Vì sao bài 5 chuyển từ pixel sang ngôn ngữ?
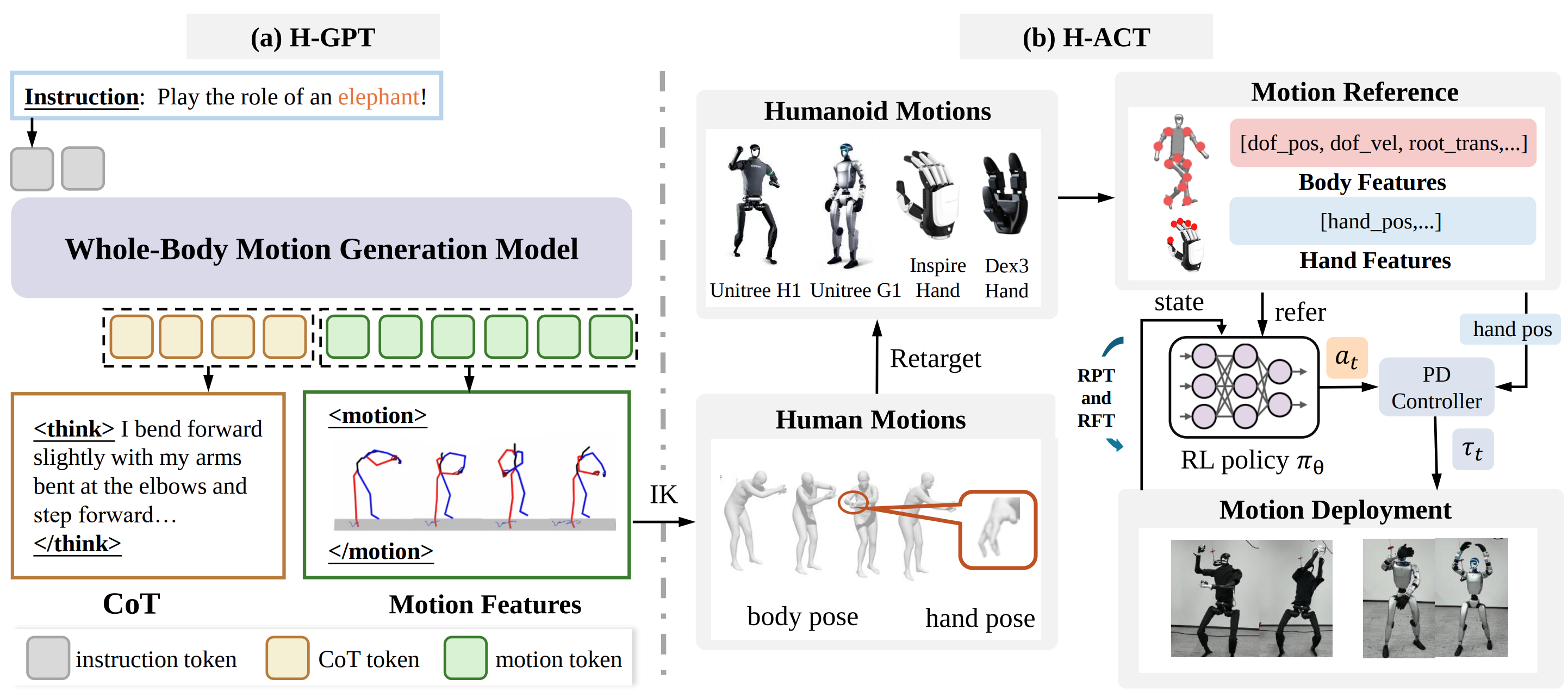
Ở bài 3 về EgoHumanoid, ta nhìn vấn đề từ hướng dữ liệu người: dùng egocentric human demonstrations để tăng độ phủ cho robot policy. Ở bài 4 về VIRAL, trọng tâm là RGB pixel-to-action: robot nhìn ảnh camera, proprioception, rồi xuất action cho loco-manipulation. FRoM-W1 đi theo một trục khác: language-conditioned whole-body motion generation. Thay vì hỏi "camera đang thấy gì, robot nên làm gì ngay bây giờ?", FRoM-W1 hỏi "câu lệnh tự nhiên này nên biến thành chuỗi chuyển động toàn thân nào, và làm sao G1 thực thi chuỗi đó ổn định?".
Repo OpenMOSS/FRoM-W1 mô tả framework gồm hai stage. Stage đầu là H-GPT, một model sinh whole-body human motion từ natural language, dùng dữ liệu human motion quy mô lớn và Chain-of-Thought để hiểu instruction tốt hơn. Stage sau là H-ACT, chuyển motion người sang robot-specific action, train motion tracking policy bằng reinforcement learning trong mô phỏng, rồi deploy qua module sim-to-real. Paper FRoM-W1 cũng nhấn mạnh cùng ý: H-GPT tạo motion người có ngữ nghĩa, H-ACT retarget và điều khiển humanoid như Unitree H1/G1 dưới ràng buộc trọng lực, tiếp xúc và actuator thật.
Bài này là bài thực hành, không phải paper review dài. Ta sẽ chạy theo QUICKSTART.md: dùng H-GPT/scripts/demo.py thông qua python -m scripts.demo, đọc configs/assets.yaml, dùng config configs/exp/1217_config_motionx_stage2_body_hands_llama_vqvae2kx1k_cotv3_t2mx.yaml, sinh motion từ scripts/instructions.txt, rồi đưa output qua H-ACT/retarget/main.py. Sau đó ta đọc các checkpoint trên Hugging Face: H-GPT LoRA adapter và H-ACT G1 student policy. Nếu bạn cần bối cảnh rộng hơn ngoài series, đọc thêm WholeBodyVLA open-source guide và GR00T VisualSim2Real trên G1.
Roadmap series
- OpenWBT: G1 teleop trong MuJoCo/Isaac: dựng môi trường và hiểu teleop whole-body có thể debug được.
- TWIST2: PICO teleop và G1 sim2real: thu dữ liệu robot bằng PICO, Redis và low-level controller.
- EgoHumanoid: human demo sang G1 VLA: nối human demo với robot action bằng view/action alignment.
- VIRAL: RGB sim2real cho G1 loco-manip: train privileged teacher, distill RGB student và deploy zero-shot.
- FRoM-W1: text → motion → G1 policy: biến câu lệnh thành human motion, retarget sang G1 và dùng policy tracking.
- CLONE: closed-loop whole-body teleop: xem closed-loop teleop như data stack dài hạn.
Mental model: H-GPT là não ngôn ngữ, H-ACT là cơ thể robot
Bạn có thể hình dung FRoM-W1 như pipeline năm bước:
Natural language instruction
"conduct an orchestra", "box", "squat", "play the role of elephant"
|
v
H-GPT
CoT reasoning + motion token generation
|
v
Whole-body human motion
623-dimensional motion features / SMPL-X-like representation
|
v
H-ACT retarget
SMPL-X / keypoints -> robot joints + dexterous hand joints
|
v
G1 motion tracking policy
pretrained / fine-tuned RL controller executes the sequence
Điểm quan trọng là FRoM-W1 không cố train một end-to-end model trực tiếp từ text sang torque. Cách đó nghe hấp dẫn nhưng rất khó debug. Câu lệnh tự nhiên có tính ngữ nghĩa cao; torque và contact lại là tầng động lực học cực thấp. FRoM-W1 chèn một đại diện trung gian: human whole-body motion. Đại diện này vừa đủ giàu để mô tả tay, chân, thân, bàn tay; vừa đủ gần con người để tận dụng dataset human motion như Motion-X và HumanML3D-X; và đủ tách biệt khỏi robot để có thể retarget sang H1, G1 hoặc hand khác.
H-GPT xử lý phần "ý định thành chuyển động người". H-ACT xử lý phần "chuyển động người thành chuyển động robot ổn định". Beginner nên nhớ ranh giới này, vì rất nhiều lỗi setup nằm ở việc trộn hai stage với nhau. Nếu scripts.demo không chạy, bạn đang debug model, dependency, Llama/LoRA, VQ-VAE hoặc dataset path của H-GPT. Nếu retarget/main.py lỗi, bạn đang debug SMPL/MANO assets, robot XML, hand type hoặc format file .npy đầu vào của H-ACT.
Nguồn kỹ thuật nên mở song song
| Nguồn | Dùng để làm gì | Điểm cần nhớ |
|---|---|---|
| FRoM-W1 README | Nhìn tổng quan repo, datasets, model checkpoints và cấu trúc thư mục | H-GPT nằm dưới H-GPT/, H-ACT nằm dưới H-ACT/ |
| FRoM-W1 QUICKSTART | Chạy minimal inference và retarget | Command H-GPT dùng --cfg_assets, --cfg, --task t2m, --example |
| H-GPT README | Hiểu tokenizer, LoRA motion generator và TRAIN.STAGE |
vae đọc motion features; lm_pretrain/lm_instruct đọc motion tokens |
| H-ACT README | Hiểu retarget, policy training và deployment | Retarget hiện hỗ trợ H1, G1, Dex3, InspireHand |
| FRoM-W1 paper | Hiểu lý do thiết kế hai stage | H-GPT sinh motion; H-ACT retarget + RL tracking + sim-to-real |
| FRoM-W1 models trên Hugging Face | Tải LoRA, tokenizer, motion tokenizer và H-ACT student | H-GPT LoRA là adapter cho Llama-3.1-8B; G1 student có model_50000.pt |
Bước 1: clone và tạo môi trường
Quickstart chính thức dùng Python 3.10. Với các repo robotics mới, đừng vội nâng version nếu README đã khóa môi trường, vì dependency như smplx, torch, pytorch3d, transformers, peft, accelerate và các thư viện visualization rất dễ lệch.
git clone -b main --single-branch [email protected]:OpenMOSS/FRoM-W1.git
cd FRoM-W1
conda create -n fromw1 python=3.10
conda activate fromw1
pip install -r requirements.txt
Nếu bạn chỉ đọc bài này để hiểu pipeline, không cần tải toàn bộ dataset. Nhưng nếu muốn chạy inference thật, bạn vẫn phải chuẩn bị dependency folder cho H-GPT. Quickstart yêu cầu H-GPT/deps/ có Llama base model, body models, GloVe files và eval models. Phần quan trọng nhất cho inference là base Meta-Llama-3.1-8B, body model SMPL-X/SMPLH/DMPL tùy stage, motion tokenizer và motion generator checkpoint. Đây là nơi nhiều người mới mắc lỗi: họ tải LoRA adapter nhưng chưa có base model, hoặc đặt checkpoint sai path trong config.
Một cấu trúc tối thiểu cần kiểm tra:
FRoM-W1/
H-GPT/
configs/
deps/
Meta-Llama-3.1-8B/
body_models/
glove_motionx/
glove_t2m/
t2m/
experiments/
scripts/
instructions.txt
H-ACT/
retarget/
assets/
data/
models/
Đừng sửa code trước khi bạn chắc rằng path checkpoint trong YAML đúng. Với H-GPT, hai path hay phải chỉnh là path tới VQ-VAE tokenizer và path tới generation model đã merge hoặc adapter đã được loader hỗ trợ. Với H-ACT retarget, hai path hay thiếu là models/smpl và models/mano.
Bước 2: chuẩn bị instruction cho H-GPT
File H-GPT/scripts/instructions.txt là đầu vào text. Bạn có thể bắt đầu bằng vài prompt ngắn, mỗi dòng một instruction:
conduct an orchestra with both hands
play the role of an elephant
perform a slow boxing combo
squat down and stand up smoothly
Không nên bắt đầu bằng instruction quá dài kiểu "walk to a red table, pick up a cup, turn right, wave to a person, then sit down". H-GPT là text-to-motion generator cho whole-body human motion, nhưng nó không phải planner scene-level có perception và object grounding như một robot VLA trong môi trường thật. Hãy bắt đầu bằng motion phrase rõ, có thể diễn bằng cơ thể người, rồi tăng độ khó sau.
Nếu prompt quá trừu tượng, CoT có thể giúp model phân rã ý định thành motion primitive, nhưng không đảm bảo output phù hợp với giới hạn động lực học của G1. Ví dụ "play the role of an elephant" có thể sinh motion vẫy tay như vòi, cúi thân và bước chậm. H-GPT thấy motion này hợp ngữ nghĩa, nhưng H-ACT vẫn phải retarget sang khung chân, khớp tay, bàn tay và policy tracking có thể bám được. Vì vậy ta luôn kiểm tra visualization trước khi đưa motion sang robot stack.
Bước 3: chạy H-GPT/scripts/demo.py
Theo QUICKSTART.md, command minimal inference như sau:
cd H-GPT
CUDA_VISIBLE_DEVICES=0 python -m scripts.demo \
--cfg_assets ./configs/assets.yaml \
--cfg configs/exp/1217_config_motionx_stage2_body_hands_llama_vqvae2kx1k_cotv3_t2mx.yaml \
--task t2m \
--example ./scripts/instructions.txt
Về bản chất, lệnh này gọi module scripts.demo, tương ứng file H-GPT/scripts/demo.py. Bốn flag quan trọng:
| Flag | Ý nghĩa | Lỗi thường gặp |
|---|---|---|
--cfg_assets ./configs/assets.yaml |
Khai báo asset path chung: model, body model, tokenizer, dependency | Path trong YAML trỏ tới thư mục chưa tải |
--cfg configs/exp/1217_config_motionx_stage2_body_hands_llama_vqvae2kx1k_cotv3_t2mx.yaml |
Config experiment cho body + hands, Llama, VQ-VAE 2k x 1k, CoT v3, task t2mx | Checkpoint không khớp với config tokenizer |
--task t2m |
Chạy text-to-motion inference | Dùng sai task làm loader đọc nhầm branch |
--example ./scripts/instructions.txt |
File instruction đầu vào | File rỗng, encoding lỗi hoặc prompt quá dài |
Output thường nằm trong H-GPT/results/<result_folder>. Tên folder tùy timestamp/config. Sau khi generate, bạn nên visualize:
python -m hGPT.data.motionx.visualization.plot_3d_global \
--path ./results/<result_folder>
Ở bước visualization, bạn không tìm "đẹp như demo video" ngay. Bạn tìm ba tín hiệu cơ bản: motion có đúng ý không, tay/chân không nổ tung, và chiều dài sequence hợp lý. Nếu nhân vật bị xoắn tay, bay khỏi mặt đất hoặc bàn tay giật liên tục, đừng đưa thẳng sang retarget. Retarget không sửa được một motion nguồn đã hỏng; nó chỉ chuyển một motion người hợp lý sang embodiment robot.
Bước 4: hiểu ba TRAIN.STAGE của H-GPT
Bạn không cần train lại H-GPT để chạy quickstart, nhưng hiểu TRAIN.STAGE giúp bạn debug config đúng. README H-GPT chia training thành ba stage:
TRAIN.STAGE |
Tên stage | Input chính | Output chính | Khi nào đụng tới |
|---|---|---|---|---|
"vae" |
VQ-VAE tokenizer | Raw whole-body motion features từ MOTION_FEAT_PATH |
Motion tokens rời rạc, codebook, decoder | Khi muốn train tokenizer mới hoặc đổi motion representation |
"lm_pretrain" |
LM pretrain | Pre-computed motion tokens từ MOTION_TOKEN_PATH |
Llama-3.1-8B fine-tuned bằng LoRA để sinh motion tokens | Khi muốn học text-to-motion trên dataset nền |
"lm_instruct" |
LM instruct | Motion tokens + instruction/CoT data | Model follow instruction tốt hơn, có khả năng xử lý prompt trừu tượng hơn | Khi muốn cải thiện natural language generalization |
Stage "vae" giống việc học một "bảng chữ cái chuyển động". Motion liên tục rất khó cho language model, nên VQ-VAE nén chuyển động thành token rời rạc. Stage "lm_pretrain" học ngôn ngữ của các token đó: khi thấy câu lệnh và context, model dự đoán chuỗi motion token tiếp theo. Stage "lm_instruct" làm model nghe lời người dùng tốt hơn, đặc biệt với prompt không chỉ là action label đơn giản. FRoM-W1 dùng Chain-of-Thought để biến instruction thành mô tả motion có cấu trúc thời gian trước khi sinh token.
Checkpoint H-GPT trên Hugging Face là điểm cần đọc kỹ. Ví dụ thư mục H-GPT HumanML3D-X CoT LoRA chứa adapter_config.json, adapter_model.safetensors và tokenizer files. Đây là LoRA adapter, không phải full base Llama. Nếu bạn thấy lỗi thiếu weight của Llama, nguyên nhân thường là base model chưa nằm đúng H-GPT/deps/Meta-Llama-3.1-8B hoặc merge script chưa chạy đúng.
Bước 5: copy motion sang H-ACT retarget
Sau khi H-GPT sinh motion, H-ACT cần file motion feature sequence trong folder H-ACT/retarget/data/623. Quickstart mô tả cấu trúc:
H-ACT/retarget/data/
623/
data1.npy
data2.npy
smplx/
output/
Folder 623 lưu motion data 623 chiều do H-GPT sinh ra. Folder smplx lưu intermediate SMPL-X motion sequence. Folder output lưu final robot và dexterous-hand joint sequence. Với beginner, cách làm ít rủi ro là chạy một file example repo đã cung cấp trước, đảm bảo retarget pipeline hoạt động, rồi mới thay bằng output H-GPT của bạn.
Trước khi chạy retarget, tải model người và hand:
H-ACT/retarget/models/
smpl/
SMPL_NEUTRAL.pkl
SMPL_MALE.pkl
SMPL_FEMALE.pkl
mano/
MANO_LEFT.pkl
MANO_RIGHT.pkl
Sau đó tải retarget assets từ Hugging Face và đặt dưới:
H-ACT/retarget/assets/
beta/
meta/
robot/
dex3/
g1/
h1/
inspire/
Hai dependency này có license riêng, nên repo không thể luôn đóng gói sẵn mọi file. Nếu main.py lỗi ngay khi load SMPL hoặc MANO, đừng debug policy. Đây vẫn là lỗi asset. Nếu nó load robot XML nhưng output shape lạ, lúc đó mới xem target robot/hand type.
Bước 6: chạy H-ACT/retarget/main.py
Command chính thức rất ngắn:
cd ../H-ACT/retarget
python main.py
Nhưng điều quan trọng nằm trong cấu hình bên trong main.py. Quickstart ghi rõ có thể chỉnh các dòng chọn robot và hand:
robot_data = process_data(amass_data, "G1")
hand_data = retarget_from_rotvec(smpl_dict["poses"][:, 66:], hand_type="dex3")
"G1" là target robot. hand_type="dex3" chọn dexterous hand. Quickstart cũng nêu các lựa chọn robot/hand hiện có gồm Unitree H1, Unitree G1, Inspire Hand và Dex3 Hand. Nếu lab của bạn dùng G1 nhưng không có Dex3, cần kiểm tra lại cấu hình hand và deployment stack. Retarget đúng robot nhưng sai hand có thể khiến output nhìn hợp ở thân dưới nhưng hỏng ở bàn tay.
Một output log ví dụ có thể gồm tensor nhỏ, dòng load Mujoco kinematics và shape như (256, 29). Đừng đọc con số này như guarantee rằng motion đã sẵn sàng chạy trên hardware. Nó chỉ nói pipeline retarget đã tạo ra sequence. Bạn vẫn cần viewer, simulation tracking và safety gate trước khi robot thật nhận lệnh.
Bước 7: từ retarget sequence sang G1 policy
Retarget chỉ cho bạn reference motion. G1 thật không tự bám reference chỉ vì ta có joint angles. Humanoid cần controller ổn định trước trọng lực, ground contact, actuator delay, giới hạn torque và sai số morphology. Đây là lý do H-ACT có policy stage.
H-ACT dựa trên hướng motion tracking bằng RL. README H-ACT nói module này xây trên Human2Humanoid và cung cấp action execution policy hỗ trợ Unitree H1/G1. Trên Hugging Face, thư mục G1 OmniH2O student có env_cfg.json, train_cfg.json và model_50000.pt; bản G1 OmniH2O student filter có cấu trúc tương tự. Tên STUDENT ở đây nên hiểu là tracking policy checkpoint đã train cho G1, không phải H-GPT language model.
Pipeline đầy đủ sau retarget thường là:
H-GPT output .npy
-> H-ACT retarget output .pkl
-> motion asset folder của deployment/tracking framework
-> G1 motion controller config trỏ tới motion_name
-> sim tracking smoke test
-> real robot deployment qua safety interface
Quickstart nhắc tới RoboJuDo như deployment framework: copy file retargeted g1+dex3 vào motion asset directory, chỉnh motion_name trong config G1 motion control, rồi chạy pipeline simulation. Bài này không đi sâu deploy robot thật, vì chỉ cần sai một giới hạn joint hoặc latency là robot có thể ngã. Với lab mới, mục tiêu hợp lý là chạy được H-GPT, retarget được G1, xem policy tracking trong sim, rồi mới bàn tới hardware.
Debug checklist cho beginner
| Triệu chứng | Khả năng cao | Cách xử lý |
|---|---|---|
scripts.demo báo thiếu Llama weights |
Chỉ tải LoRA, chưa tải base model | Tải Meta-Llama-3.1-8B và kiểm tra path trong assets.yaml |
| Output motion rỗng hoặc rất ngắn | instructions.txt format lỗi hoặc prompt không hợp task |
Thử một prompt đơn giản như squat down and stand up |
| Visualization bị xoắn thân/tay | Checkpoint/tokenizer không khớp config hoặc motion quá ngoài distribution | Dùng đúng config 1217...t2mx.yaml, thử prompt ngắn hơn |
retarget/main.py lỗi SMPL/MANO |
Thiếu model file có license riêng | Đặt SMPL_*.pkl và MANO_*.pkl đúng folder |
| Retarget chạy nhưng output hand sai | Chọn sai hand_type hoặc thiếu asset hand |
Kiểm tra dex3/inspire trong assets/robot |
| Sim policy tracking ngã nhanh | Motion nguồn quá khó, controller không phù hợp hoặc chưa fine-tune | Test motion ngắn, giảm tốc, dùng checkpoint G1 đúng embodiment |
Điều cần tránh là debug từ cuối pipeline. Nếu robot tracking ngã, không có nghĩa H-ACT policy dở. Có thể H-GPT sinh motion quá nhanh, retarget tạo joint path vượt giới hạn, hoặc motion không hợp contact. Hãy kiểm tra từng tầng: text → visualization → retarget output → sim tracking → hardware.
FRoM-W1 so với VIRAL
FRoM-W1 và VIRAL đều phục vụ humanoid whole-body intelligence, nhưng chúng không giải cùng một bài toán đầu vào.
| Trục so sánh | FRoM-W1 | VIRAL |
|---|---|---|
| Input chính | Natural language instruction | RGB image + proprioception |
| Đại diện trung gian | Human whole-body motion, SMPL-X/623D features, robot retarget sequence | Privileged teacher action, RGB student observation |
| Stage chính | H-GPT sinh motion; H-ACT retarget + tracking policy | PPO teacher trong sim; RGB student DAgger/BC |
| Thế mạnh | Tạo motion toàn thân theo câu lệnh mở, có thể dùng một instruction cho nhiều embodiment/policy | Pixel-to-action cho loco-manipulation trong scene có object, camera, ánh sáng, vật liệu |
| Rủi ro | Motion hợp ngữ nghĩa nhưng khó bám động lực học; cần retarget và tracking tốt | Cần simulation scale lớn, domain randomization và camera/hand alignment |
| Khi dùng | Demo kỹ năng kiểu dance, squat, boxing, gesture, motion library theo text | Task cần nhìn vật thể và phản ứng theo scene như place, grasp, transport |
VIRAL là câu trả lời mạnh cho "robot đang nhìn scene này, làm sao hành động?". Nó học từ simulation, teacher có privileged state, student chỉ dùng RGB/proprioception và deploy zero-shot. FRoM-W1 là câu trả lời cho "người dùng nói một kỹ năng, làm sao biến nó thành whole-body motion executable?". Nó không thay thế perception policy; nó tạo motion prior và motion library rất hữu ích cho controller, retargeting, demo generation và language-conditioned skill interface.
Trong lab thực tế, hai hướng này bổ sung nhau. FRoM-W1 có thể tạo candidate motions từ text để làm reference, warm-start hoặc data augmentation. VIRAL có thể xử lý closed-loop visual corrections khi robot tương tác với object thật. Nếu chỉ có FRoM-W1, robot có thể thực hiện motion đẹp nhưng không biết cái hộp thật đang lệch 10 cm. Nếu chỉ có VIRAL, robot có thể thao tác theo scene nhưng không có giao diện language-to-motion phong phú cho kỹ năng biểu cảm, gesture hoặc motion library đa dạng.
Một workflow thực tế cho lab G1
Nếu bạn có một workstation 4090 và một G1 trong lab, đừng đặt mục tiêu "text prompt chạy ngay trên robot thật" trong ngày đầu. Workflow an toàn hơn:
- Chạy H-GPT với 3 prompt ngắn: squat, box, conduct orchestra.
- Visualize từng motion và loại bỏ motion giật, xoắn hoặc quá nhanh.
- Retarget từng file qua
H-ACT/retarget/main.pysang G1 + hand đúng. - Chạy tracking trong simulation, log joint error, base drift và contact failure.
- Chọn một motion chậm, ít contact phức tạp, ví dụ squat hoặc gesture tay.
- Chỉ khi sim ổn định, mới đưa qua deployment framework có E-stop, joint limit, torque limit và vùng trống quanh robot.
Với beginner, thành công đầu tiên không phải là "robot diễn như video project page". Thành công đầu tiên là bạn hiểu file nào đi qua stage nào, biết khi nào lỗi thuộc H-GPT, khi nào thuộc retarget, khi nào thuộc policy tracking. Khi pipeline đã rõ, bạn mới tăng độ khó prompt và đổi embodiment.
Kết luận
FRoM-W1 là stack thứ năm trong series vì nó lấp khoảng trống mà các pipeline pixel-to-action không trực tiếp giải: biến ngôn ngữ tự nhiên thành whole-body motion có thể retarget sang humanoid. H-GPT tạo motion người từ text bằng tokenizer + Llama LoRA + CoT. H-ACT biến motion đó thành robot sequence, rồi dùng policy tracking để G1 thực thi ổn định hơn trong mô phỏng và ngoài đời.
Điểm thực dụng nhất của FRoM-W1 không nằm ở một command duy nhất. Nó nằm ở việc tách bài toán thành các boundary dễ kiểm tra: text input, generated motion, SMPL-X/intermediate representation, retargeted G1 joints, tracking policy. Khi bạn debug theo boundary này, FRoM-W1 trở thành một lab stack rất tốt để xây motion library language-conditioned cho humanoid.


