance: CoM đi đâu, momentum tăng giảm thế nào, ground reaction force có hợp friction cone hay không.
Khối 3: π^n MPC solver. Nếu có 4096 environments, chạy 4096 MPC solvers tuần tự là không thực tế. Paper phát triển π^n MPC, một solver batched GPU, parallel theo cả environment và prediction horizon. Nó tránh bước build sparse QP lớn cho từng update, hoạt động trực tiếp trên dynamics time-varying, và dùng variable splitting kiểu ADMM để các update theo horizon có thể chạy song song.
Khối 4: PPO policy. Actor chỉ thấy tín hiệu deploy được: IMU angular velocity, projected gravity, joint position/velocity, previous action, velocity command và phase clock sin(phi), cos(phi). Critic được đặc quyền thấy thêm base velocity, foot clearance và reference từ MPC. Đây là asymmetric actor-critic: critic được nhiều thông tin để học value tốt hơn, actor vẫn giữ input thực tế cho robot thật.
MPC landmark reward: tại sao không chỉ track bước kế tiếp?
Một sai lầm phổ biến khi dùng MPC làm teacher là lấy output ngay bước kế tiếp rồi bắt policy track nó. Cách này bỏ phí phần "predictive" của MPC. MPC đã solve một horizon, ví dụ N = 10 với dt = 0.07 s, tức nhìn trước khoảng 0.7 s. Nếu chỉ dùng điểm đầu tiên, policy chỉ học phản ứng ngắn hạn.
MPC-RL lấy một tập landmark từ toàn trajectory. Khi rollout đi đến một thời điểm nào đó, policy được thưởng nếu CoM, CoM velocity và angular momentum của nó khớp với những gì MPC đã dự đoán trước đó cho cùng thời điểm. Reward có dạng trực giác:
reward_mpc_com = exp(- sum_l alpha_l * error_l^2 / sigma^2)
alpha_l là trọng số theo horizon. Paper dùng lịch tapered: gần hiện tại thì trọng số cao hơn, xa tương lai thì thấp hơn, cụ thể dạng 0.5, 0.25, 0.15, 0.07, 0.03. Lý do hợp lý: dự đoán gần thường đáng tin hơn vì ít chịu model mismatch; dự đoán xa vẫn hữu ích vì cho policy biết hướng động học dài hơn.
Với locomotion, reward stack gồm:
| Nhóm reward | Ý nghĩa |
|---|---|
mpc_com |
CoM track các landmark MPC |
mpc_lin_vel |
Linear velocity của CoM theo MPC |
mpc_ang_mom |
Giữ angular momentum gần reference |
mpc_foot |
Foot placement theo mục tiêu landing |
mpc_grf |
Ground reaction force gần nghiệm MPC |
| regularization | pose, gait, foot clearance, joint limit, self collision, action rate |
Điểm quan trọng là MPC reward thay thế một phần base reward như velocity tracking và angular momentum regularizer, chứ không chỉ cộng thêm một reward nhỏ. Nhờ vậy ablation giữa pure RL và MPC-RL công bằng hơn: cùng regularization, khác ở tín hiệu dẫn đường chính.
π^n MPC: lý do paper nhấn mạnh "scaling"
Trong RL cho robot, training scale thường là hàng nghìn environments. Repo mặc định train với 4096 parallel environments. Nếu mỗi control step lại phải build QP, compile symbolic graph hoặc giải horizon tuần tự, overhead của MPC sẽ nuốt hết lợi ích.
Biểu đồ dưới đây từ repo so sánh solve time của các batch QP/MPC solver khác nhau khi tăng số environment và horizon. Ý chính: π^n MPC giữ được tính khả thi ở horizon dài hơn, trong khi một số solver khác chậm mạnh hoặc hết VRAM.
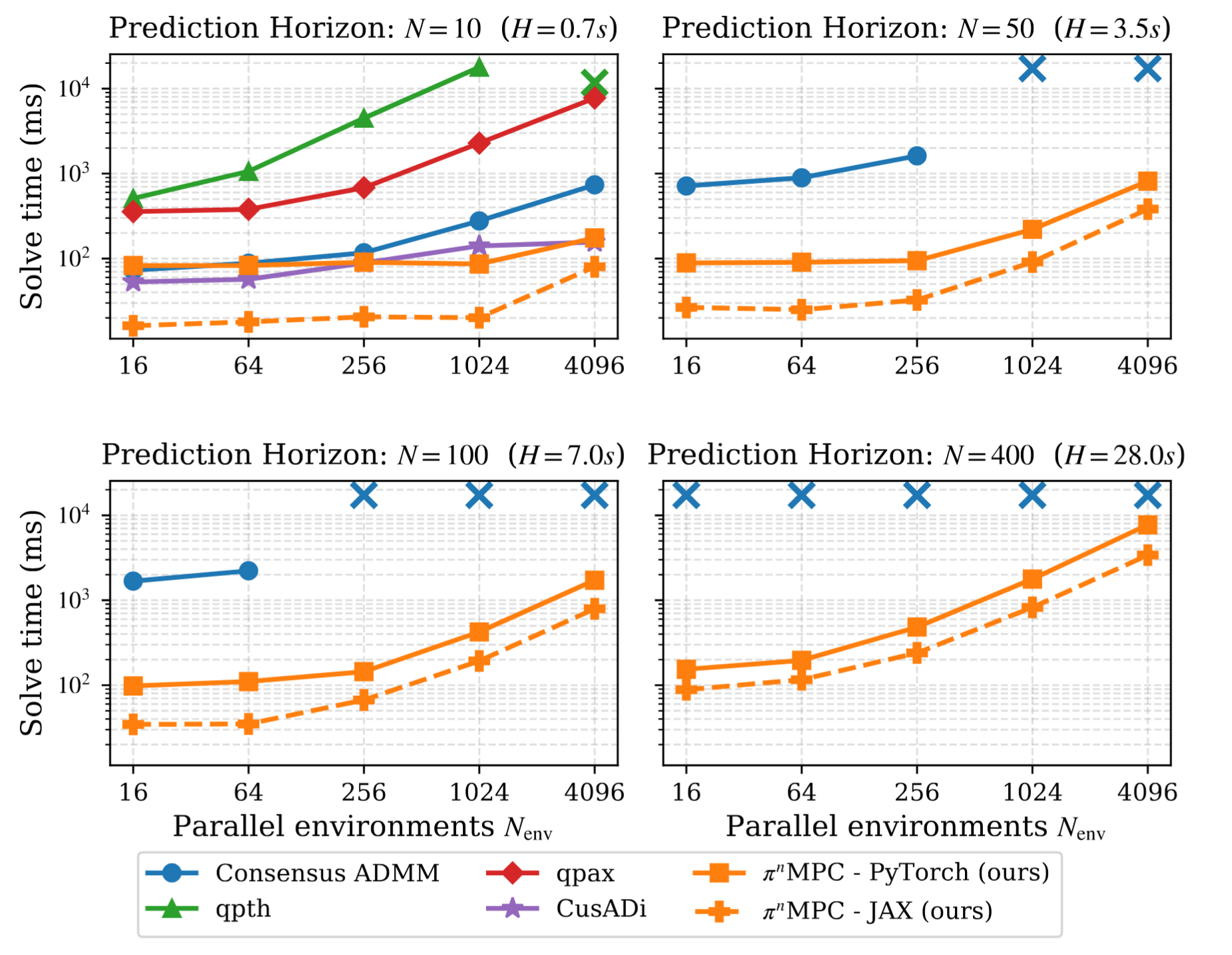
Trong paper, authors so sánh với consensus ADMM, qpth, qpax và CusADi. CusADi có tốc độ solve cạnh tranh ở một vài setup, nhưng phần symbolic compilation cho bài toán MPC mất khoảng 1,5 giờ và cần rất nhiều RAM ở cấu hình được báo cáo. π^n MPC tránh cách build problem như vậy. Nó expose horizon như một batch dimension, dùng batched operations chuẩn trên GPU, và có cả backend JAX lẫn PyTorch trong repo.
Với người mới, bạn có thể nhớ ngắn gọn:
Pure MPC online:
solve optimization every robot control cycle at deployment
MPC-RL:
solve many lightweight MPC problems during training
convert MPC plans into reward and critic guidance
deploy only neural policy
Đây là khác biệt lớn với các hệ thống MPC truyền thống. Về simulation stack, team dùng MuJoCo-Warp/mjlab để giữ physics và GPU training đi cùng nhau.
Cài đặt repo
Repo yêu cầu Python 3.11 đến 3.13 và CUDA 12 GPU. pyproject.toml pin khá chặt các dependency chính:
| Package | Version trong repo | Vai trò |
|---|---|---|
mjlab |
1.2.0 |
RL training framework, task registry |
mujoco |
3.6.0 |
Physics engine |
mujoco-warp |
3.6.0 |
GPU simulation stack |
warp-lang |
1.12.0 |
Warp backend tương thích mjlab |
torch |
2.10.0 |
PPO, tensors, PyTorch solver |
jax[cuda12] |
0.10.0 |
JAX backend cho PiMPC |
Lệnh setup trong README rất ngắn:
git clone https://github.com/junhengl/mpc-rl
cd mpc-rl
uv sync
Nếu bạn chạy trên máy workstation cá nhân, hãy kiểm tra ba thứ trước:
- Driver NVIDIA đủ mới cho CUDA 12.
uvđã được cài.- GPU có đủ VRAM cho số environment bạn chọn.
README dùng RTX 5090 32 GB trong experiment. Nếu GPU của bạn yếu hơn, giảm --env.scene.num-envs trước. Beginner nên bắt đầu với 512 hoặc 1024 environments để kiểm tra pipeline, sau đó tăng dần. Không nên copy ngay 4096 nếu chưa biết memory footprint.
Training locomotion
Task locomotion trong repo có tên:
Mjlab-MPC-Guided-Locomotion-Themis
Lệnh training mặc định:
CUDA_VISIBLE_DEVICES=0 uv run train Mjlab-MPC-Guided-Locomotion-Themis \
--env.scene.num-envs 4096 \
--agent.max-iterations 15000
Trong paper, physics được integrate ở 200 Hz, control rate là 50 Hz, episode dài tối đa 20 s, tương đương 1000 control steps. PPO dùng actor và critic MLP độc lập với hidden width 512, 256, 128, activation ELU, Gaussian action distribution và learnable scalar standard deviation.
Nếu giải thích theo workflow:
- Simulator tạo 4096 bản sao environment.
- Mỗi environment có command vận tốc khác nhau.
- Theo chu kỳ MPC,
CentroidalMPClấy state hiện tại, contact schedule và velocity command. - MPC solve horizon để tạo reference CoM, momentum, foot force.
- Reward manager tính các term
mpc_com,mpc_lin_vel,mpc_ang_mom,mpc_foot,mpc_grf. - PPO update policy từ rollout.
- Sau nhiều iteration, actor học cách tạo joint-position delta bám theo cấu trúc MPC nhưng không cần gọi MPC.
Điểm beginner hay bỏ qua là run_every_n_steps. Trong config, MPC không nhất thiết solve ở mọi physics step. Với control rate 50 Hz, setup default paper chọn MPC horizon N = 10, update 10 Hz. Nghĩa là MPC tạo guidance đủ thường xuyên để hữu ích, nhưng không quá dày khiến training chậm và reward quá cứng.
Training loco-manipulation
Task thứ hai:
Mjlab-MPC-Guided-Loco-manipulation-Themis
Lệnh training:
CUDA_VISIBLE_DEVICES=0 uv run train Mjlab-MPC-Guided-Loco-manipulation-Themis \
--env.scene.num-envs 4096 \
--agent.max-iterations 25000
Task này là walking while pushing a box. So với locomotion, MPC thêm biến lực tay. Trong LocoManipMPCConfig, repo có các tham số như mu_hand, f_hand_max, R_f_hand, R_hand_balance. Input của loco-manip MPC cũng chứa hand pose, hand contact gate, force/torque ngoài thân và box resistance force.
Về mặt học, điều này rất quan trọng. Pure RL cho pushing dễ rơi vào exploration xấu: robot đi đến vật nhưng không giữ contact đủ lâu, hoặc đẩy lệch hướng, hoặc hy sinh balance để tạo lực. MPC-guided reward đưa vào tín hiệu vật lý: CoM nên nằm đâu khi sinh lực đẩy, momentum nên thay đổi thế nào, lực tay nên cân bằng ra sao, và foot contact nên hỗ trợ hướng đẩy như thế nào.
Paper nhấn mạnh rằng policy loco-manipulation dùng cùng observation space với locomotion policy và không cần object state runtime như pure MPC. Đây là điểm triển khai đáng giá: ở inference, robot không cần một perception stack hoàn hảo để đo mass hoặc full state của object; policy đã học cấu trúc đẩy trong training.
Resume checkpoint và inference
README cho ví dụ resume:
CUDA_VISIBLE_DEVICES=0 uv run train Mjlab-MPC-Guided-Locomotion-Themis \
--agent.resume True \
--agent.load-run "2026-05-08_22-55-00" \
--agent.load-checkpoint model_5000.pt
Để play back một policy đã train:
uv run play Mjlab-MPC-Guided-Locomotion-Themis --wandb-run-path <entity/project/run-id>
Khi chuyển từ training sang inference, cần nhớ một nguyên tắc: MPC chỉ là training teacher. Actor deploy chỉ cần những observation deploy được:
actor_obs =
IMU trunk angular velocity
projected gravity
joint positions relative to default
joint velocities relative to default
previous action
velocity command
phase clock
Critic và MPC reference không đi ra robot thật. Vì vậy nếu bạn port ý tưởng sang robot khác, phần cần match cẩn thận nhất là action interface, joint PD gains, sensor normalization và phase/gait schedule. Paper còn có một phần riêng về chọn PD gain dựa trên effective inertia: thay vì đặt gain quá cứng như servo, họ chọn natural frequency thấp hơn cho Themis vì actuator có inertia cao và gear ratio thấp. Điều này giúp tránh chatter ở hip và knee khi deploy hardware.
Kết quả chính
Kết quả của paper có bốn nhóm đáng nhớ.
1. Velocity tracking tốt hơn pure RL. Trong bảng comparison, pure RL có RMSE vx = 0.1609, vy = 0.1566, wz = 0.0912. MPC-RL default N = 10, 10 Hz đạt vx = 0.1280, vy = 0.1326, wz = 0.0928. Lợi ích rõ nhất nằm ở translational velocity, kể cả command out-of-distribution cao hơn 50% so với range training.
2. Push recovery tốt hơn ở hầu hết hướng. Pure RL chịu được lực đẩy tối đa khác nhau theo hướng, ví dụ 300 N ở 0 độ, 100 N ở 90 độ, 350 N ở 180 độ, 125 N ở 270 độ. MPC-RL default cải thiện nhiều hướng: 375 N ở 0 độ, 125 N ở 90 độ, 450 N ở 180 độ, và một số setup khác đạt 300 N ở 270 độ. Ý nghĩa thực tế: policy học balance strategy có cấu trúc contact tốt hơn, không chỉ bám velocity command.
3. Horizon dài hơn không luôn tốt hơn. Paper thử N = 10, 30, 50 ở update rate 10 Hz. Kết quả cho thấy N = 10 là cấu hình default tốt nhất tổng thể. Một horizon dài hơn có lookahead xa hơn, nhưng model mismatch và reward delay cũng tăng. Với locomotion Themis, một gait cycle lookahead đủ tốt.
4. Loco-manipulation đẩy được tải rất nặng. Trong simulation, MPC-RL đẩy box 20 kg, kích thước 1 m x 1 m x 1 m, friction coefficient 0.2, và tracking velocity tốt hơn pure RL vốn bị stall từ đầu. Trên hardware, robot đẩy được cart payload tới 290 kg, tương đương 829% body mass, với lực đẩy đo được khoảng 180 N. Đây là claim nổi bật nhất của paper vì nó cho thấy MPC guidance không chỉ cải thiện dáng đi, mà còn giúp học contact-rich manipulation bằng toàn thân.
Nên đọc repo như thế nào?
Nếu bạn muốn học từ code thay vì chỉ chạy command, thứ tự đọc nên là:
| File/thư mục | Nên đọc để hiểu |
|---|---|
README.md |
task names, setup, training commands |
src/themis_mpc/centroidal_mpc.py |
MPCConfig, CentroidalMPC, foot contact constraints |
src/themis_mpc/loco_manip_mpc.py |
mở rộng thêm hand force cho pushing |
src/themis_training/mpc_grf_mdp.py |
cách MPC chạy như command term trong environment |
src/themis_training/env_cfgs.py |
reward terms, observation noise, domain randomization |
pyproject.toml |
dependency versions và entry point mjlab.tasks |
Beginner nên bắt đầu bằng cách chạy play với policy có sẵn nếu authors publish checkpoint, hoặc giảm số env để test training loop. Khi loop đã chạy ổn, mới tune MPC horizon, update rate, solver_type và reward weight. Nếu bạn đang học nền tảng simulation trước, hãy nắm MuJoCo cơ bản trước khi đọc sâu solver.
Khi nào nên dùng ý tưởng MPC-RL?
MPC-RL phù hợp khi bài toán có ba điều kiện:
- Bạn có reduced-order model đủ tốt để tạo guidance.
- Reward thuần RL khó encode contact, momentum hoặc long-horizon behavior.
- Deployment không muốn chạy optimizer nặng trong real-time loop.
Nó không phải silver bullet. Nếu robot của bạn thiếu simulator chính xác, contact schedule sai hoàn toàn, hoặc action interface không ổn định, MPC reward có thể dạy policy bám một teacher không phù hợp. Paper cũng nêu limitation: centroidal dynamics là reduced-order model, contact schedule còn prescribed, và numerical solver vẫn có scaling limit. Hướng future work của authors là nonlinear MPC giàu contact mode hơn và neural-network-augmented batch MPC solvers.
Tuy vậy, contribution của repo rất rõ: nó biến MPC từ một controller online nặng thành một nguồn reward có cấu trúc trong training. Với humanoid, nơi reward design thường quyết định thành bại, đây là một pattern rất đáng học.