Introduction: When VLA Models "Memorize the Textbook" but Can't "Pass the Exam"
Imagine you're teaching a child to play basketball. You show them hundreds of videos of perfect shots — hand angles, force, body positioning. After watching, the child can describe exactly how to shoot, but their actual shooting percentage remains low. Why? Because watching someone else do it is fundamentally different from doing it yourself.
This is precisely the problem that Vision-Language-Action (VLA) models face today. After Supervised Fine-Tuning (SFT) — learning from expert demonstrations — they hit a performance ceiling that more data alone cannot break. SimpleVLA-RL, published at ICLR 2026, proposes a surprisingly simple solution: let robots practice on their own with binary feedback (success/failure), achieving improvements of up to 430%.
This is Part 1 of a 2-part series on SimpleVLA-RL, where we'll explore the core ideas and the remarkable results behind this method.

The Problem: Why VLA Models Plateau After SFT
The Data Ceiling
Current VLA models like OpenVLA, RT-2, and Octo all follow a similar pipeline: collect demonstration data from teleoperation (human operators controlling the robot), then train the model with supervised learning. This approach has three fundamental limitations:
-
Extremely high data collection costs: Each demonstration requires an experienced operator, a physical robot, and setup time. Collecting 500 demonstrations for a single task can take weeks.
-
Data only contains what operators think of: If operators always grasp objects from above, the model will never learn to approach from the side — even though that might be more effective in many situations.
-
Diminishing returns: After a certain amount of data, additional demonstrations barely improve performance. The model has "saturated" on the knowledge available in the dataset.
SFT = Memorizing, RL = Learning by Doing
To understand the difference more clearly, consider this analogy:
-
SFT is like reading a textbook: You learn the steps, memorize the procedures, and can reproduce what the book teaches. But when you encounter a new situation — object in an unusual position, different lighting, slippery surface — you struggle because the textbook didn't cover that case.
-
RL is like practicing on the court: You try, fail, adjust, try again. Each failure teaches you something the textbook never mentioned. You discover "tricks" that nobody taught you — like pushing an object into a corner before grasping, or tilting your hand at 45 degrees instead of 90.
SimpleVLA-RL takes VLA models from the "reading textbook" phase to the "practicing on the court" phase — and the result is a quantum leap in performance.
The Core Insight: Binary Reward Is Enough
The Simplest Possible Reward
One of the biggest barriers to applying Reinforcement Learning for robot manipulation has been reward engineering — designing appropriate reward functions. Traditionally, researchers had to craft complex rewards: distance from hand to object, grasp angle, contact force, etc. Each task needed its own reward function, and a bad reward function could lead to reward hacking — the robot finding ways to "cheat" to maximize reward without actually completing the task.
SimpleVLA-RL takes the opposite approach — as simple as possible:
R = 1 if the robot successfully completes the task
R = 0 if the robot fails
That's it. No intermediate rewards, no shaping, no heuristics. Just success or failure.
Why does this work? Because the VLA model already has a solid foundation from SFT. It already knows how to approach objects, how to move the gripper. What it needs isn't detailed step-by-step guidance (dense reward), but holistic feedback: "this way works" or "this way doesn't." From that feedback, it figures out how to improve on its own.
Think back to the basketball analogy: you don't need someone analyzing every joint angle after each shot. You just need to know whether the ball went in or not — and over hundreds of attempts, your body self-corrects.
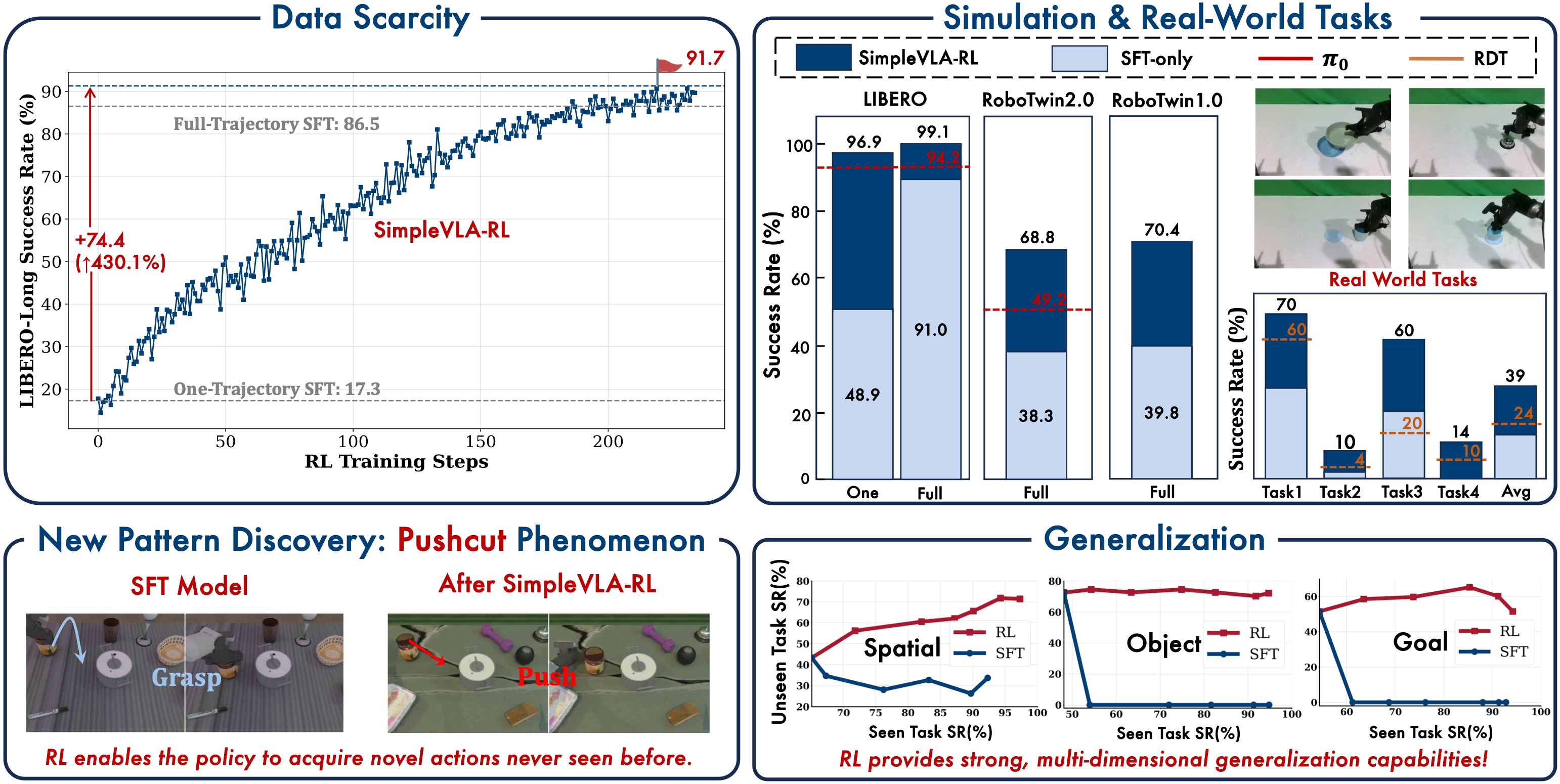
The "Pushcut" Phenomenon: When RL Invents New Strategies
This is the most fascinating part of the paper — and the strongest evidence for RL's power over SFT.
To Grasp or to Push?
In the LIBERO benchmark, one task requires the robot to retrieve a piece of meat from a frying pan. The demonstration data from human operators always shows the same strategy: use the gripper to directly grasp the meat.
But after training with RL, the robot discovered an entirely new strategy: instead of grasping, it pushes the meat out of the pan first, then grasps it on the flat surface — where grasping is much easier. The authors call this the "pushcut" phenomenon.
Why Can't SFT Discover This?
SFT can only learn from existing data. If nobody in the data collection team thought of pushing instead of grasping, the model will never discover this strategy. RL, on the other hand, is encouraged to explore — and through trying many different approaches, it stumbles upon the fact that pushing before grasping has a higher success rate.
This is the fundamental difference between imitation learning and reinforcement learning: imitation learning is limited by the imagination of the teacher, while RL is limited only by the action space of the robot.

Results: The Numbers Speak for Themselves
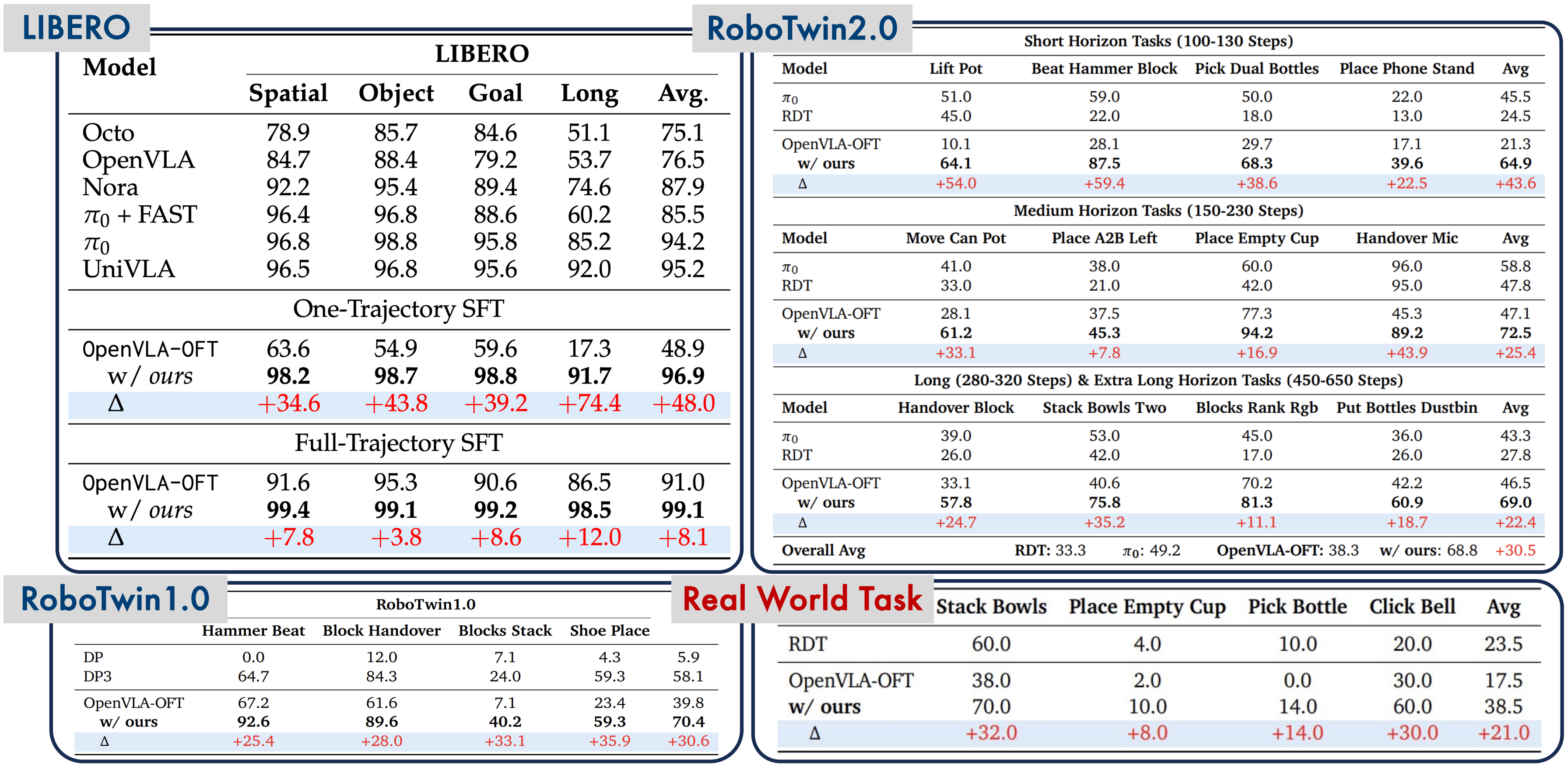
LIBERO-Long: From 97.6% to 99.1%
On the LIBERO-Long benchmark (10 long-horizon, multi-step tasks), SimpleVLA-RL achieves 99.1% success rate, up from 97.6% with the SFT baseline. The absolute improvement of 1.5 percentage points might seem small, but at near-100% accuracy, every additional percent is extremely hard to achieve.
Cold-start: From 17.3% to 91.7% (430% Improvement)
This is the most impressive result. With only 1 demonstration per task (instead of 500), SFT achieves just 17.3%. But combined with online RL, performance jumps to 91.7% — nearly matching the 91.0% that SFT needs 500 demonstrations to achieve!
In other words: 1 demo + RL is roughly equal to 500 demos with SFT alone. The practical implications are enormous — instead of spending weeks collecting data, you need just one demonstration and then let the robot improve itself in simulation.
RoboTwin: From 38.3% to 68.8%
On the RoboTwin benchmark (more complex dual-arm tasks), SimpleVLA-RL improves from 38.3% to 68.8% — a 79.6% relative improvement. This benchmark is significantly harder as it requires coordinating two arms simultaneously.
Real World: From 17.5% to 38.5%
On a real Piper dual-arm robot (not simulation), SimpleVLA-RL improves from 17.5% to 38.5% — a 120% improvement. While 38.5% might sound low, this is real-world manipulation with sim-to-real transfer, and a 120% improvement demonstrates that RL genuinely helps the model generalize beyond simulation.
High-Level Pipeline: From SFT to RL
SimpleVLA-RL operates as a 2-stage pipeline:
Stage 1: SFT Cold-start
- Collect demonstration data (500 demos/task for LIBERO, or just 1 demo for cold-start experiments)
- Fine-tune OpenVLA-OFT on this data with supervised learning
- Result: model can perform the task at a basic level
Stage 2: RL Online Training
- Deploy the model in a simulation environment (LIBERO or RoboTwin)
- Model performs the task, receives binary reward (1 or 0)
- Use the GRPO (Group Relative Policy Optimization) algorithm to update the policy
- Repeat until convergence
The key point: this is online RL — the model interacts directly with the environment, not offline RL (learning from a fixed dataset). This allows the model to discover new strategies not present in the demonstration data.

Why SimpleVLA-RL Matters
1. Breaking the Data Ceiling
Before SimpleVLA-RL, the only way to improve VLA models was to collect more data. Now, there's another path: let the model improve itself through trial-and-error. This is a paradigm shift in robot learning.
2. Reducing Data Collection Cost by 500x
The cold-start experiment shows that 1 demo + RL nearly matches 500 demos with SFT. In practice, this means that when deploying a robot for a new task, you only need to demonstrate once and then let the robot practice overnight in simulation.
3. Emergence of Novel Behaviors
The "pushcut" phenomenon shows that RL can invent strategies that humans didn't think of. As robots operate in diverse environments (factories, hospitals, homes), the ability to autonomously discover new solutions is extremely valuable.
4. Surprisingly Simple
No complex reward engineering, no critic network, no KL regularization. Just binary reward + GRPO + a few tricks (dynamic sampling, asymmetric clipping). This simplicity makes the method easy to reproduce and broadly applicable.
Series Roadmap
The SimpleVLA-RL series consists of 2 parts:
| Part | Content | Level |
|---|---|---|
| Part 1 (this post) | Overview, ideas, results | Beginner |
| Part 2 | Detailed architecture, GRPO, dynamic sampling | Intermediate |
Prerequisites
To follow this series effectively, you should have:
- Basic Python: Ability to read PyTorch code
- RL fundamentals: Policy, reward, episode. If not, read RL Basics for Robotics
- VLA understanding: What Vision-Language-Action models are. See VLA Models: From Language to Action
References
- SimpleVLA-RL: Reinforcing Vision-Language-Action Models with Simple Binary Rewards — Huaide Ren et al., ICLR 2026
- GitHub: PRIME-RL/SimpleVLA-RL
- OpenVLA-OFT — Backbone model
- veRL Framework — RL training framework
Conclusion
SimpleVLA-RL is not a complex method with dozens of hyperparameters to tune. It's a simple idea — let robots practice with pass/fail feedback — executed carefully. And that's what makes it powerful: when a simple method produces good results, it's usually more robust and generalizable than complex alternatives.
In Part 2, we'll dive into the OpenVLA-OFT architecture, the GRPO algorithm, and the engineering techniques that make SimpleVLA-RL work. If you're interested in how Embodied AI is evolving in 2026, this is one of the most exciting research directions to follow.