
ASAP giải quyết bài toán gì?
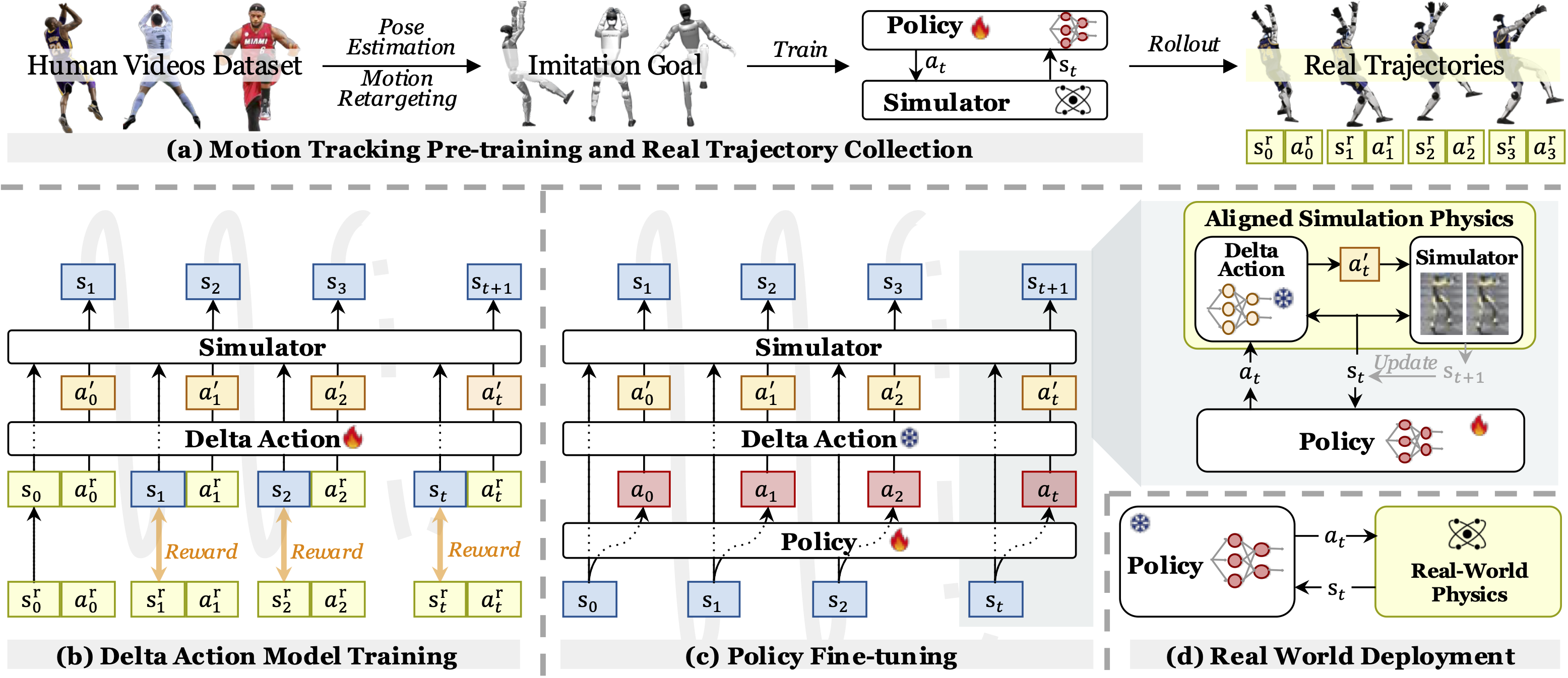
ASAP, viết tắt của Aligning Simulation and Real Physics, là paper RSS 2025 của LeCAR-Lab/CMU, NVIDIA và các cộng tác viên về học kỹ năng whole-body agile cho humanoid. Project page chính thức nằm tại agile.human2humanoid.com và code public ở LeCAR-Lab/ASAP. Nếu bạn đang theo dõi các bài về sim-to-real cho humanoid, whole-body data pipeline, hoặc deploy G1 WBC, ASAP là một mảnh rất đáng học vì nó không chỉ randomize simulation rồi hy vọng policy sống sót trên robot thật. Nó học một delta action model từ dữ liệu thật, sau đó dùng model này để chỉnh lại môi trường training trong simulator.
Vấn đề cốt lõi như sau: một policy motion tracking có thể chạy rất đẹp trong IsaacGym, nhưng khi chuyển sang IsaacSim, Genesis hoặc Unitree G1 thật, cùng một action không tạo ra cùng một trajectory. Khác biệt đến từ actuator, delay, joint friction, contact, ankle linkage, độ cứng của cơ cấu, model mass/inertia chưa đúng và cả low-level controller của robot. Domain randomization có thể giúp policy bớt nhạy, nhưng thường làm policy bảo thủ hơn. System identification có thể tìm một vài tham số vật lý tốt hơn, nhưng rất khó bao hết mismatch của một humanoid 23-29 DoF trong chuyển động mạnh như kick, jump hoặc side jump.
ASAP chọn một hướng thực dụng hơn: thay vì cố tìm đúng toàn bộ physics parameter, nó học một residual correction ở action space. Base policy vẫn xuất action như bình thường. Delta action model học phần bù cần thêm vào action để simulation đi giống real-world trajectory hơn. Sau đó, base policy được fine-tune trong simulator đã gắn delta action model. Khi deploy thật, ASAP không cần chạy delta model online; policy đã fine-tune được deploy trực tiếp lên robot.
Ý tưởng paper ở mức beginner
Hãy tưởng tượng bạn có ba thế giới. Thế giới thứ nhất là IsaacGym, nơi bạn train policy rất nhanh với hàng nghìn environment song song. Thế giới thứ hai là một simulator khác như IsaacSim hoặc Genesis. Thế giới thứ ba là Unitree G1 thật. Cùng một state và cùng một action, robot trong ba thế giới này không rơi vào cùng state kế tiếp. Với locomotion bình thường, lỗi này đã khó chịu. Với whole-body agile skills, lỗi đó trở thành vấn đề lớn: đá chân bị hụt, nhảy thấp hơn, chân tiếp đất lệch, thân dưới giật, hoặc robot mất thăng bằng.
ASAP chia bài toán thành bốn bước:
- Motion tracking pre-training: retarget human motion sang robot, rồi train policy trong IsaacGym để bắt chước motion đó.
- Real trajectory collection: deploy policy pre-trained lên robot thật hoặc simulator target, ghi lại state-action trajectory.
- Delta action model training: train một model residual để action trong simulator tạo ra state gần với trajectory thật hơn.
- Policy fine-tuning: freeze delta action model, đưa nó vào simulator, fine-tune policy tracking, rồi deploy policy mới ra robot thật.
Điểm quan trọng là delta model không phải là dynamics model dự đoán state kế tiếp. Nó là một policy nhỏ học action correction. Cách này phù hợp với robot vì low-level actuator thường nhận command dạng position/PD target, và nhiều mismatch thể hiện trực tiếp ở việc "command này trên sim tạo lực khác command này trên real". Trong paper, tác giả so sánh với SysID và DeltaDynamics. Kết quả cho thấy residual action thường ổn định hơn residual dynamics khi horizon dài, vì dynamics error dễ cascade qua nhiều bước.
Một cách đọc công thức đơn giản:
base_policy(state, motion_phase) -> action
delta_action_model(state, action, history) -> delta_action
sim_action = action + delta_action
Khi train delta action, mục tiêu là làm trajectory trong simulator bám state thật đã ghi lại. Khi fine-tune policy, simulator đã "cư xử giống thật hơn" vì action bị delta model chỉnh lại trước khi áp dụng vào robot sim. Khi deploy real, policy đã học cách chọn action phù hợp với physics thật, nên không cần mang delta model lên robot.
Kiến trúc code: HumanoidVerse, Human2Humanoid và ASAP
Repo ASAP được xây trên hai nền tảng: HumanoidVerse và Human2Humanoid. HumanoidVerse tách simulator, task và algorithm thành các module để cùng một task có thể chạy trên IsaacGym, IsaacSim hoặc Genesis với thay đổi cấu hình nhỏ. Human2Humanoid là nền tảng trước đó cho motion tracking từ human motion sang humanoid. ASAP thêm pipeline delta action, motion datasets, retargeting và sim2real deployment cho Unitree G1.
Ở mức thư mục, bạn sẽ gặp các phần chính:
ASAP/
humanoidverse/ # training, task, robot config, motion data
isaac_utils/ # tiện ích IsaacGym/IsaacSim
sim2real/ # deploy MuJoCo, Unitree SDK, policy ONNX
scripts/ # helper scripts
imgs/ # GIF demo và hình trong README
Robot được dùng trong paper là Unitree G1. README nhấn mạnh cấu hình G1 29 DoF, với quá trình anneal về 23 DoF trong một số policy. Đây là chi tiết thực tế quan trọng: nếu bạn có G1 bản wrist/waist khác, số DoF và mapping joint có thể không khớp với checkpoint public. Một số issue trong repo cũng xoay quanh câu hỏi 23 DoF vs 29 DoF. Vì vậy, trước khi chạy checkpoint lên phần cứng thật, bạn phải đối chiếu URDF/XML, joint order, action scale, PD gain, network interface và low-level mode.
![]()
Chuẩn bị máy và cài đặt
Bạn nên bắt đầu bằng simulation, không bắt đầu bằng robot thật. Cấu hình thực tế nên có Linux, NVIDIA GPU, CUDA/PyTorch tương thích, conda hoặc mamba, IsaacGym Preview 4 và đủ disk cho motion datasets. IsaacGym vẫn là môi trường training chính trong README vì nó chạy hàng nghìn environment song song. IsaacSim/IsaacLab và Genesis dùng nhiều cho sim-to-sim evaluation hoặc transfer.
Các bước cài đặt cơ bản theo README:
conda create -n hvgym python=3.8
conda activate hvgym
# Tải IsaacGym Preview 4 từ NVIDIA rồi giải nén
tar -xvzf isaac-gym-preview-4
pip install -e isaacgym/python
# Trong thư mục ASAP
pip install -e .
pip install -e isaac_utils
pip install -r requirements.txt
Sau khi cài IsaacGym, nên chạy test nhỏ trước:
python 1080_balls_of_solitude.py
python joint_monkey.py
Nếu gặp lỗi libpython, README gợi ý kiểm tra đường dẫn conda và export LD_LIBRARY_PATH:
conda info -e
export LD_LIBRARY_PATH=/path/to/conda/envs/hvgym/lib:$LD_LIBRARY_PATH
Để test HumanoidVerse với G1 locomotion, README đưa lệnh mẫu:
HYDRA_FULL_ERROR=1 python humanoidverse/train_agent.py \
+simulator=isaacgym \
+exp=locomotion \
+domain_rand=NO_domain_rand \
+rewards=loco/reward_g1_locomotion \
+robot=g1/g1_29dof_anneal_23dof \
+terrain=terrain_locomotion_plane \
+obs=loco/leggedloco_obs_singlestep_withlinvel \
num_envs=1 \
project_name=TestIsaacGymInstallation \
experiment_name=G123dof_loco \
headless=False
Lệnh này không phải setup training trong paper, nhưng rất hữu ích để kiểm tra asset, simulator, GPU, config Hydra và viewer. Khi mọi thứ ổn, bạn mới tăng num_envs lên 4096 hoặc 5000 cho training thật.
Motion data và retargeting
ASAP dùng human motion làm nguồn kỹ năng. Paper mô tả pipeline từ video người sang SMPL, rồi retarget sang Unitree G1. Project page ghi rõ: human motion được capture từ video, TRAM tái dựng 3D human motion ở dạng SMPL, sau đó policy RL học tracking motion trong simulation, motion được retarget sang G1, cuối cùng policy được deploy lên robot.
Nếu bạn chỉ muốn reproduce các motion trong paper, repo đã cung cấp SMPL motions và G1 retargeted motions dùng trong ASAP. README ghi đường dẫn như:
humanoidverse/data/motions/raw_tairantestbed_smpl
humanoidverse/data/motions/g1_29dof_anneal_23dof/TairanTestbed/singles
Nếu muốn retarget motion khác hoặc robot khác, pipeline dài hơn:
- Tải SMPL v1.1.0
.pklvà đặt vàohumanoidverse/data/smpl/. - Tải AMASS dataset ở định dạng
SMPL + H G. - Chuẩn bị robot XML và motion config.
- Fit shape giữa humanoid và SMPL body.
- Retarget motion từ SMPL sang robot.
Beginner nên đi theo hướng an toàn: dùng motion đã có trước, train một motion tracking policy đơn lẻ, hiểu observation/action/reward, rồi mới retarget motion mới. Retargeting sai thường làm policy train rất chậm hoặc học tư thế kỳ lạ vì reference joint pose không khả thi với robot.
Training motion tracking policy
Phase-based motion tracking là stage đầu tiên. Policy nhận observation của robot, lịch sử state, phase của motion và reference motion, rồi học action để robot bắt chước clip. README có ví dụ train motion Cristiano Ronaldo "Siuuu":
python humanoidverse/train_agent.py \
+simulator=isaacgym \
+exp=motion_tracking \
+domain_rand=NO_domain_rand \
+rewards=motion_tracking/reward_motion_tracking_dm_2real \
+robot=g1/g1_29dof_anneal_23dof \
+terrain=terrain_locomotion_plane \
+obs=motion_tracking/deepmimic_a2c_nolinvel_LARGEnoise_history \
num_envs=4096 \
project_name=MotionTracking \
experiment_name=MotionTracking_CR7 \
robot.motion.motion_file="humanoidverse/data/motions/g1_29dof_anneal_23dof/TairanTestbed/singles/0-TairanTestbed_TairanTestbed_CR7_video_CR7_level1_filter_amass.pkl" \
rewards.reward_penalty_curriculum=True \
rewards.reward_penalty_degree=0.00001 \
env.config.resample_motion_when_training=False \
env.config.termination.terminate_when_motion_far=True \
env.config.termination_curriculum.terminate_when_motion_far_curriculum=True \
env.config.termination_curriculum.terminate_when_motion_far_threshold_min=0.3 \
env.config.termination_curriculum.terminate_when_motion_far_curriculum_degree=0.000025 \
robot.asset.self_collisions=0
Một vài tham số cần hiểu:
| Tham số | Ý nghĩa |
|---|---|
+exp=motion_tracking |
chọn task imitation/motion tracking |
+robot=g1/g1_29dof_anneal_23dof |
chọn cấu hình G1 |
robot.motion.motion_file |
file reference motion đã retarget |
terminate_when_motion_far |
dừng episode nếu robot lệch quá xa reference |
reward_penalty_curriculum |
tăng penalty dần để policy học từ dễ đến khó |
num_envs=4096 |
số environment song song trong IsaacGym |
Sau training, xem policy bằng:
python humanoidverse/eval_agent.py \
+checkpoint=logs/MotionTracking/.../model_5800.pt
Ở bước này, bạn chỉ nên kỳ vọng policy chạy tốt trong IsaacGym. Nếu policy đã rung, mất phase hoặc chân xuyên đất trong sim, đừng nghĩ delta action sẽ cứu được. Delta model là bước alignment sim-to-real, không phải công cụ sửa một motion tracking policy chưa học xong.
Train delta action model
Delta action model cần motion file có thêm key "action". Lý do là nó học từ state-action trajectory đã roll out trong target environment hoặc real-world. Với sim-to-sim, bạn có thể collect trajectory từ IsaacSim hoặc Genesis. Với sim-to-real, paper deploy policy lên G1 thật và ghi dữ liệu thật. Mục tiêu training là tìm delta action để simulator replay gần trajectory target hơn.
Lệnh training open-loop trong README:
python humanoidverse/train_agent.py \
+simulator=isaacgym \
+exp=train_delta_a_open_loop \
+domain_rand=NO_domain_rand \
+rewards=motion_tracking/delta_a/reward_delta_a_openloop \
+robot=g1/g1_29dof_anneal_23dof \
+terrain=terrain_locomotion_plane \
+obs=delta_a/open_loop \
num_envs=5000 \
project_name=DeltaA_Training \
experiment_name=openloopDeltaA_training \
robot.motion.motion_file="<PATH_TO_YOUR_MOTION_FILE_WITH_ACTION_KEYNAME>" \
env.config.max_episode_length_s=1.0 \
rewards.reward_scales.penalty_minimal_action_norm=-0.1 \
+device=cuda:0 \
env.config.resample_motion_when_training=True \
env.config.resample_time_interval_s=10000
Bạn nên hiểu max_episode_length_s=1.0 là một lựa chọn thực dụng: delta model học alignment ngắn hạn để tránh lỗi cascade quá dài trong open-loop. Trong paper, đánh giá open-loop cho thấy horizon dài làm các baseline như OpenLoop, SysID và DeltaDynamics tích lũy lỗi nhanh, trong khi ASAP giữ tracking tốt hơn.
Với robot thật, paper không train full 23 DoF delta action model vì cần quá nhiều clip và gây stress phần cứng. Tác giả tập trung vào 4 DoF ankle delta action model. Lý do là Unitree G1 có cơ cấu ankle linkage tạo sim-to-real gap lớn, trong khi dữ liệu thật bị giới hạn. Paper nói họ thu 100 motion clips cho real-world setting, chạy mỗi task 30 lần, thêm 10 phút locomotion data để bridge giữa các tracking policy. Đây là thông tin rất quan trọng cho lab nhỏ: ASAP mạnh nhưng không miễn phí dữ liệu, và agile whole-body data collection có rủi ro hỏng robot.

Fine-tune policy với delta action model
Sau khi có delta action model, bước tiếp theo là freeze model này và gắn nó vào simulator. Policy tracking ban đầu được fine-tune trong môi trường đã có add_extra_action=True. README dùng lệnh:
HYDRA_FULL_ERROR=1 python humanoidverse/train_agent.py \
+simulator=isaacgym \
+exp=train_delta_a_closed_loop \
algo.config.policy_checkpoint="<PATH_TO_YOUR_DELTA_A_MODEL>" \
+domain_rand=NO_domain_rand_finetune_with_deltaA \
+rewards=motion_tracking/reward_motion_tracking_dm_simfinetuning \
+robot=g1/g1_29dof_anneal_23dof \
+terrain=terrain_locomotion_plane \
+obs=delta_a/train_policy_with_delta_a \
num_envs=4096 \
project_name=DeltaA_Finetune \
experiment_name=finetune_with_deltaA \
robot.motion.motion_file="<PATH_TO_YOUR_MOTION_FILE>" \
+opt=wandb \
env.config.add_extra_action=True \
+checkpoint="<PATH_TO_YOUR_POLICY_TO_BE_FINETUNED>" \
domain_rand.push_robots=False \
env.config.noise_to_initial_level=1 \
rewards.reward_penalty_curriculum=True \
+device=cuda:0 \
algo.config.save_interval=5 \
algo.config.num_learning_iterations=1000
Hãy để ý hai checkpoint khác nhau. algo.config.policy_checkpoint là delta action model. +checkpoint là motion tracking policy cần fine-tune. Nếu nhầm hai thứ này, training có thể chạy nhưng kết quả vô nghĩa. Với beginner, nên đặt tên thư mục rõ ràng:
logs/
MotionTracking/CR7_base_policy/
DeltaA_Training/g1_ankle_delta_a/
DeltaA_Finetune/CR7_with_delta_a/
Trong quá trình fine-tuning, monitor các metric như tracking error, episode termination, action norm, joint velocity, body height và contact. Nếu reward tăng nhưng motion bắt đầu giật mạnh, bạn cần xem lại penalty action, termination threshold hoặc chất lượng trajectory dùng train delta model.
Inference, sim2sim và sim2real
ASAP repo có phần sim2real/ để chạy MuJoCo sim2sim và Unitree SDK sim2real. Đây không phải bước dành cho người mới hoàn toàn, vì bạn đang chạy low-level policy trên humanoid thật. README có cảnh báo rõ: deploy model lên hardware vật lý có thể nguy hiểm, cần expertise sim-to-real và safety protocol; tác giả disclaim trách nhiệm nếu robot hỏng.
Với G1 thật, README nhắc phải unlock waist để robot ở 29 DoF theo tài liệu Unitree, restart robot, vào Low-Level mode, kết nối PC với G1 qua Ethernet, cấu hình network interface, rồi chỉnh config/g1_29dof_hist.yaml để INTERFACE trỏ đúng interface có IP 192.168.123.xxx, ví dụ eth0.
Lệnh start policy mẫu:
python rl_policy/deepmimic_dec_loco_height.py \
--config=config/g1_29dof_hist.yaml \
--loco_model_path=./models/dec_loco/20250109_231507-noDR_rand_history_loco_stand_height_noise-decoupled_locomotion-g1_29dof/model_6600.onnx \
--mimic_model_paths=./models/mimic
Các phím điều khiển trong README gồm:
| Phím | Chức năng |
|---|---|
] |
activate locomotion policy |
[ |
activate ASAP phase-based motion tracking policy |
; |
switch sang ASAP policy |
i |
đưa robot về initial position |
o |
emergency stop |
9 |
release robot stack trong MuJoCo viewer |
= |
chuyển tapping/walking cho locomotion |
w/a/s/d |
điều khiển linear velocity |
q/e |
điều khiển angular velocity |
z |
set command về zero |
Một best practice là chạy theo thứ tự: IsaacGym eval, MuJoCo sim2sim, robot treo hoặc có safety rig nếu có, motion biên độ nhỏ, rồi mới tăng lên kick/jump. Với agile motion, chỉ một contact bất thường cũng có thể làm ankle hoặc knee motor quá nhiệt.
Kết quả trong paper
ASAP được đánh giá trên ba hướng transfer: IsaacGym sang IsaacSim, IsaacGym sang Genesis, và IsaacGym sang Unitree G1 thật. Trong sim-to-sim, paper báo cáo ASAP giảm tracking error tốt hơn OpenLoop, SysID và DeltaDynamics, đặc biệt ở horizon dài 1.0 giây. Ở closed-loop motion imitation, ASAP giữ success rate 100% trong nhiều mức Easy/Medium/Hard, trong khi DeltaDynamics có thể tụt success rate ở task khó do overfitting và cascading error.
Trong real-world evaluation, tác giả chọn năm task: kick, jump forward, step forward/back, single foot balance và single foot jump. Đây là những motion có sim-to-real gap rõ. Thay vì full 23 DoF delta model, paper train 4 DoF ankle delta model vì dữ liệu thật ít và ankle linkage của G1 là nguồn mismatch lớn. Kết luận của paper nói ASAP đạt giảm tracking error tới 52.7% trong sim-to-real tasks và deploy được agile jumps/kicks trên G1.
Quan trọng hơn con số là bài học kỹ thuật: real-world data không cần cực lớn nếu bạn chọn đúng residual subspace. Với G1, ankle là bottleneck; học residual ở ankle có thể tạo cải thiện lớn hơn việc cố học toàn bộ cơ thể khi dữ liệu ít. Đây là pattern đáng áp dụng cho lab khác: tìm nơi mismatch lớn nhất, học residual correction có kiểm soát, rồi fine-tune policy trong simulator đã được alignment.
Những lỗi beginner hay gặp
Lỗi đầu tiên là coi ASAP như một "script train G1 biết nhảy". Thực tế, ASAP là pipeline nghiên cứu gồm motion data, simulator, policy training, trajectory collection, residual model, fine-tuning và deploy. Nếu bỏ qua một bước, kết quả sẽ không giống paper.
Lỗi thứ hai là dùng sai motion file. Delta action training cần file có key "action", còn motion tracking pre-training dùng reference motion thông thường. Nếu bạn lấy file reference đưa vào delta training, model không có action trajectory để học residual.
Lỗi thứ ba là deploy checkpoint không khớp robot. G1 có biến thể DoF, wrist, waist và firmware. Joint order sai nguy hiểm hơn reward thấp, vì action có thể đi vào joint khác. Trước khi bật motor, hãy verify mapping bằng motion nhỏ, log joint command, so sánh sign convention, action range và PD gain.
Lỗi thứ tư là đánh giá bằng mắt quá sớm. Một GIF đẹp không đủ. Bạn cần tracking metric: root position error, MPJPE, acceleration error, root velocity error, success rate, termination rate và motor temperature. Agile humanoid không chỉ cần "đẹp", mà cần repeatable và không phá hardware.
Checklist reproduce tối thiểu
Nếu muốn follow ASAP một cách có trật tự, hãy làm theo checklist sau:
- Cài IsaacGym và chạy test viewer.
- Cài HumanoidVerse trong repo ASAP.
- Chạy locomotion smoke test với
num_envs=1. - Train một motion tracking policy với motion có sẵn.
- Eval checkpoint trong IsaacGym, xem phase tracking và termination.
- Collect trajectory từ target environment hoặc robot thật nếu có setup an toàn.
- Tạo motion file có key
"action". - Train delta action model open-loop.
- Freeze delta model và fine-tune policy closed-loop.
- Eval sim2sim trước khi nghĩ đến robot thật.
- Với G1 thật, kiểm tra DoF, network, Low-Level mode, emergency stop và thermal limit.
ASAP đáng học vì nó làm rõ một hướng sim-to-real rất thực dụng: align behavior bằng residual action, không chỉ tune physics parameter. Với humanoid, đặc biệt là Unitree G1, cách này mở đường cho whole-body skills giàu biểu cảm hơn như jump, kick, dance và sports motion. Nhưng đây vẫn là pipeline advanced; beginner nên bắt đầu bằng simulation và coi robot thật là bước cuối, không phải nơi debug đầu tiên.


