Reinforcement Learning (RL) đang là xương sống của robot control hiện đại — từ humanoid locomotion cho đến dexterous manipulation. Nhưng suốt nhiều năm qua, cộng đồng robotics gần như "mặc định" chọn PPO (Proximal Policy Optimization) làm thuật toán huấn luyện chính. Lý do? PPO ổn định, dễ tune, và hoạt động tốt với GPU-accelerated simulators.
Tuy nhiên, PPO có một nhược điểm cố hữu: nó là on-policy — mỗi batch dữ liệu thu thập xong chỉ dùng đúng một lần rồi bỏ. Lãng phí khủng khiếp.
FlashSAC — một thuật toán off-policy RL mới từ nhóm nghiên cứu Holiday-Robot — vừa thách thức trực tiếp vị trí thống trị của PPO. Kết quả? Nhanh hơn PPO, hiệu quả hơn PPO, và ổn định trên hơn 100 tasks từ 10 simulators khác nhau.
Bài viết này phân tích chi tiết paper FlashSAC: Fast and Stable Off-Policy RL for High-Dimensional Robot Control — Kim, Donghu et al., 2026.

Tại sao Off-Policy RL quan trọng?
Trước khi đi vào FlashSAC, hãy hiểu rõ sự khác biệt giữa on-policy và off-policy RL — vì đây là nền tảng để hiểu tại sao FlashSAC lại đột phá.
On-Policy (PPO, TRPO)
- Thu thập dữ liệu bằng policy hiện tại
- Dùng dữ liệu đó để cập nhật policy một lần duy nhất
- Sau đó bỏ hết dữ liệu, thu thập batch mới
- Cần rất nhiều samples để học — sample efficiency thấp
Off-Policy (SAC, TD3, DDPG)
- Lưu toàn bộ dữ liệu vào replay buffer
- Có thể dùng lại dữ liệu cũ nhiều lần để cập nhật policy
- Sample efficiency cao hơn đáng kể
- Nhưng thường không ổn định khi scale lên high-dimensional tasks
Vấn đề là: trên lý thuyết, off-policy methods nên hiệu quả hơn nhiều. Nhưng trong thực tế, khi bạn scale lên hàng nghìn parallel environments trên GPU, các thuật toán off-policy cũ (SAC, TD3) thường diverge hoặc cho kết quả tệ hơn PPO. Đây là lý do PPO vẫn thống trị trong robotics.
FlashSAC giải quyết chính xác vấn đề này.
FlashSAC: Ý tưởng cốt lõi
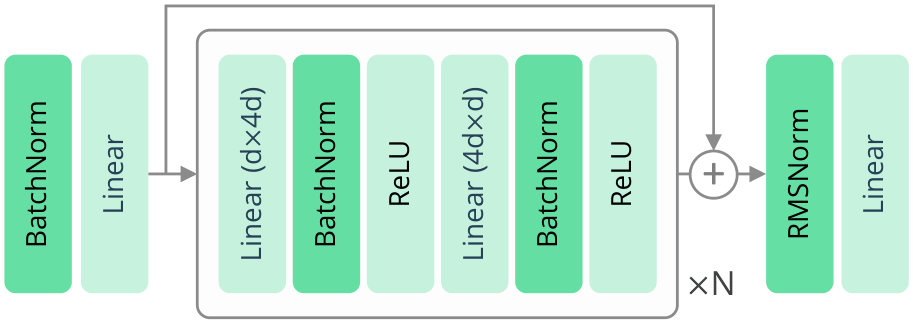
FlashSAC dựa trên SAC (Soft Actor-Critic) nhưng với ba thay đổi then chốt giúp nó ổn định ở quy mô lớn:
1. Giảm số gradient updates, bù bằng model lớn hơn
Đây là insight quan trọng nhất. Các phương pháp off-policy truyền thống thường thực hiện rất nhiều gradient updates trên mỗi batch dữ liệu (gọi là high update-to-data ratio hay UTD ratio). Điều này nghe có vẻ tốt — tận dụng dữ liệu tối đa — nhưng thực tế lại gây ra overfitting và instability.
FlashSAC đi ngược lại: giảm số gradient updates xuống tối thiểu, nhưng bù lại bằng cách:
- Dùng network lớn hơn (nhiều parameters hơn) để mỗi update học được nhiều hơn
- Tăng data throughput — thu thập nhiều dữ liệu hơn mỗi iteration
Tương tự như khi bạn học một môn học: thay vì đọc đi đọc lại cùng một trang sách 10 lần (high UTD), bạn đọc mỗi trang một lần nhưng với sự tập trung cao hơn (larger model) và đọc nhiều trang hơn mỗi phiên (higher throughput).
2. Norm bounding cho weight, feature, và gradient
Khi scale model lên kích thước lớn, các giá trị trong network có xu hướng bùng nổ (exploding) hoặc co lại (vanishing). FlashSAC giải quyết bằng cách đặt ràng buộc norm (norm bounds) trên ba cấp:
- Weight norm: Giới hạn độ lớn của trọng số mạng
- Feature norm: Chuẩn hóa các đặc trưng trung gian
- Gradient norm: Cắt gradient khi vượt ngưỡng
Ba lớp bảo vệ này đảm bảo quá trình training không bao giờ mất kiểm soát, ngay cả với model có hàng triệu parameters trên high-dimensional state spaces.
3. Thiết kế cho GPU-accelerated simulators
FlashSAC được tối ưu hóa từ đầu cho workflow hiện đại:
- GPU simulators (IsaacLab, Genesis, ManiSkill): Chạy 1024 parallel environments, sử dụng AMP (Automatic Mixed Precision) và CUDA buffer
- CPU simulators (MuJoCo, DMC): 1 environment, batch size 512
- Tận dụng tối đa bandwidth giữa simulator và learner

Kết quả: 100+ Tasks, 10 Simulators
Đây là phần ấn tượng nhất của paper. FlashSAC được benchmark trên hơn 100 tasks từ 10 simulators khác nhau — một quy mô đánh giá rất hiếm thấy trong RL research.
Danh sách simulators
| Simulator | Loại | Tasks tiêu biểu |
|---|---|---|
| IsaacLab | GPU | Humanoid locomotion, robot arm manipulation |
| MuJoCo | CPU | Classic control, locomotion |
| ManiSkill | GPU | Dexterous manipulation, pick-and-place |
| Genesis | GPU | Multi-body dynamics, soft-body |
| HumanoidBench | GPU | Humanoid full-body tasks |
| MyoSuite | CPU | Musculoskeletal control |
| Meta-World | CPU | Multi-task manipulation |
| DMC | CPU | DeepMind Control Suite |
Kết quả tổng quan
FlashSAC vượt PPO cả về:
- Performance cuối cùng (final reward): Cao hơn trên đa số tasks
- Tốc độ training (wall-clock time): Nhanh hơn đáng kể, đặc biệt trên GPU simulators
- Ổn định (variance across seeds): Thấp hơn, ít phụ thuộc vào random seed
So với các off-policy baselines khác (SAC gốc, TD3, DrQ), FlashSAC cũng cho kết quả tốt hơn rõ rệt — chứng minh rằng các kỹ thuật norm bounding thực sự hiệu quả.
Sim-to-Real: Từ giờ xuống phút
Một trong những kết quả ấn tượng nhất là sim-to-real humanoid locomotion. Nhóm tác giả cho thấy:
- Với PPO: Huấn luyện policy đi bộ cho humanoid mất hàng giờ
- Với FlashSAC: Cùng task, cùng simulator, chỉ mất vài phút
Policy huấn luyện bằng FlashSAC trong simulation chuyển sang robot thật mà không cần fine-tuning thêm — một minh chứng mạnh mẽ cho chất lượng policy mà FlashSAC tạo ra.
Điều này có ý nghĩa rất lớn cho workflow phát triển: thay vì chờ hàng giờ mỗi lần thử nghiệm, kỹ sư có thể iterate nhanh hơn gấp nhiều lần. Đặc biệt quan trọng khi bạn cần tune reward function hoặc thử các cấu hình khác nhau.
Hướng dẫn cài đặt và sử dụng
FlashSAC là open-source dưới giấy phép MIT. Dưới đây là hướng dẫn cài đặt và chạy thử.
Yêu cầu hệ thống
- Python: 3.10 hoặc 3.11
- GPU: NVIDIA RTX 30x0, 40x0, hoặc 50x0 (cho GPU simulators)
- Package manager: uv (khuyến nghị)
Cài đặt
# Clone repo
git clone https://github.com/Holiday-Robot/FlashSAC.git
cd FlashSAC
# Cài đặt với uv (nhanh hơn pip rất nhiều)
uv sync
uv là package manager mới cho Python, nhanh hơn pip từ 10-100x. Nếu chưa có, cài bằng:
curl -LsSf https://astral.sh/uv/install.sh | sh
Chạy training
Cú pháp chung:
uv run python train.py --overrides env=<simulator> --overrides env.env_name='<task-name>'
Ví dụ cụ thể:
# Humanoid walking trên DeepMind Control Suite
uv run python train.py --overrides env=dmc --overrides env.env_name='humanoid-walk'
# Robot arm trên IsaacLab
uv run python train.py --overrides env=isaaclab --overrides env.env_name='reach'
# Manipulation trên ManiSkill
uv run python train.py --overrides env=maniskill --overrides env.env_name='pick-cube'
Cấu hình cho GPU vs CPU simulators
FlashSAC tự động điều chỉnh cấu hình dựa trên simulator:
- GPU simulators (IsaacLab, ManiSkill, Genesis, HumanoidBench): 1024 parallel envs, AMP enabled, CUDA buffer
- CPU simulators (MuJoCo, DMC, MyoSuite, Meta-World): 1 env, batch size 512
Bạn không cần tự cấu hình — chỉ cần chọn đúng simulator.
So sánh với PPO: Khi nào dùng gì?
Dù FlashSAC cho kết quả ấn tượng, điều quan trọng là hiểu khi nào nên dùng thuật toán nào.
Dùng FlashSAC khi:
- Bạn cần iterate nhanh — training time từ giờ xuống phút
- Task có high-dimensional action space (humanoid, dexterous hand)
- Bạn muốn sample efficiency — không muốn lãng phí dữ liệu
- Bạn có GPU đủ mạnh và muốn tận dụng tối đa
Vẫn dùng PPO khi:
- Codebase hiện tại đã xây dựng xung quanh PPO và chạy tốt
- Task đơn giản, training time không phải bottleneck
- Bạn cần distributed training trên nhiều node (PPO có ecosystem mature hơn)
Về lâu dài, nếu FlashSAC được tích hợp vào các framework phổ biến như rl_games hoặc RSL-RL, nó có thể thay thế PPO làm mặc định trong robotics RL.

Phân tích kỹ thuật: Tại sao norm bounding hiệu quả?
Đối với bạn đọc muốn hiểu sâu hơn, đây là phần phân tích tại sao ba kỹ thuật norm bounding của FlashSAC lại quan trọng.
Vấn đề gốc rễ: Deadly Triad
Trong off-policy RL, có một hiện tượng gọi là Deadly Triad — sự kết hợp của ba yếu tố gây instability:
- Function approximation (dùng neural network)
- Bootstrapping (ước lượng value dựa trên ước lượng khác)
- Off-policy data (dữ liệu từ policy cũ)
Khi scale lên model lớn và high-dimensional spaces, Deadly Triad trở nên nghiêm trọng hơn. Weights có thể phát triển không kiểm soát, features trở nên co-adapted (phụ thuộc lẫn nhau quá mức), và gradients bùng nổ.
Giải pháp của FlashSAC
- Weight norm bounding: Ngăn weights phát triển vô hạn, giữ network trong vùng ổn định. Tương tự weight decay nhưng mạnh hơn — đặt hard constraint thay vì soft penalty.
- Feature norm bounding: Đảm bảo các hidden representations không collapse về 0 hoặc bùng nổ. Giúp network duy trì representational capacity khi scale lên.
- Gradient norm bounding: Gradient clipping chuẩn, nhưng với ngưỡng được calibrate cho từng loại task.
Ba kỹ thuật này cùng nhau tạo thành một "hàng rào bảo vệ" cho quá trình training, cho phép FlashSAC sử dụng model lớn mà không bị instability — điều mà SAC gốc không làm được.
Ý nghĩa cho ngành Robotics Việt Nam
FlashSAC mở ra nhiều cơ hội cho kỹ sư robotics, đặc biệt trong bối cảnh:
- Giảm chi phí compute: Training nhanh hơn = ít GPU hours hơn = tiết kiệm chi phí cloud
- Tăng tốc R&D cycle: Iterate nhanh hơn trên reward shaping và policy design
- Democratize humanoid RL: Trước đây cần cluster GPU để train humanoid locomotion, giờ có thể làm trên một RTX 4090
Nếu bạn đang nghiên cứu về reinforcement learning cho robot hoặc làm việc với humanoid locomotion, FlashSAC là thuật toán đáng thử nghiệm ngay.
Tài liệu tham khảo
- Paper: FlashSAC: Fast and Stable Off-Policy RL for High-Dimensional Robot Control — Kim, Donghu et al., 2026
- GitHub: Holiday-Robot/FlashSAC (MIT License)
- Simulators được hỗ trợ: IsaacLab, MuJoCo, ManiSkill, Genesis, HumanoidBench, MyoSuite, Meta-World, DMC
Kết luận
FlashSAC là một bước tiến quan trọng trong RL cho robotics. Bằng cách kết hợp ít gradient updates hơn, model lớn hơn, và norm bounding ba tầng, nó giải quyết được vấn đề instability kinh điển của off-policy methods khi scale lên high-dimensional robot control.
Với kết quả benchmark trên hơn 100 tasks và 10 simulators, cùng demo sim-to-real thành công, FlashSAC có tiềm năng thay thế PPO làm thuật toán mặc định trong huấn luyện robot bằng RL.
Nếu bạn quan tâm đến AI cho robotics, hãy theo dõi thêm các bài viết trong series AI cho Robot của chúng tôi.
Bài viết liên quan
- Reinforcement Learning cơ bản cho Robotics — Nền tảng RL từ zero, hiểu policy gradient, value function, và cách áp dụng vào robot control.
- RL cho Humanoid Robot: Từ simulation đến thực tế — Deep dive vào việc huấn luyện humanoid locomotion bằng RL, sim-to-real transfer.
- Embodied AI 2026: Toàn cảnh ngành — Tổng quan xu hướng AI embodied, từ foundation models đến robot learning.
