Vì sao G0Tiny đáng chú ý?
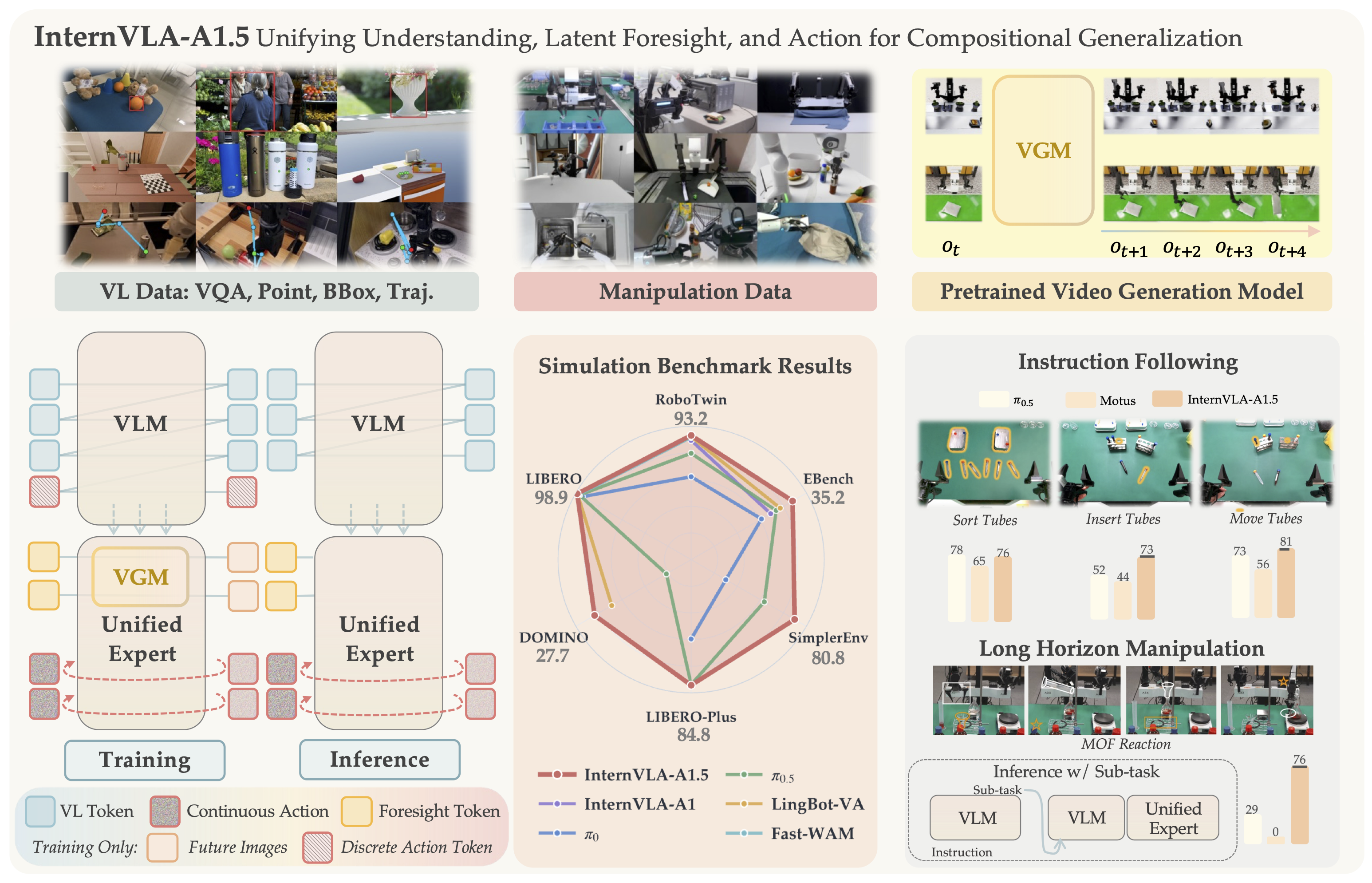
GalaxeaVLA là repo open-source của OpenGalaxea cho các mô hình Vision-Language-Action trong robot manipulation thực tế. Dòng G0 được mô tả trong paper Galaxea Open-World Dataset and G0 Dual-System VLA Model: hệ thống tách planner Vision-Language Model ở tầng cao và executor Vision-Language-Action ở tầng thấp. Planner hiểu scene, chia lệnh người dùng thành subtask; VLA nhận camera, proprioception và subtask language để sinh action chunk liên tục cho robot.
G0Tiny là biến thể nhỏ hơn, khoảng 250M parameters, được release trong repo OpenGalaxea/GalaxeaVLA. Theo README của dự án, checkpoint G0Tiny_250M-base nhắm tới edge deployment trên R1 Pro Orin, dùng backbone SmolVLM2 và có demo on-device bằng TensorRT lên tới 10 Hz cho tác vụ handover gift. Điểm hấp dẫn là nó nhỏ hơn G0Plus 3B rất nhiều nhưng vẫn theo cùng triết lý: học từ real robot data, dùng LeRobot-format dataset, rồi fine-tune cho task cụ thể.
Bài này không giả định bạn đã từng train VLA. Ta sẽ đi từ ý tưởng paper, kiến trúc, chuẩn dataset LeRobot, setup, training, inference đến cách đọc kết quả. Nếu bạn có robot khác R1 Pro, bài này vẫn hữu ích, nhưng bạn cần adapter cho action/state/camera của robot đó. G0Tiny config public hiện phù hợp nhất với dữ liệu kiểu R1 Pro hoặc dataset đã map về cùng schema.
Ý tưởng paper: dual-system thay vì một model làm tất cả
Paper G0 bắt đầu từ một vấn đề quen thuộc: robot trong nhà, văn phòng, cửa hàng hay bếp không chỉ cần pick-and-place đơn giản. Nó phải hiểu lệnh dài, nhận ra object trong scene lộn xộn, chọn chuỗi subtask hợp lý, rồi điều khiển arm, gripper, torso hoặc mobile base mượt mà. Nếu ép một VLA duy nhất làm cả planning dài hạn và low-level control, training trở nên nặng, inference khó ổn định, và lỗi language grounding có thể biến thành lỗi chuyển động nguy hiểm.
G0 chia bài toán thành hai hệ:
Human command
|
v
+--------------------+
| System 2: G0-VLM | slow planner
| scene + language |
| -> subtask plan |
+--------------------+
|
| "pick up the cup", "move torso down", ...
v
+--------------------+
| System 1: G0-VLA | fast executor
| images + state |
| + subtask text |
| -> action chunk |
+--------------------+
|
v
Robot controller
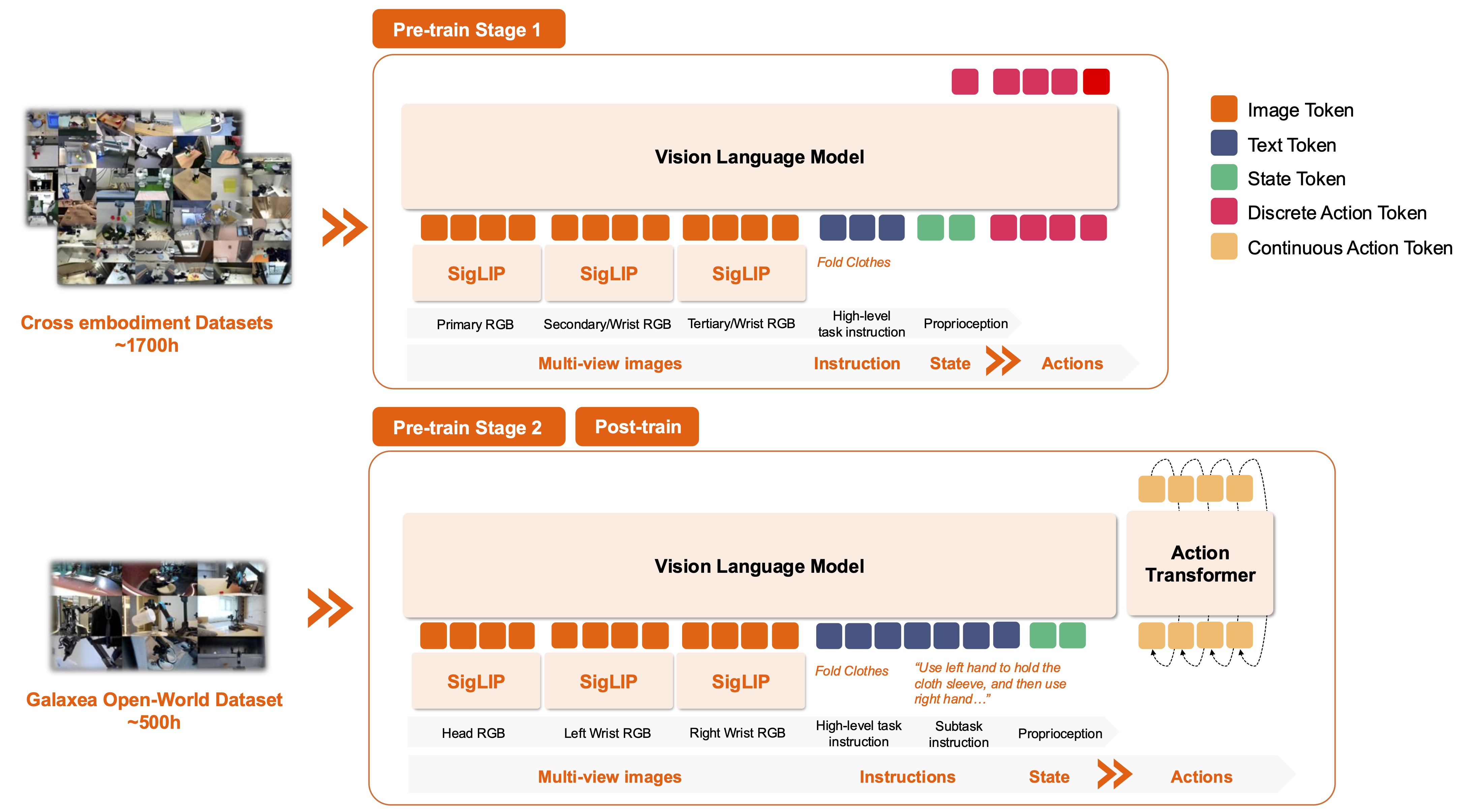
Trong paper, G0-VLA được train theo curriculum ba giai đoạn. Stage 1 dùng cross-embodiment robot data để học prior thị giác-ngôn ngữ-hành động ở mức rộng. Stage 2 dùng Galaxea Open-World Dataset cùng một embodiment để model học dynamics, camera viewpoint và action space cụ thể. Post-training dùng một số ít demonstration chất lượng cao để thành thạo task đích. Kết luận quan trọng của paper là single-embodiment pre-training có vai trò rất lớn: nếu pre-train trên embodiment quá khác, lợi ích có thể giảm hoặc thậm chí gây nhiễu cho các action đặc thù như torso/chassis.
Với người fine-tune, thông điệp thực tế là: đừng chỉ hỏi "dataset có bao nhiêu giờ?". Hãy hỏi "dataset có giống robot, camera, action space và task thật của mình không?". G0Tiny nhỏ, nên càng cần dữ liệu sạch, nhất quán và annotation rõ.
Kiến trúc G0Tiny nhìn từ config public
Repo GalaxeaVLA có config configs/model/vla/g0tiny.yaml. Các chi tiết đáng chú ý:
| Thành phần | Giá trị/ý nghĩa thực tế |
|---|---|
| Backbone | HuggingFaceTB/SmolVLM2-500M-Video-Instruct được dùng làm pretrained model path/tokenizer path |
| Vision encoder | SigLIP-style vision transformer, image size 512, patch size 16, hidden size 768 |
| Text/VLM hidden | joint VLM hidden size 960 |
| Action expert | hidden size 720, 16 layers, flow matching action generation |
| Input images | obs_size * num_output_cameras; R1 Pro config dùng 1 observation step và 3 camera |
| Action horizon | action_size: 32, tức model dự đoán một chunk 32 bước |
| Training | batch size mặc định 16, 4 epochs, learning rate 6e-5, cosine scheduler, bf16 enabled |
| Inference steps | num_inference_steps: 10 cho flow sampling |
G0Tiny không sinh action bằng cách autoregressive từng token rời rạc ở giai đoạn executor cuối. Nó dùng VLM để encode ảnh, instruction và state; sau đó action expert sinh continuous action chunk bằng flow matching. Cách này hợp với robot control vì action là số thực: pose, gripper, torso, hoặc velocity. Với R1 Pro data config r1pro/eef_torso, action gồm left/right end-effector pose, gripper và torso. Pose quaternion được transform sang rotation 6D, action/state được normalize theo thống kê dataset, và ảnh từ head + two wrist cameras được resize về input size của model.
Một cách hình dung đơn giản:
head_rgb left_wrist_rgb right_wrist_rgb
| | |
+----------------+--------------------+
|
Vision encoder
|
Language subtask -> tokenizer -> joint VLM cache
Robot state -------> proprio encoder
|
Flow action expert
|
32-step continuous action chunk
Vì action chunk dài 32 bước, inference không cần gọi model cho từng control tick. Trong deployment thật, controller thường lấy action chunk, post-process bằng smoothing/spline, thực thi một phần chunk, rồi replan bằng quan sát mới. Điều này giảm jitter nhưng vẫn giữ phản ứng với scene.
Dataset LeRobot cần trông như thế nào?
Galaxea docs nói dataset của họ dựa trên LeRobot v2.1 và adapter BaseLerobotDataset. Cấu trúc tối thiểu gồm metadata, parquet cho non-video fields và mp4 cho camera streams. LeRobot docs của Hugging Face cũng nhấn mạnh cách lưu video trong videos/ và dữ liệu frame/action trong parquet để load hiệu quả.
my_task_dataset/
meta/
info.json
tasks.jsonl
episodes.jsonl
episodes_stats.jsonl
data/
chunk-000/
episode_000000.parquet
episode_000001.parquet
videos/
chunk-000/
observation.images.head_rgb/
episode_000000.mp4
observation.images.left_wrist_rgb/
episode_000000.mp4
observation.images.right_wrist_rgb/
episode_000000.mp4
Trong mỗi frame, bạn cần đủ ba nhóm dữ liệu:
| Nhóm | Ví dụ field | Ghi chú |
|---|---|---|
| Observation image | observation.images.head_rgb, left_wrist_rgb, right_wrist_rgb |
Camera phải đồng bộ với action càng tốt càng tốt |
| Observation state | observation.state.left_ee_pose, right_ee_pose, torso, left_gripper |
Proprioception tại thời điểm model quan sát |
| Action | action.left_ee_pose, action.right_ee_pose, action.torso, action.left_gripper |
Target mà policy cần dự đoán |
| Index/language | timestamp, frame_index, episode_index, task_index |
tasks.jsonl map task_index sang instruction |
Nếu robot của bạn chỉ là single-arm tabletop, bạn có hai lựa chọn. Một là map dataset về schema R1 Pro bằng cách để các field không dùng ở trạng thái zero hoặc frozen, nhưng cần kiểm tra kỹ transform có chấp nhận không. Hai là tạo data config riêng trong configs/data/<robot>/<schema>.yaml, khai báo lại shape_meta, camera keys, action keys và processor. Cách thứ hai sạch hơn cho production.
Dataset nhỏ có thể train được, nhưng đừng quá ít. Với task đơn giản như "pick cup and place on tray", hãy bắt đầu 50-100 successful episodes, thêm 10-20 validation episodes, và đảm bảo có variation về vị trí object, ánh sáng, góc mở gripper, trạng thái thất bại nhẹ. Với task dài hơn như fold towel hoặc appliance operation, chia instruction thành subtask ngắn sẽ quan trọng hơn việc quay một video dài không annotation.
Checklist trước khi train:
# Xem thông tin dataset nếu dùng LeRobot CLI
lerobot-dataset-viz \
--repo-id your_user/your_robot_task \
--episode-index 0
# Kiểm tra ffmpeg vì GalaxeaVLA đọc video mp4
ffmpeg -version
# Kiểm tra parquet có field đúng
python - <<'PY'
import pandas as pd
df = pd.read_parquet("data/chunk-000/episode_000000.parquet")
print(df.columns.tolist())
print(df.head(1))
PY
Cài đặt môi trường GalaxeaVLA
Yêu cầu phần cứng phụ thuộc vào cách train. README GalaxeaVLA nêu inference cần GPU trên 8 GB, còn full fine-tuning model lớn có thể cần GPU rất lớn. Với G0Tiny, config nhỏ hơn G0Plus, nhưng bạn vẫn nên chuẩn bị NVIDIA GPU có bf16 tốt, nhiều CPU workers và ổ SSD nhanh vì video decode là bottleneck phổ biến.
# 1. Clone repo
git clone https://github.com/OpenGalaxea/GalaxeaVLA
cd GalaxeaVLA
# 2. Cài uv nếu máy chưa có
curl -LsSf https://astral.sh/uv/install.sh | sh
# 3. Tạo environment theo repo
uv sync --index-strategy unsafe-best-match
source .venv/bin/activate
# 4. Cài package local
uv pip install -e .
uv pip install -e ".[dev]"
# 5. Package hệ thống cho video
sudo apt install ffmpeg
Tải checkpoint từ OpenGalaxea/G0-VLA trên Hugging Face. G0Tiny public path trong README là G0Tiny_260120. Bạn cũng cần đảm bảo model path/tokenizer path cho HuggingFaceTB/SmolVLM2-500M-Video-Instruct đúng với môi trường của bạn, đặc biệt nếu training offline.
Thiết lập biến môi trường:
export HF_DATASETS_CACHE=/data/cache/hf_datasets
export GALAXEA_FM_OUTPUT_DIR=/data/outputs/galaxea_fm
export GALAXEA_FM_DATASET_STATS_CACHE_DIR=/data/cache/galaxea_stats
export SWANLAB_API_KEY=your_swanlab_key
mkdir -p "$HF_DATASETS_CACHE" \
"$GALAXEA_FM_OUTPUT_DIR" \
"$GALAXEA_FM_DATASET_STATS_CACHE_DIR"
Nếu bạn không dùng SwanLab, hãy đổi logger trong configs/train.yaml hoặc override bằng Hydra nếu repo version của bạn hỗ trợ. Với beginner, cách dễ nhất là để logging chạy local/disabled trước, xác nhận training không lỗi, rồi mới bật dashboard.
Tạo task config cho G0Tiny
Đừng sửa trực tiếp config mẫu nếu bạn muốn tái lập thí nghiệm. Hãy copy thành file task mới:
cp configs/task/real/g0tiny_r1pro_finetune.yaml \
configs/task/real/g0tiny_my_pick_place.yaml
Nội dung tối thiểu:
# @package _global_
defaults:
- override /data: r1pro/eef_torso
- override /model: vla/g0tiny
model:
pretrained_ckpt: /data/checkpoints/G0Tiny_260120
data:
dataset:
dataset_dirs:
- /data/lerobot/my_pick_place_001
- /data/lerobot/my_pick_place_002
Với custom robot, phần quan trọng không nằm ở task file mà nằm ở data config. Ví dụ bạn có một arm 7-DoF, một gripper và hai camera:
dataset:
_target_: galaxea_fm.data.galaxea_lerobot_dataset.GalaxeaLerobotDataset
dataset_dirs: null
shape_meta:
action:
- key: arm_joint
raw_shape: 7
shape: 7
- key: gripper
raw_shape: 1
shape: 1
state:
- key: arm_joint
raw_shape: 7
shape: 7
- key: gripper
raw_shape: 1
shape: 1
images:
- key: front_rgb
raw_shape: [3, 480, 640]
shape: [3, ${model.model_meta.input_image_size.0}, ${model.model_meta.input_image_size.1}]
- key: wrist_rgb
raw_shape: [3, 480, 640]
shape: [3, ${model.model_meta.input_image_size.0}, ${model.model_meta.input_image_size.1}]
action_size: 32
obs_size: 1
Đây chỉ là skeleton. Bạn cần processor transforms tương ứng để action/state được concatenate đúng, normalize đúng, và key names khớp parquet. Lỗi phổ biến nhất là dataset có observation.images.front nhưng config lại chờ head_rgb; hoặc action dimension thực tế khác action_output_dim sau transform.
Chạy fine-tuning
Script public của repo gọi torchrun và nhận hai tham số chính: số GPU và task path.
# 1 GPU, task custom
bash scripts/run/finetune.sh 1 real/g0tiny_my_pick_place
# Override nhanh batch size nếu OOM
bash scripts/run/finetune.sh 1 real/g0tiny_my_pick_place \
model.batch_size=4 \
model.grad_accumulation_steps=4
Với G0Tiny, tôi thường bắt đầu bằng cấu hình thận trọng:
| Tham số | Giá trị khởi đầu | Khi nào đổi |
|---|---|---|
model.batch_size |
4-8 | Tăng nếu GPU còn dư VRAM |
grad_accumulation_steps |
2-4 | Giữ effective batch khi batch nhỏ |
learning_rate |
3e-5 đến 6e-5 | Giảm nếu loss dao động mạnh |
max_epochs |
4-10 | Tăng khi dataset nhỏ nhưng validation chưa overfit |
warmup_steps |
200-500 | Tăng nếu training không ổn định đầu run |
Theo dõi ba nhóm tín hiệu. Thứ nhất là training loss và validation loss: loss giảm đều nhưng validation tăng sớm nghĩa là overfit hoặc validation quá khác train. Thứ hai là video/action alignment: nếu model học nhưng robot luôn chậm nửa giây, hãy kiểm tra timestamp và latency giữa camera/action. Thứ ba là normalization stats: nếu gripper bị kẹt ở 0 hoặc 1, có thể gripper range trong dataset quá lệch hoặc transform exception chưa đúng.
Một vòng debug nhanh:
Loss NaN?
-> giảm learning rate, tắt torch compile, kiểm tra bf16/GPU
OOM?
-> giảm batch_size, giảm num_workers, dùng grad accumulation
Robot action sai hướng?
-> kiểm tra frame convention: world/base/eef, relative vs absolute
Policy không hiểu instruction?
-> kiểm tra tasks.jsonl, language trùng với subtask thật, không quá dài
Train loss thấp nhưng robot fail?
-> replay action ground truth trên robot/sim trước khi đổ lỗi cho model
Inference và deploy trên robot thật
Inference có hai chế độ. Chế độ lab là chạy checkpoint PyTorch trên workstation GPU, gửi action tới robot qua ROS/bridge. Chế độ edge là convert hoặc dùng engine được tối ưu, ví dụ docs handover gift của Galaxea mô tả TensorRT/CUDA, FP16 engine và spline post-processing trên JetPack 6.0. Nếu bạn mới bắt đầu, hãy dùng workstation trước để giảm số biến cần debug.
Pipeline triển khai nên có safety layer riêng:
Camera/state sync
|
v
G0Tiny policy inference
|
v
Action denormalize
|
v
Safety filter: joint limit, velocity limit, workspace box
|
v
Smoothing / spline / chunk blending
|
v
Robot low-level controller
Pseudo-code cho vòng inference:
policy.eval()
while robot.is_enabled():
obs = robot.get_observation()
batch = processor.to_batch(
images={
"head_rgb": obs.head_rgb,
"left_wrist_rgb": obs.left_wrist_rgb,
"right_wrist_rgb": obs.right_wrist_rgb,
},
state=obs.proprio,
instruction="pick up the bottle and place it on the tray",
)
with torch.no_grad(), torch.autocast("cuda", dtype=torch.bfloat16):
action_chunk = policy.predict_action(batch)
action_chunk = processor.denormalize_action(action_chunk)
action_chunk = safety_filter(action_chunk)
robot.execute_chunk(action_chunk, replan_after=8)
Đừng bỏ qua emergency stop, workspace limit và dry-run. Với manipulation thật, policy có thể đưa ra action hợp lý trong 95% thời gian nhưng một action outlier vẫn đủ làm robot va chạm. Hãy test theo thứ tự: offline batch inference, replay trong simulator/log viewer, robot bật torque thấp hoặc speed thấp, rồi mới tăng tốc.
Kết quả mong đợi và cách đánh giá
Paper G0 đánh giá trên table bussing, microwave operation, bed making và blocks stacking. Kết quả chính không chỉ là "model nào score cao hơn", mà là Stage-2 single-embodiment pre-training giúp action mượt hơn, instruction following tốt hơn và cải thiện rõ trong few-shot transfer. Với G0-VLM, paper báo cáo accuracy lập kế hoạch cao hơn các VLM general-purpose trong benchmark nội bộ vì model được fine-tune vào action primitives robot có thể thực thi.
Khi bạn fine-tune G0Tiny cho robot riêng, hãy dùng metric đơn giản nhưng nhất quán:
| Metric | Cách đo | Vì sao quan trọng |
|---|---|---|
| Success rate | 20-50 rollout thật, cùng protocol | Dễ so giữa checkpoint |
| Progress score | Chấm từng subtask hoàn thành | Hữu ích cho long-horizon task |
| Intervention rate | Số lần human phải takeover | Đo độ ổn định deployment |
| Cycle time | Thời gian hoàn thành task | Policy quá chậm cũng không dùng được |
| Safety violation | Va chạm, joint limit, workspace breach | Không đánh đổi success lấy rủi ro |
Baseline nên gồm behavioral cloning nhỏ như ACT/Diffusion Policy trên cùng dataset, G0Tiny fine-tune từ base, và nếu có compute thì G0Plus hoặc Pi0/SmolVLA. Nếu G0Tiny không thắng baseline nhỏ, thường nguyên nhân là schema/normalization/action delay hơn là "VLA không hiệu quả".
Lộ trình thực tế cho beginner
- Chọn một task có horizon ngắn: pick object, place into tray, open/close drawer đơn giản.
- Thu 50 episode tốt, xóa episode lỗi, giữ camera luôn thấy object và gripper.
- Convert sang LeRobot format, visualize ít nhất 10 episode ngẫu nhiên.
- Fine-tune G0Tiny với batch nhỏ, log train/val loss và lưu checkpoint định kỳ.
- Chạy offline inference trên validation episodes, so action predicted với action thật.
- Deploy ở tốc độ thấp, action clamp chặt, replan sau một phần chunk.
- Ghi lại failure, thêm demonstration đúng vào các case fail, fine-tune tiếp.
G0Tiny không phải nút bấm "robot làm được mọi thứ". Nó là một base policy nhỏ, có kiến trúc hợp lý cho VLA manipulation và tương thích LeRobot. Lợi thế thật sự xuất hiện khi bạn kết hợp nó với dataset đồng bộ, annotation ngắn gọn, action space nhất quán và evaluation nghiêm túc.
Nguồn tham khảo
- Paper: Galaxea Open-World Dataset and G0 Dual-System VLA Model
- Code: OpenGalaxea/GalaxeaVLA
- Model weights: OpenGalaxea/G0-VLA
- Dataset: OpenGalaxea/Galaxea-Open-World-Dataset
- LeRobot docs: Using Dataset Tools