For the past several years, PPO (Proximal Policy Optimization) has been the undisputed king of reinforcement learning for robotics. It is stable, well-understood, and works reliably with GPU-accelerated simulators. Nearly every major robotics RL result — from OpenAI's dexterous hand to humanoid locomotion policies — has used PPO or a close variant.
But PPO has a fundamental limitation: it is on-policy. Every batch of collected experience is used for a single gradient update, then discarded. This is enormously wasteful in terms of sample efficiency.
FlashSAC challenges PPO's dominance head-on. Developed by the Holiday-Robot research group, FlashSAC is an off-policy RL algorithm that is both faster and more performant than PPO across over 100 tasks spanning 10 different simulators — while maintaining rock-solid training stability.
This article analyzes the paper FlashSAC: Fast and Stable Off-Policy RL for High-Dimensional Robot Control — Kim, Donghu et al., 2026.

Why Off-Policy RL Matters
To understand why FlashSAC is significant, you need to grasp the core difference between on-policy and off-policy RL.
On-Policy Methods (PPO, TRPO)
- Collect data using the current policy
- Use that data for one round of gradient updates
- Discard all data, collect a new batch
- Requires enormous amounts of experience — low sample efficiency
Off-Policy Methods (SAC, TD3, DDPG)
- Store all experience in a replay buffer
- Reuse old data multiple times for gradient updates
- Much higher sample efficiency
- But historically unstable when scaling to high-dimensional tasks
In theory, off-policy methods should dominate. In practice, when you scale to thousands of parallel GPU environments, classic off-policy algorithms like SAC and TD3 tend to diverge or underperform PPO. This is why PPO has remained the default choice in robotics RL.
FlashSAC solves this instability problem.
FlashSAC: The Three Key Ideas
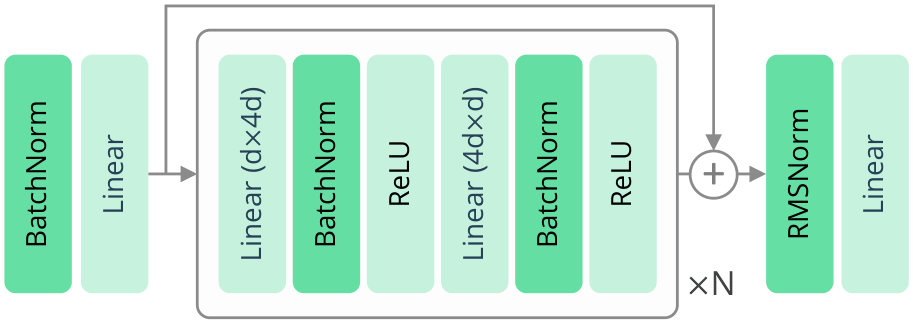
FlashSAC builds on SAC (Soft Actor-Critic) but introduces three critical modifications that enable stable training at scale.
1. Fewer Gradient Updates, Compensated by Larger Models
This is the most counterintuitive insight. Traditional off-policy methods perform many gradient updates per batch of data (a high update-to-data ratio, or UTD ratio). This sounds beneficial — maximize data usage — but in practice causes overfitting and training instability.
FlashSAC takes the opposite approach: minimize gradient updates, but compensate by:
- Using larger networks (more parameters) so each update learns more
- Increasing data throughput — collecting more data per iteration
Think of it like studying for an exam: instead of re-reading the same page 10 times (high UTD), you read each page once but with deeper focus (larger model) and cover more pages per session (higher throughput). The result is better learning with less wasted effort.
2. Norm Bounding for Weights, Features, and Gradients
When you scale neural networks to larger sizes, internal values tend to either explode or vanish. FlashSAC addresses this with norm constraints at three levels:
- Weight norms: Bound the magnitude of network weights
- Feature norms: Normalize intermediate representations
- Gradient norms: Clip gradients when they exceed a threshold
These three layers of protection ensure that training never goes off the rails, even with million-parameter models operating on high-dimensional state spaces. This is fundamentally different from standard weight decay — it imposes hard constraints rather than soft penalties.
3. Designed for GPU-Accelerated Simulators
FlashSAC is optimized from the ground up for modern robotics workflows:
- GPU simulators (IsaacLab, Genesis, ManiSkill): 1024 parallel environments, AMP (Automatic Mixed Precision), CUDA buffer for zero-copy data transfer
- CPU simulators (MuJoCo, DMC): 1 environment, 512 batch size
- Maximum utilization of bandwidth between simulator and learner

Results: 100+ Tasks Across 10 Simulators
The scale of FlashSAC's evaluation is remarkable. The authors benchmark across over 100 tasks from 10 different simulators — one of the most comprehensive evaluations in RL research.
Simulator Coverage
| Simulator | Type | Representative Tasks |
|---|---|---|
| IsaacLab | GPU | Humanoid locomotion, robot arm manipulation |
| MuJoCo | CPU | Classic control, locomotion |
| ManiSkill | GPU | Dexterous manipulation, pick-and-place |
| Genesis | GPU | Multi-body dynamics, soft-body simulation |
| HumanoidBench | GPU | Humanoid full-body tasks |
| MyoSuite | CPU | Musculoskeletal control |
| Meta-World | CPU | Multi-task manipulation benchmarks |
| DMC | CPU | DeepMind Control Suite |
Key Findings
FlashSAC outperforms PPO across the board:
- Final performance (reward): Higher on the majority of tasks
- Training speed (wall-clock time): Significantly faster, especially on GPU simulators
- Stability (variance across seeds): Lower variance, less sensitivity to random initialization
Compared to other off-policy baselines (vanilla SAC, TD3, DrQ), FlashSAC also shows clear improvements — validating that the norm bounding techniques genuinely work rather than being a marginal contribution.
Sim-to-Real: From Hours to Minutes
One of the most striking results is in sim-to-real humanoid locomotion. The authors demonstrate:
- With PPO: Training a walking policy for a humanoid robot takes hours
- With FlashSAC: The same task, same simulator, takes only minutes
The policy trained with FlashSAC in simulation transfers to the real robot without additional fine-tuning — a strong validation of the quality of policies FlashSAC produces.
This has profound implications for development workflows. Instead of waiting hours between experiments, engineers can iterate much faster. This is especially critical when tuning reward functions or testing different configurations — tasks that typically require dozens of training runs.
Installation and Usage Guide
FlashSAC is fully open-source under the MIT license. Here is how to get started.
System Requirements
- Python: 3.10 or 3.11
- GPU: NVIDIA RTX 30x0, 40x0, or 50x0 (for GPU simulators)
- Package manager: uv (recommended)
Installation
# Clone the repository
git clone https://github.com/Holiday-Robot/FlashSAC.git
cd FlashSAC
# Install dependencies with uv (10-100x faster than pip)
uv sync
If you do not have uv installed:
curl -LsSf https://astral.sh/uv/install.sh | sh
Running Training
The general syntax:
uv run python train.py --overrides env=<simulator> --overrides env.env_name='<task-name>'
Concrete examples:
# Humanoid walking on DeepMind Control Suite
uv run python train.py --overrides env=dmc --overrides env.env_name='humanoid-walk'
# Robot arm reaching on IsaacLab
uv run python train.py --overrides env=isaaclab --overrides env.env_name='reach'
# Cube manipulation on ManiSkill
uv run python train.py --overrides env=maniskill --overrides env.env_name='pick-cube'
GPU vs CPU Simulator Configuration
FlashSAC automatically adjusts its configuration based on the simulator:
- GPU simulators (IsaacLab, ManiSkill, Genesis, HumanoidBench): 1024 parallel envs, AMP enabled, CUDA buffer
- CPU simulators (MuJoCo, DMC, MyoSuite, Meta-World): 1 env, batch size 512
No manual configuration needed — just select the right simulator.
FlashSAC vs PPO: When to Use Which
Despite FlashSAC's impressive results, understanding when to use each algorithm remains important.
Choose FlashSAC when:
- You need fast iteration — reducing training time from hours to minutes
- Your task has a high-dimensional action space (humanoid, dexterous hand, musculoskeletal)
- You want sample efficiency — making the most of every collected transition
- You have a capable GPU and want to maximize utilization
Stick with PPO when:
- Your existing codebase is built around PPO and already works well
- The task is simple enough that training time is not the bottleneck
- You need distributed training across multiple nodes (PPO has a more mature ecosystem)
- You are using a framework like IsaacGym/IsaacLab with deeply integrated PPO pipelines
Long-term, if FlashSAC gets integrated into popular frameworks like rl_games or RSL-RL, it could replace PPO as the default for robotics RL.

Technical Deep Dive: Why Norm Bounding Works
For readers who want to understand the deeper mechanics, here is why FlashSAC's three norm bounding techniques are critical.
The Root Problem: The Deadly Triad
In off-policy RL, there is a well-known instability called the Deadly Triad — the combination of three factors that cause training divergence:
- Function approximation (using neural networks instead of tabular methods)
- Bootstrapping (estimating values based on other estimated values)
- Off-policy data (training on data collected by previous, potentially very different policies)
When you scale to larger models and higher-dimensional spaces, the Deadly Triad becomes more severe. Weights can grow unbounded, features become co-adapted (overly dependent on each other), and gradients explode.
FlashSAC's Solution
-
Weight norm bounding: Prevents weights from growing without limit, keeping the network in a stable region of parameter space. Unlike standard weight decay (a soft penalty), this imposes hard constraints — weights physically cannot exceed the bound.
-
Feature norm bounding: Ensures hidden representations neither collapse to zero nor explode. This preserves the network's representational capacity as it scales up, preventing the "rank collapse" phenomenon observed in large off-policy networks.
-
Gradient norm bounding: Standard gradient clipping, but with thresholds carefully calibrated for different task categories. This prevents catastrophic updates when the critic produces poor value estimates on out-of-distribution states.
Together, these three techniques form a "safety cage" around the training process, allowing FlashSAC to use much larger models without the instability that plagued vanilla SAC — effectively breaking the Deadly Triad's grip.
Implications for the Robotics Community
FlashSAC's contributions have several far-reaching implications:
1. Democratizing Humanoid RL
Previously, training humanoid locomotion policies required significant compute resources and patience. FlashSAC's speed improvements mean that a single RTX 4090 can now accomplish what previously required a multi-GPU cluster or hours of waiting. This lowers the barrier to entry for researchers and engineers working on humanoid robot control.
2. Faster R&D Cycles
The ability to train policies in minutes instead of hours fundamentally changes how engineers approach reward shaping and policy design. You can try 20 reward function variants in the time it previously took to evaluate 2. This accelerates the entire development pipeline from simulation to deployment.
3. Rethinking the On-Policy Default
For years, the robotics RL community has defaulted to PPO largely due to stability concerns with off-policy methods. FlashSAC demonstrates that these concerns can be addressed with proper normalization, potentially shifting the field's default toward off-policy methods and their inherent sample efficiency advantages.
4. Bridging Sim-to-Real
The successful sim-to-real transfer of FlashSAC-trained policies — without fine-tuning — suggests that the policies it produces are not just fast to train but also robust. This is critical for real-world robot deployment, where fragile policies trained in simulation often fail when encountering real-world perturbations.
References
- Paper: FlashSAC: Fast and Stable Off-Policy RL for High-Dimensional Robot Control — Kim, Donghu et al., 2026
- GitHub: Holiday-Robot/FlashSAC (MIT License)
- Supported simulators: IsaacLab, MuJoCo, ManiSkill, Genesis, HumanoidBench, MyoSuite, Meta-World, DMC
Conclusion
FlashSAC represents a significant step forward for RL in robotics. By combining fewer gradient updates, larger models, and three-tier norm bounding, it solves the classic instability problem of off-policy methods when scaling to high-dimensional robot control.
With benchmark results across over 100 tasks and 10 simulators, plus successful sim-to-real humanoid locomotion, FlashSAC has the potential to displace PPO as the default algorithm for training robots with RL.
If you are interested in AI for robotics, check out our full series on AI for Robotics.
Related Posts
- Reinforcement Learning Fundamentals for Robotics — RL from zero: policy gradients, value functions, and how to apply them to robot control.
- RL for Humanoid Robots: From Simulation to Reality — A deep dive into training humanoid locomotion with RL and sim-to-real transfer.
- Embodied AI 2026: The Full Landscape — An overview of embodied AI trends, from foundation models to robot learning.
