Mục tiêu của bài này
Đến bài cuối của series, ta không còn hỏi "làm sao record một episode?" nữa. Câu hỏi thực tế là: nếu có 20 operator, một humanoid whole-body VLA, nhiều task dài hơn 30 giây, và một controller chân chạy realtime, làm sao biết hệ thống đang tốt lên hay chỉ đang tạo thêm dữ liệu nhiễu?
Trong bài 1, ta bắt đầu bằng pilot 2 người để đo throughput và lỗi cơ bản. Bài 3 chuẩn hóa raw log bằng ROS 2 và MCAP để còn replay. Bài 5 dùng synthetic data và QA để lọc demo trước khi train. Bài 6 ghép các phần đó thành một bảng đánh giá vận hành cho 20 operator.
Ta lấy WholeBodyVLA làm mô hình tham chiếu vì paper và project page mô tả đúng bài toán đang cần: humanoid AgiBot X2 thực hiện loco-manipulation trong không gian lớn, dùng Latent Action Model (LAM) để học latent action tokens từ video egocentric không có action annotation, VLM decode khoảng 10 Hz, và Loco-Manipulation-Oriented RL policy (LMO) chạy 50 Hz trên proprioception. Nguồn chính nên đọc:
- WholeBodyVLA project page
- WholeBodyVLA arXiv HTML
- OpenDriveLab WholebodyVLA GitHub
- AGIBOT X2 product page
- GR00T WholeBodyControl documentation
- NVlabs GR00T-WholeBodyControl repository
Ngoài series này, hai bài nền hữu ích là Huấn luyện tracker và LMO RL và Bản đồ repo VLA/WBC cho humanoid. Nếu bạn đang xây dashboard nội bộ, bài này nên được đọc như một spec cho bảng metric đầu tiên.

Kiến trúc cần đánh giá
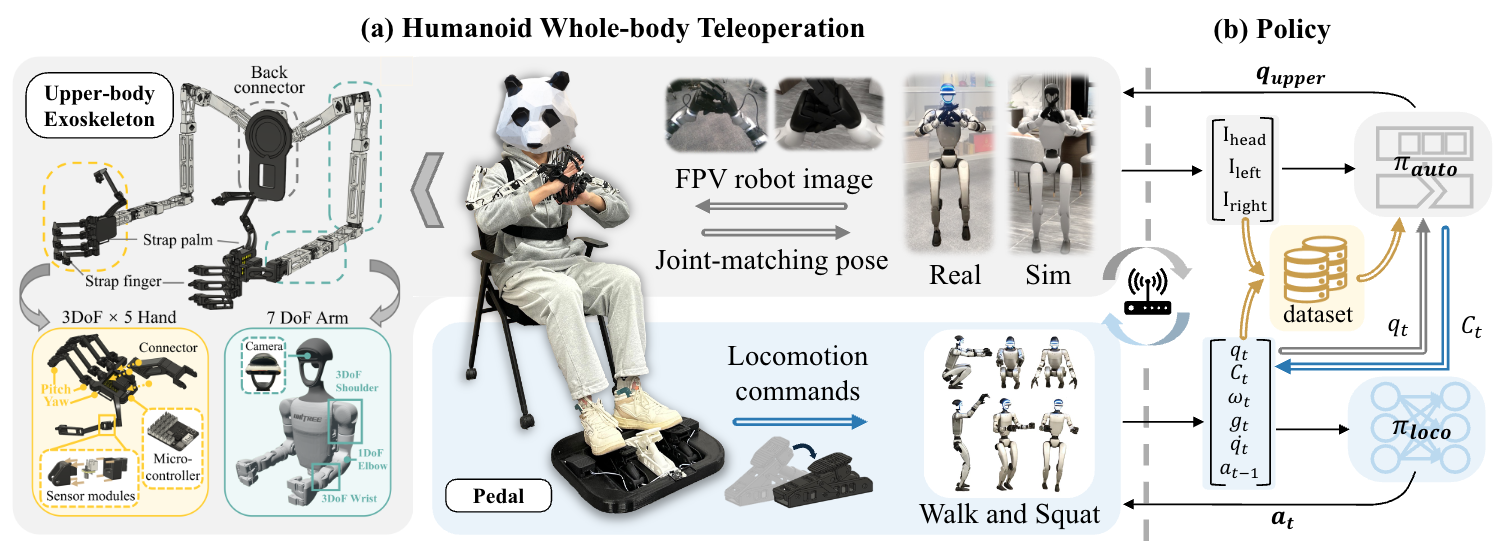
Một hệ whole-body VLA không giống robot arm chỉ chạy policy ảnh sang pose tay. Trong humanoid, quyết định high-level và ổn định cơ thể có tần số khác nhau. WholeBodyVLA mô tả runtime như sau: ảnh egocentric và instruction được VLM encode thành latent action tokens; action decoder phát dual-arm joint actions và locomotion commands khoảng 10 Hz; LMO RL policy nhận proprioceptive state và chạy 50 Hz để thực thi locomotion command. Paper cũng nêu deployment tách máy: VLA chạy trên workstation RTX 4090, RL policy chạy trên onboard computer, giao tiếp qua ZeroMQ over Ethernet.
Với beginner, hãy hình dung hệ thống thành ba vòng lặp:
camera + language
|
v
VLM / LAM action decoder (~10 Hz)
| \
| -> dual-arm joint actions
v
locomotion command: forward, sidestep, turn, squat
|
v
LMO RL policy on proprioception (50 Hz)
|
v
whole-body robot + WBC / PD / safety layer
Điểm quan trọng: bảng đánh giá phải tách lỗi của từng vòng. Nếu task fail vì robot không hiểu instruction, đó là lỗi VLA/perception. Nếu robot hiểu đúng nhưng bước ngang lệch và mất vị trí đặt, đó là lỗi locomotion command hoặc LMO. Nếu policy chân ổn nhưng tay đẩy hộp làm robot mất thăng bằng, đó là lỗi whole-body coupling. Nếu dữ liệu bị loại vì camera lệch timestamp, đó là lỗi data pipeline, không phải lỗi model.
Trong thực tế, nhiều nhóm cũng muốn so sánh hoặc thay thế low-level stack bằng GR00T WholeBodyControl. Tài liệu GR00T WBC mô tả đây là nền tảng cho controller humanoid, có decoupled WBC dùng trong Isaac GR00T / GR00T N1.x và hỗ trợ workflow teleop, VLA data collection, inference. Với Unitree G1, repo có các ONNX policy đáng chú ý:
GR00T-WholeBodyControl-Balance.onnx
GR00T-WholeBodyControl-Walk.onnx
Hai file này không làm AgiBot X2 tự nhiên biến thành G1, và cũng không thay thế trực tiếp LMO của WholeBodyVLA nếu morphology khác. Nhưng chúng cho ta một pattern deploy rõ: low-level controller phải được export thành artifact ổn định, load được trong runtime, đo latency được, và có mode balance/walk tách bạch để kiểm thử an toàn.
Vì sao scale 20 operator phải có eval trước?
Khi chỉ có 2 operator, bạn có thể xem từng episode bằng mắt. Khi lên 20 operator, dữ liệu xấu sẽ tăng theo cấp số vận hành: người mới điều khiển quá nhanh, prompt đặt không thống nhất, scene reset lệch, robot bị fatigue nhiệt, camera bị lệch mount, và một số người có tỷ lệ discard cao nhưng không ai phát hiện trong ngày.
Mục tiêu của eval không phải xếp hạng con người. Mục tiêu là giữ cho hệ thống học từ dữ liệu tốt hơn qua từng tuần. Vì vậy dashboard nên trả lời sáu câu:
| Câu hỏi | Metric chính | Ai dùng metric |
|---|---|---|
| Robot hoàn thành task không? | Task success | Research lead, model owner |
| Robot có ngã hoặc mất ổn định không? | Balance failures | Safety owner, WBC owner |
| Operator phải can thiệp nhiều không? | Intervention rate | Ops lead, trainer |
| Vòng điều khiển có trễ không? | Latency | Infra, realtime owner |
| Episode có đủ sạch để train không? | Data acceptance | Data QA, training owner |
| Lỗi nằm ở task nào? | Benchmark breakdown | Product, research, ops |
Nếu thiếu một trong sáu metric này, bạn rất dễ scale sai. Ví dụ task success tăng nhưng intervention rate cũng tăng, nghĩa là operator đang cứu robot nhiều hơn chứ model chưa chắc tốt hơn. Hoặc data acceptance cao nhưng latency jitter tăng, dataset có thể vẫn save được nhưng policy train ra sẽ học hành vi lệch thời gian.
Bảng KPI cho 20 operator
Bảng dưới đây là baseline tốt cho tuần đầu khi mở rộng từ pilot lên 20 operator. Mỗi operator làm 3 task: bag packing, box loading, cart pushing. Mỗi task có 10 trial/người/ngày ở phase eval, sau đó mới tăng số lượng thu dữ liệu training.
| Metric | Định nghĩa | Công thức gợi ý | Ngưỡng tuần 1 |
|---|---|---|---|
| Task success | Task đạt tiêu chí cuối cùng mà không vi phạm safety | success_trials / total_trials |
Theo task, không gộp mù |
| Subgoal success | Từng bước như grasp, sidestep, squat, place | subgoal_pass / total_trials |
Ít nhất log 2 subgoal/task |
| Balance failure | Fall, emergency stop vì nghiêng, CoM/IMU vượt ngưỡng | balance_fail_trials / total_trials |
Càng gần 0 càng tốt |
| Intervention rate | Operator bấm pause, reset, manual override, hoặc safety captain cứu scene | interventions / minute hoặc trials_with_intervention / trials |
Giảm theo từng tuần |
| Command latency | Từ frame camera/state đến action command được robot nhận | p50, p95, p99 | Theo từng loop 10 Hz và 50 Hz |
| Loop miss rate | VLA hoặc LMO miss deadline | missed_ticks / expected_ticks |
LMO nghiêm hơn VLA |
| Data acceptance | Episode được QA cho vào training set | accepted_episodes / recorded_episodes |
Không nên chỉ tối đa hóa |
| Discard reason | Lý do loại episode | taxonomy cố định | Bắt buộc có |
| Operator throughput | Episode accepted/giờ | accepted / active_hours |
So với median nhóm |
| Recovery time | Thời gian từ fail đến trial tiếp theo | median, p90 | Dùng để tối ưu ops |
Một schema CSV tối thiểu:
date,operator_id,robot_id,task,trial_id,success,subgoal_1,subgoal_2,balance_failure,interventions,accepted,discard_reason,vla_p95_ms,lmo_p95_ms,total_seconds
2026-06-10,op_03,x2_01,bag_packing,trial_004,true,true,true,false,0,true,,118,8,42.6
2026-06-10,op_03,x2_01,box_loading,trial_005,false,true,false,false,1,false,place_miss_after_turn,126,9,51.2
2026-06-10,op_11,x2_01,cart_pushing,trial_002,false,true,false,true,2,false,balance_push_load,135,11,28.4
Đừng bắt đầu bằng dashboard phức tạp. Bắt đầu bằng một bảng sự kiện sạch. Nếu mỗi row có task, operator, trial, success, failure mode và latency, bạn đã có đủ dữ liệu để quyết định tuần sau cần train operator, sửa controller hay thu thêm dataset.
Định nghĩa success cho ba benchmark
WholeBodyVLA dùng ba task chính: Bag Packing, Box Loading và Cart Pushing. Project page mô tả chuỗi hành động gồm bimanual grasping, side-step, squat, grasp/lift box, turn to cart, grasp cart handle, push forward, và đẩy tải hơn 50 kg. Appendix paper mô tả thêm các biến thể object/load: thay bag bằng bag khác, thay đồ trong box bằng plastic containers, và thay carton trên cart bằng 60 kg barbell plates.
Ta không cần copy nguyên benchmark để bắt đầu, nhưng cần giữ tinh thần: mỗi task phải buộc robot phối hợp chân, tay, thân và thăng bằng.
| Task | Subgoal 1 | Subgoal 2 | Success cuối | Failure mode nên log |
|---|---|---|---|---|
| Bag Packing | Grasp bag bằng hai tay hoặc tay chính theo setup | Sidestep/squat tới carton | Bag nằm trong carton, robot vẫn ổn định | miss grasp, bag drop, squat drift, place outside |
| Box Loading | Squat và grasp box | Rise, turn toward cart | Box đặt lên cart đúng vùng | box tilt, turn overshoot, hand slip, torso lean |
| Cart Pushing | Grasp handle | Push ahead theo đường | Cart đi đủ khoảng cách, robot không drift/lệch mạnh | handle miss, lateral drift, foot slip, balance fail |
Với beginner, hãy luôn tách task_success và subgoal_success. Một trial box loading có thể fail ở bước place nhưng vẫn chứng minh squat + grasp đã tiến bộ. Nếu chỉ lưu success cuối cùng, model owner không biết nên sửa perception, action decoder hay LMO.
Một cấu hình benchmark YAML dễ đọc:
benchmark:
name: humanoid_wholebody_vla_eval_v1
robot: agibot_x2
trials_per_operator_per_task: 10
operators: 20
tasks:
bag_packing:
subgoals: [grasp_bag, move_and_squat, place_in_carton]
success:
object_in_target: true
no_balance_failure: true
max_interventions: 0
box_loading:
subgoals: [squat_and_grasp, rise_and_turn, place_on_cart]
success:
box_on_cart: true
no_balance_failure: true
max_interventions: 0
cart_pushing:
subgoals: [grab_handle, push_ahead]
success:
cart_distance_m: 2.0
lateral_drift_m_max: 0.35
no_balance_failure: true
Latency: đo riêng 10 Hz và 50 Hz
WholeBodyVLA cho ta một bài học quan trọng: VLA và LMO không chạy cùng tần số. VLA khoảng 10 Hz có thể chấp nhận inference chậm hơn vì nó làm perception/reasoning và phát command mức cao. LMO 50 Hz thì không được jitter nhiều, vì nó giữ locomotion và balance trên proprioception.
Vì vậy bảng latency nên có hai lớp:
| Lớp | Tần số | Đo gì | Vì sao |
|---|---|---|---|
| VLA decode | Khoảng 10 Hz | camera timestamp -> latent/action decoded -> command sent | Trễ cao làm instruction/action bị lỗi thời |
| LMO/WBC loop | 50 Hz | proprio read -> policy inference -> action applied | Jitter cao làm gait và balance xấu |
| Network bridge | Tùy stack | command sent -> command received | ZeroMQ/ROS 2/Ethernet có thể tạo spike |
| Data recorder | Tùy camera | frame saved -> metadata indexed | Recorder chậm làm data lệch dù robot vẫn chạy |
Instrumentation tối thiểu:
from time import monotonic_ns
def now_ms():
return monotonic_ns() / 1_000_000
event = {
"trial_id": trial_id,
"camera_frame_ts_ms": frame.ts_ms,
"vla_decode_start_ms": now_ms(),
}
latent_action = vla.decode(frame, instruction)
event["vla_decode_end_ms"] = now_ms()
command = action_decoder.to_robot_command(latent_action)
event["command_sent_ms"] = now_ms()
command_bus.send(command)
# On the low-level side:
low_event = {
"command_received_ms": now_ms(),
"proprio_ts_ms": proprio.ts_ms,
"lmo_start_ms": now_ms(),
}
action = lmo_policy(proprio, command)
low_event["lmo_end_ms"] = now_ms()
robot.apply(action)
low_event["action_applied_ms"] = now_ms()
Sau đó tính p50/p95/p99 theo task và theo operator. Nếu p95 VLA tăng ở cart pushing, có thể camera scene phức tạp hơn hoặc model decode dài hơn do prompt. Nếu p95 LMO tăng, ưu tiên debug onboard compute, thread scheduling, memory allocation, logging hoặc network receive. Đừng trộn hai lớp latency vào một số trung bình.
Balance failures và intervention rate
Balance failure phải được định nghĩa chặt. Nếu mỗi người hiểu "suýt ngã" khác nhau, dashboard sẽ vô nghĩa. Hãy bắt đầu với bốn nhãn:
| Nhãn | Điều kiện |
|---|---|
fall |
Robot chạm đất hoặc cần reset vật lý |
estop_balance |
Emergency stop vì nghiêng, trượt chân hoặc mất kiểm soát |
operator_catch |
Người can thiệp để robot không va/ngã |
controller_abort |
Safety layer tự dừng do state vượt ngưỡng |
Intervention cũng cần taxonomy:
intervention_types:
pause: operator pauses policy but keeps trial alive
manual_override: operator takes over motion
scene_fix: human fixes object/scene during trial
safety_stop: emergency stop or safety abort
prompt_correction: instruction changed after trial start
Trong báo cáo training, trial có intervention thường không nên tính là success sạch. Có thể lưu hai cột:
| Cột | Ý nghĩa |
|---|---|
task_success_raw |
Object/task cuối cùng đạt yêu cầu, kể cả có can thiệp |
task_success_clean |
Đạt yêu cầu mà không có intervention bị cấm |
Khi mở rộng 20 operator, task_success_clean mới là metric để so sánh model. task_success_raw hữu ích cho ops vì nó cho biết operator có cứu được task không, nhưng nếu dùng để chọn checkpoint thì dễ tự lừa.
Data acceptance: episode nào được train?
Data acceptance không đồng nghĩa với task success. Một episode fail vẫn có thể hữu ích nếu nó ghi rõ failure và dùng cho negative analysis. Nhưng dataset behavior cloning/VLA chính nên ưu tiên episode thành công, timestamp sạch, prompt đúng, không có intervention, và không có sensor drop.
Checklist acceptance:
| Kiểm tra | Accept nếu | Reject nếu |
|---|---|---|
| Prompt | Khớp task và object | Prompt đổi giữa trial hoặc quá mơ hồ |
| Camera | Đủ frame, không mất exposure nặng | Drop dài, blur mạnh ở giai đoạn quyết định |
| State/action | Shape đúng, timestamp tăng đều | NaN, joint order sai, action spike không giải thích được |
| Latency | Nằm trong budget | p99 vượt budget ở đoạn quan trọng |
| Safety | Không fall/estop | Fall hoặc human catch |
| Outcome | Success hoặc failure có nhãn rõ | Không biết vì sao fail |
Một rule engine đơn giản:
def accept_episode(ep):
if ep.prompt_changed:
return False, "prompt_changed"
if ep.camera_drop_ms_max > 250:
return False, "camera_drop"
if ep.state_has_nan or ep.action_has_nan:
return False, "bad_state_action"
if ep.balance_failure:
return False, "balance_failure"
if ep.interventions > 0:
return False, "intervention"
if ep.vla_latency_p99_ms > 250:
return False, "vla_latency"
if ep.lmo_latency_p99_ms > 20:
return False, "lmo_latency"
if not ep.task_success:
return False, "task_fail"
return True, ""
Các ngưỡng trên chỉ là điểm bắt đầu. Với stack thật, hãy lấy distribution từ pilot và đặt budget theo hardware. Điều quan trọng là mọi reject phải có reason cố định, để cuối tuần bạn biết 38% reject đến từ operator training, camera, model hay controller.
Lịch vận hành cho 20 operator
Đừng cho 20 người thu production data ngay ngày đầu. Chia thành ba vòng:
| Vòng | Số người | Mục tiêu | Gate để qua vòng |
|---|---|---|---|
| Calibration | 4 | So sánh operator mới với 2 người pilot | Prompt đúng, intervention taxonomy đúng |
| Eval batch | 20 | Mỗi người chạy cùng benchmark nhỏ | Có bảng success/balance/latency/data acceptance |
| Production | 20 | Thu data theo task ưu tiên | Chỉ mở task/operator đạt gate |
Gate gợi ý:
operator_gate:
min_trials: 30
prompt_error_rate_max: 0.02
unsafe_intervention_rate_max: 0.05
accepted_episode_rate_min: 0.70
median_reset_seconds_max: 90
robot_gate:
balance_failure_rate_max: 0.02
lmo_loop_miss_rate_max: 0.01
no_unexplained_estop: true
model_gate:
clean_success_rate_min_by_task:
bag_packing: 0.60
box_loading: 0.45
cart_pushing: 0.50
Các con số này không phải benchmark học thuật. Chúng là guardrail vận hành. Nếu tuần đầu chưa đạt, đừng cố thu nhiều hơn. Hãy sửa failure mode lớn nhất trước. Scale dữ liệu xấu chỉ làm chi phí train, QA và debug tăng.
Dashboard tuần đầu nên trông như thế nào?
Một dashboard tốt không cần đẹp, nhưng phải ra quyết định được. Tôi thường dùng bốn bảng:
| Bảng | Cột bắt buộc | Quyết định hỗ trợ |
|---|---|---|
| Operator scorecard | operator, trials, clean success, interventions, accepted rate, median reset | Ai cần train lại, ai được mở production |
| Task scorecard | task, subgoal success, balance fail, latency p95, top discard reason | Task nào đang nghẽn |
| Latency health | VLA p50/p95/p99, LMO p50/p95/p99, loop miss | Có cần sửa infra/realtime không |
| Data QA | accepted, rejected, reject reason, camera drop, prompt error | Dataset có đáng train không |
SQL mẫu cho operator scorecard:
select
operator_id,
count(*) as trials,
avg(case when task_success_clean then 1 else 0 end) as clean_success_rate,
avg(interventions) as interventions_per_trial,
avg(case when accepted then 1 else 0 end) as accepted_rate,
percentile_cont(0.5) within group (order by reset_seconds) as median_reset_seconds
from eval_trials
where date = '2026-06-10'
group by operator_id
order by accepted_rate desc;
SQL mẫu cho failure reasons:
select
task,
discard_reason,
count(*) as n
from eval_trials
where accepted = false
group by task, discard_reason
order by n desc;
Nếu cart_pushing có nhiều balance_push_load, WBC/LMO và force interaction cần được ưu tiên. Nếu bag_packing có nhiều place_outside, hãy xem perception, calibration tay, hoặc action decoder. Nếu mọi task đều có camera_drop, đừng fine-tune model; sửa recorder trước.
Kết luận
Bài cuối của series đưa ta từ "thu được data" sang "biết data và robot có tốt không". WholeBodyVLA cho một blueprint kỹ thuật rõ: LAM học latent action tokens, VLA decode khoảng 10 Hz, LMO chạy 50 Hz, và benchmark phải ép robot phối hợp đi, xoay, squat, grasp, place và push. GR00T WBC cho một blueprint deploy khác: controller thấp tầng cần artifact rõ ràng như ONNX balance/walk policy, runtime đo được và test được.
Khi mở rộng lên 20 operator, đừng chỉ đếm số episode. Hãy đếm task success sạch, balance failures, intervention rate, latency, data acceptance và breakdown theo bag packing/box loading/cart pushing. Nếu sáu metric này ổn định, bạn có thể tăng ca thu dữ liệu với ít rủi ro hơn. Nếu chúng mâu thuẫn, hãy tin bảng lỗi hơn là cảm giác "robot có vẻ chạy được".


