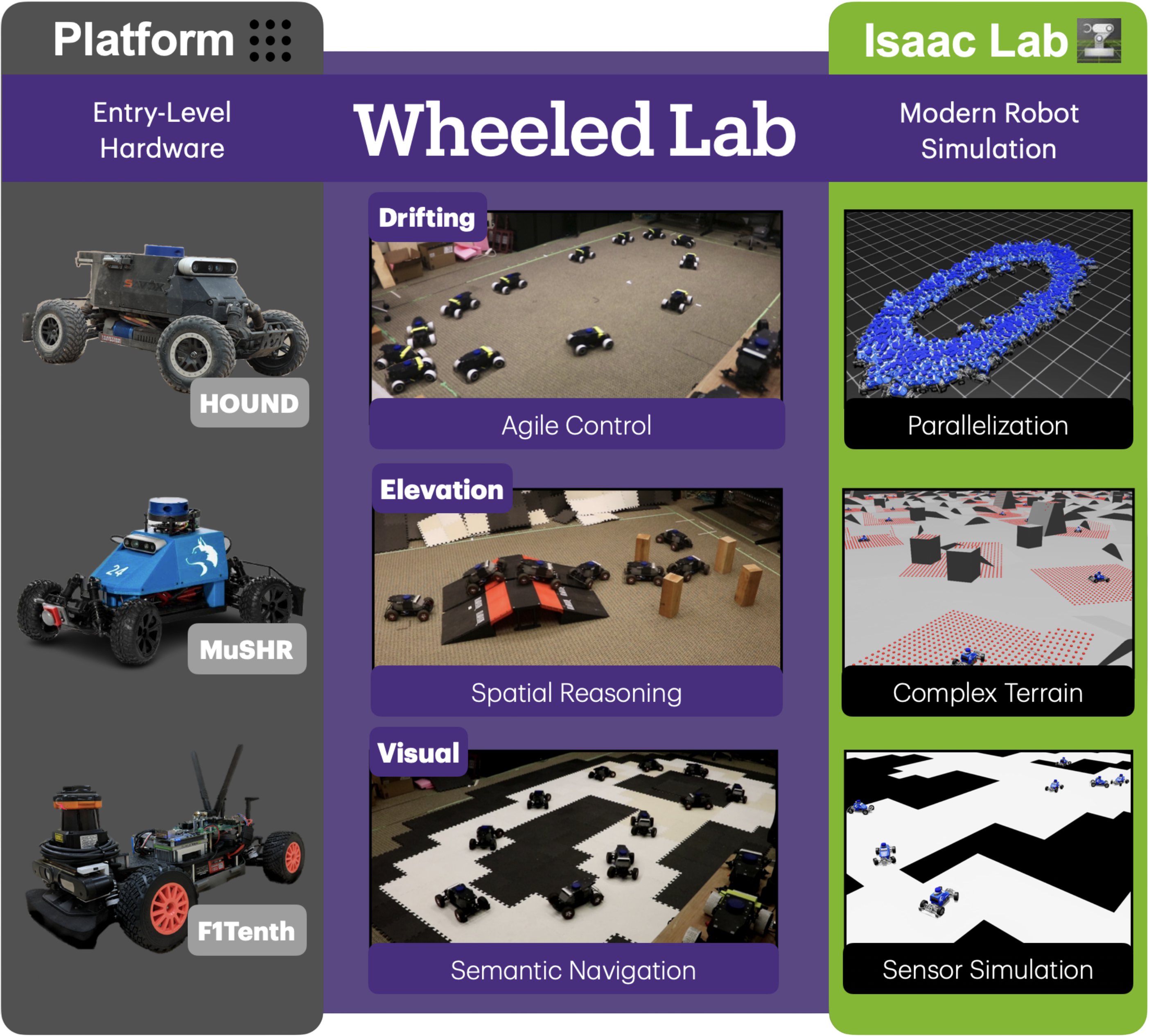
If you have ever read an RL robotics paper and sighed "I'd love to try this, but I have no GPU farm, no robot, no lab" — Wheeled Lab is built for you. Released by University of Washington's Robot Learning Lab and accepted at CoRL 2025, it lets you train an RC car to drift, climb hills, and follow camera waypoints, then deploy the policy zero-shot to a real vehicle. The cheapest variant costs ~$930, and a single RTX 3080 is enough to train.
In this guide we walk from the paper's idea, through architecture, installation, training, all the way to real-car deployment — with enough detail for an undergrad to reproduce.

1. What problem does Wheeled Lab solve?
Before Wheeled Lab, the wheeled-robot RL ecosystem was fragmented:
- Modern simulators (Isaac Lab, MuJoCo MJX) targeted humanoids and quadrupeds.
- Wheeled platforms (MuSHR, F1Tenth, HOUND) existed, but every group hand-rolled their own sim2real pipeline.
- Drift, off-road, visual nav had separate papers with closed code or bit-rotted repos.
Tyler Han and collaborators decided to fold everything into one Isaac-Lab-native ecosystem: one canonical car, one sim, one task suite, one deployment stack. The outcome: three zero-shot sim-to-real demos.
| Task | Description | Highlight |
|---|---|---|
| Controlled Drifting | Drift around an oval track | First zero-shot drift policy in literature |
| Elevation Traversal | Climb hills and obstacles | Learns from randomized height maps |
| Visual Navigation | Waypoint following from camera | 40×60 grayscale input |
The drift demo is the headline. Previous drift work required either online fine-tuning on the real car or a model-based MPC with accurate vehicle dynamics. Wheeled Lab shows that massive parallelization + domain randomization in Isaac Lab is enough.
Paper: Wheeled Lab: Modern Sim2Real for Low-cost, Open-source Wheeled Robotics — Han et al., CoRL 2025.
2. Hardware: $930 or $3000?
Wheeled Lab supports two primary platforms, both buyable on Amazon or DIY-able:
MuSHR-mini (~$930)
- Traxxas Slash 1/10 chassis
- Compute: Jetson Nano or Raspberry Pi 4
- Simple IMU, no LiDAR
- Good for indoor drift + visual nav
HOUND (~$3000)
- Traxxas X-Maxx 1/5 off-road truck
- Compute: Jetson Orin NX (~70 TOPS)
- Sensors: 2D LiDAR + RGB camera
- Wheelbase 0.28m, track width 0.23m, 3.5 kg
- Drive: converted to rear-wheel drive, wheels wrapped in tape to reduce friction → drift becomes feasible
The "tape-wrapped wheels" hack on HOUND is a deeply pragmatic engineering choice: rather than try to faithfully simulate soft rubber compounds, the team modifies the hardware to fit the sim.
3. Wheeled Lab architecture
WheeledLab/
├── source/
│ ├── wheeledlab/ # Core utilities, configs
│ ├── wheeledlab_assets/ # USD models for HOUND, MuSHR
│ ├── wheeledlab_tasks/ # Drift, Elevation, Visual envs
│ └── wheeledlab_rl/ # Training scripts, PPO configs
└── scripts/
└── train_rl.py # Main entry point
The four packages plug into Isaac Lab via standard registration: importing wheeledlab_tasks makes envs available via gym.make("Isaac-Drift-Hound-v0"), immediately usable with RSL-RL or rl_games.
End-to-end workflow:
flowchart LR
A[Isaac Lab Sim] --> B[Domain Randomization]
B --> C[1024 parallel envs]
C --> D[PPO Training]
D --> E[Policy .pt]
E --> F[Real Lab deploy]
F --> G[HOUND / MuSHR]
Core idea: train in sim with a wider distribution than reality, forcing the policy to learn robust behaviour across friction, mass, and latency. When the real car is encountered — and it lives inside that distribution — the policy only needs to recognize where in the distribution it is.
4. Step-by-step installation
4.1 System requirements
- Ubuntu 22.04 (20.04 works with the Isaac Sim binary route)
- NVIDIA GPU ≥ 10GB VRAM (RTX 3080+ recommended)
- Python 3.10
- Conda or miniconda
4.2 Conda environment
conda create -n WL python=3.10
conda activate WL
pip install --upgrade pip
4.3 Install Isaac Sim 4.5.0
pip install 'isaacsim[all,extscache]==4.5.0' \
--extra-index-url https://pypi.nvidia.com
First run downloads ~15 GB of asset cache. Run it overnight.
4.4 Install Isaac Lab v2.0.2
git clone --branch v2.0.2 https://github.com/isaac-sim/IsaacLab.git
cd IsaacLab
./isaaclab.sh -i
This installs omni.isaac.lab, omni.isaac.lab_tasks, rsl_rl.
4.5 Install Wheeled Lab
git clone https://github.com/UWRobotLearning/WheeledLab.git
cd WheeledLab/source
pip install -e wheeledlab
pip install -e wheeledlab_tasks
pip install -e wheeledlab_assets
pip install -e wheeledlab_rl
Then fix the standard NumPy 2 incompatibility:
pip install --force-reinstall "numpy<2"
Verify install:
python -c "import wheeledlab_tasks; print('OK')"
5. The Drift task: reward, observation, action
This is the most exciting part of the paper. Drift is not a normal control problem — you cannot say "follow this line"; you must encourage the car to slide while still tracking the line. Wheeled Lab uses six reward components:
| Reward | Meaning |
|---|---|
cross_track_distance |
Lateral distance from oval line → penalize drifting away |
velocity |
Encourage high speed |
side_slip |
Reward stable slip angles between 0–30° |
progress |
Forward progress counter-clockwise |
turn_energy |
Shaping for velocity in turn regions |
turn_left_go_right |
Shaping that encourages counter-steering — the very signature of drift |
That last reward is a sharp insight: to make the car learn drift, you must tell it that "steering opposite the curve" is good. Otherwise it converges to fast-but-no-drift driving, since straight-line speed already maximizes velocity and progress.
Action space
Two continuous dimensions:
- Steering: -1 → +1 mapped to ±30°
- Throttle: -1 → +1
Observation space
Low-dim vector containing:
- Linear & angular velocity (body frame)
- Yaw rate, slip angle
- Vector to nearest tracking point
- Last action (smoothing prior)
No images, no LiDAR for the drift task — sim2real becomes far easier.
6. Domain Randomization: the secret sauce
This is the heart of Wheeled Lab. Each episode resamples:
- Kinetic friction: ~0.2 → 0.8 (measured on the real car with a spring scale → midpoint ~0.4)
- Mass: ±20% nominal
- Center-of-mass offset: random cm-scale jitter
- Motor latency: 0–50ms, simulating MCU delay
- Tire stiffness: random Pacejka coefficients
Wide friction range is the pivotal choice: a real car runs on carpet, concrete, or asphalt — narrow randomization breaks transfer the moment the surface changes. After widening to ±100% around the midpoint, transfer worked.
This is also the central topic of Sim-to-Real Pipeline for Robotics — Wheeled Lab is a great real-world case study.
7. Training: 1024 envs, 5000 epochs, 1 GPU
Drift training command:
python source/wheeledlab_rl/scripts/train_rl.py \
--headless \
-r RSS_DRIFT_CONFIG
Default config:
| Hyperparameter | Value |
|---|---|
| Parallel envs | 1024 (baseline 64) |
| Training epochs | 5000 |
| Algorithm | PPO (RSL-RL) |
| GPU | 1× RTX 3080 |
| Wall-clock | ~6 hours |
Why 1024 instead of 64? Because domain randomization stretches the data distribution — you need a large batch to cover it per update, otherwise gradients get noisy. With 64 envs the paper reports the policy never converges.
Other configs:
# Elevation
python source/wheeledlab_rl/scripts/train_rl.py --headless -r RSS_ELEV_CONFIG
# Visual navigation
python source/wheeledlab_rl/scripts/train_rl.py --headless -r RSS_VISUAL_CONFIG
Visual nav uses 40×60 grayscale + velocity + last action — small enough to run real-time on Jetson Nano.
Disable W&B if needed:
... -r RSS_DRIFT_CONFIG train.log.no_wandb=True

8. Deploying to the real HOUND/MuSHR
After training, the policy is saved as policy.pt. To run it on hardware:
git clone https://github.com/UWRobotLearning/RealLab.git
cd RealLab
pip install -e .
On Jetson Orin NX (HOUND) or Jetson Nano (MuSHR-mini):
python deploy_drift.py --policy /path/to/policy.pt --vehicle hound
Runtime pipeline:
- IMU + encoder → compute velocity, yaw rate (~200Hz)
- Build observation vector
- Policy forward pass (~2ms on Orin NX)
- Output steering/throttle → ESC + servo via PWM
End-to-end latency ~10ms, real-time-safe for 1.6 m/s drift.
Real-world results
- Max slip angle: 58°
- Average speed: 1.6 m/s
- Recovery: when the car spins out, the policy auto-corrects back to the track
- Zero-shot: no fine-tuning on the real vehicle whatsoever
This is the first reported zero-shot sim-to-real transfer of a drift policy in literature. Prior work like Yunlong Song's drone racing or Velocidrone all required online fine-tuning.
9. Common pitfalls
- Forgetting
numpy<2→ TypeError on import. Force-reinstall right after Isaac Lab. - GPU < 10 GB → 1024 envs OOM. Drop to 256 envs and bump epochs to 15000.
- Wheels not wrapped in tape on HOUND → drift becomes inconsistent and the policy loses tracking. Per the paper, this is a non-negotiable detail.
- Surface too far from sim (e.g. sand, gravel) → policy fails. If you need exotic terrain, widen friction randomization to 0.05–1.2.
- MCU latency above 50ms → outside the sim envelope, jerky behaviour. Measure with an oscilloscope; if above 50ms, update ESC firmware.
- Track size differs from sim → drift policy is sensitive to corner radius. If the real track is ±30% off, retrain with track-size randomization.
10. What does Wheeled Lab teach us?
This project is a beautiful case study of three modern sim2real principles:
- Massive parallelism beats accurate simulation. Instead of solving a fancy Pacejka tire model, randomize a coarse model widely.
- Reward shaping from physics, not intuition.
turn_left_go_rightexists because the authors understood drift = counter-steer, not because they wanted "pretty driving". - Open-source ecosystem > open-source paper. Han's team released code, USD assets, deployment stack, and a hardware BOM. That is why the project will live long.
If you are entering RL for mobile robotics in Vietnam, this is the best on-ramp today: cheap, well-documented, and the UW lab actively answers GitHub issues.
I tested the drift task in sim — after 3 hours of training on an RTX 3090, the policy was carving smooth oval drifts at ~45° slip angle. Next step: build a MuSHR-mini and deploy it. A future post will cover that journey.