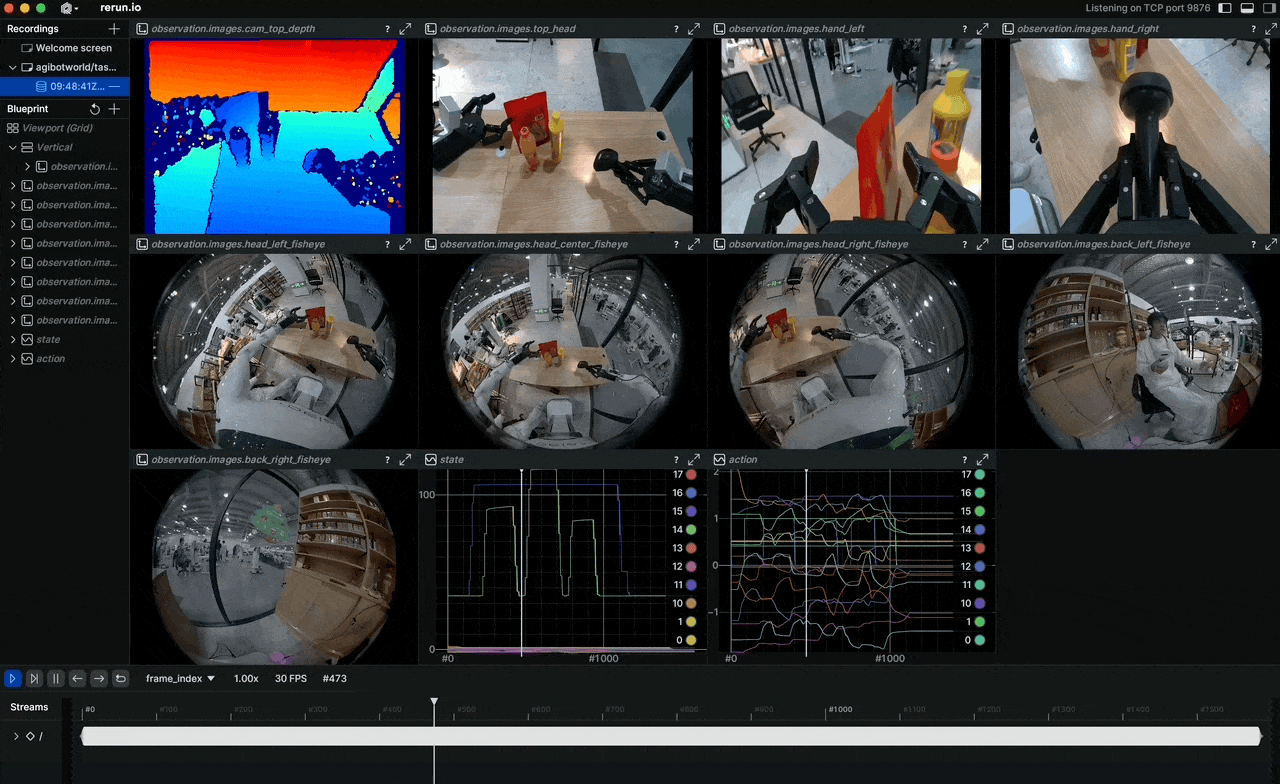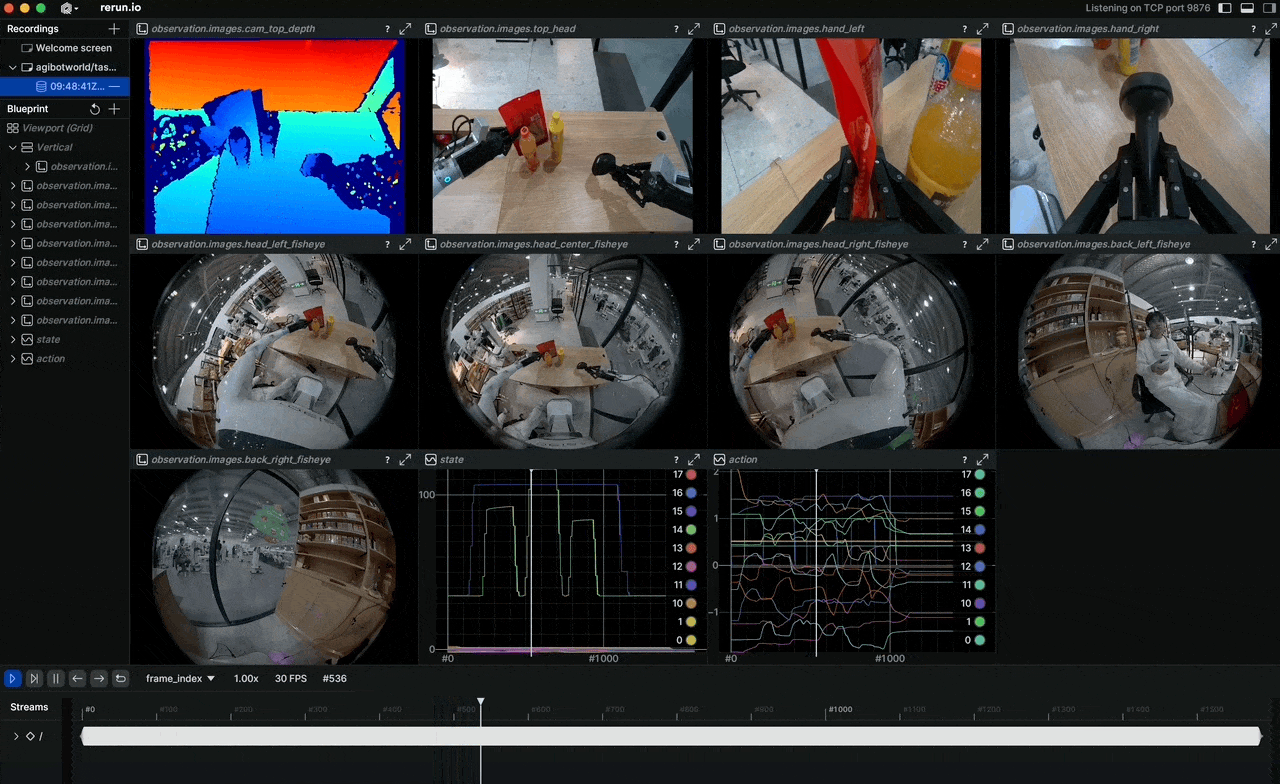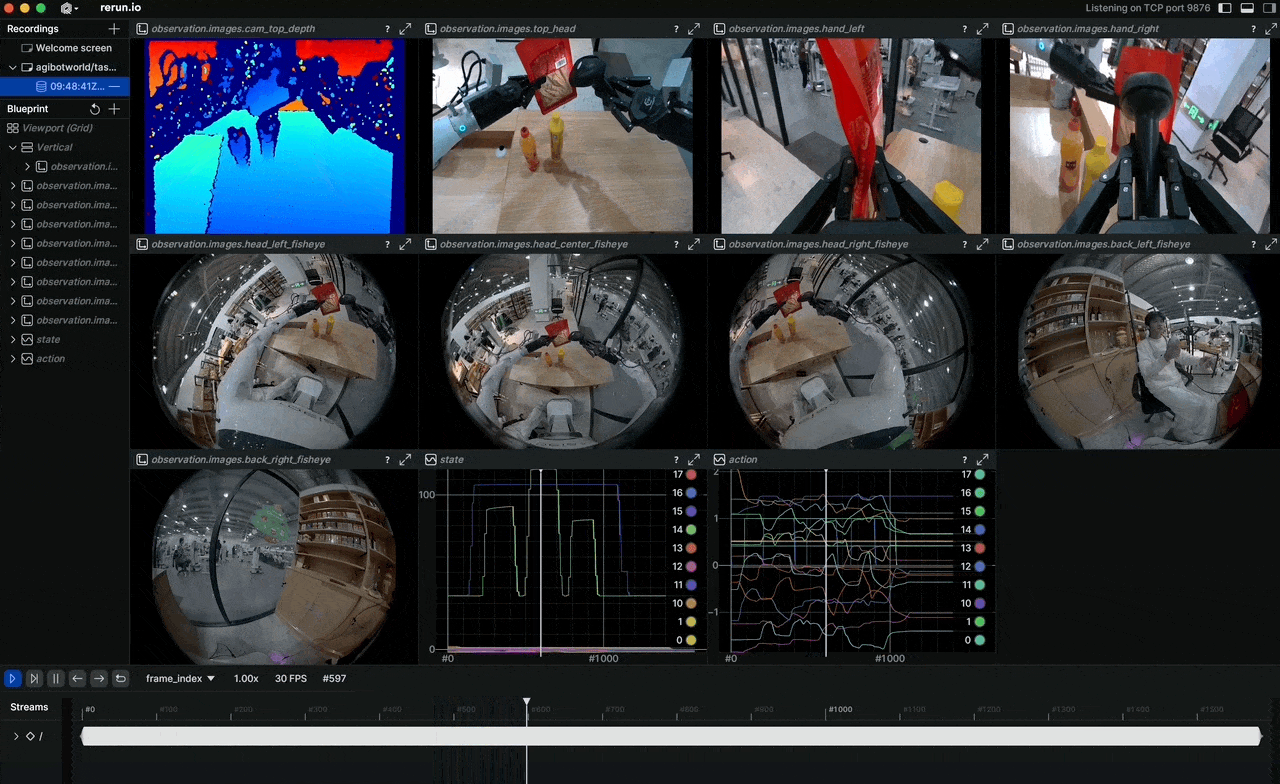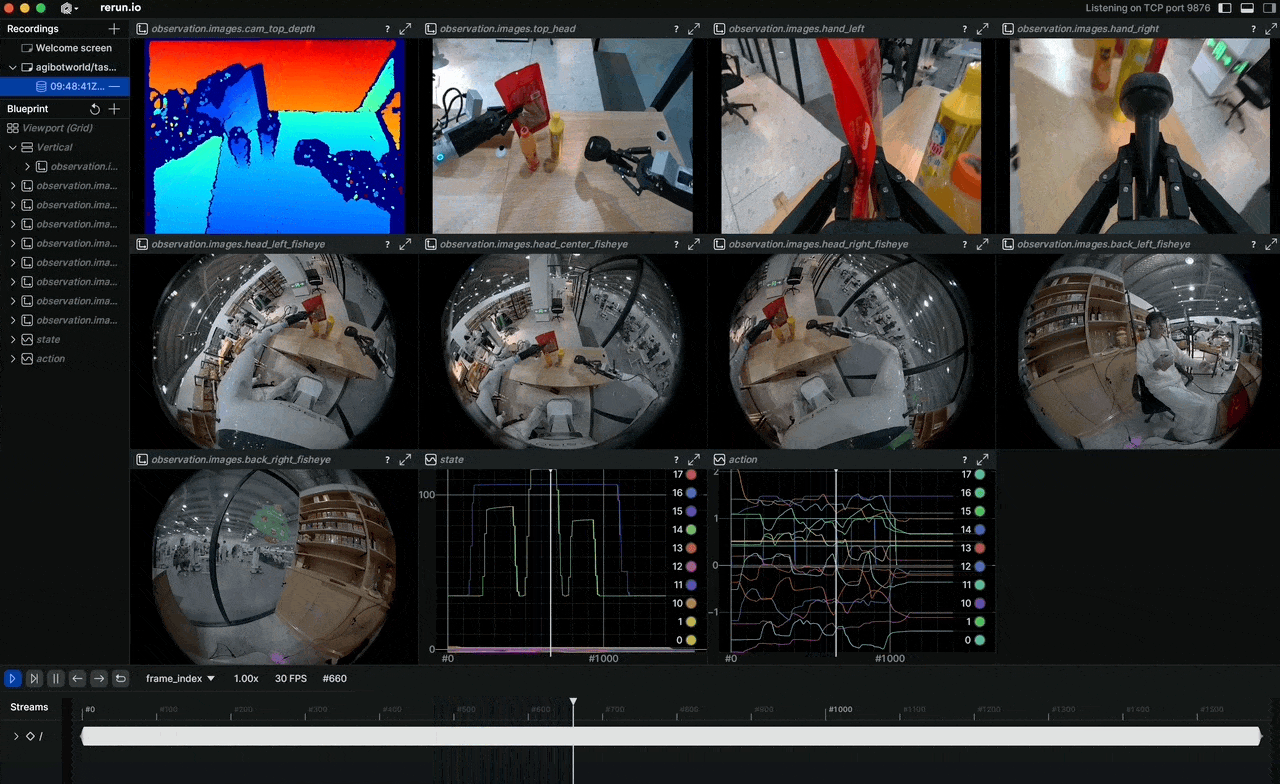
Why do robot imitation learning models still struggle with unseen situations? The answer almost always comes down to data quality and scale. In April 2026, AGIBOT open-sourced AGIBOT WORLD 2026 — a dataset built entirely from real-world demonstrations, with not a single synthetic pixel in Phase 1.
This isn't the first large-scale robotics dataset, but AGIBOT WORLD 2026 is different in a fundamental way: it combines scale with systematic collection. More than 100 homogeneous robots collected data in parallel, teleoperators were professionally trained, and every episode carries hierarchical annotations from task level down to individual keyframes. The robotics community is calling it "by far the largest dataset for humanoid robots."
The Core Problem: Why Does Real-World Data Matter More Than You Think?
In imitation learning, a robot learns by observing and replicating expert demonstrations. It sounds simple, but there is a fundamental challenge: distribution shift. During execution, the robot encounters states that were never present in the training data — and every small error compounds into bigger failures (known as compounding errors).
Synthetic data from simulators helps with scale, but introduces a sim-to-real gap: lighting is artificial, object textures are imprecise, contact dynamics are wrong. Models trained on synthetic data often "break" when they meet the real world.
AGIBOT WORLD 2026 takes the opposite approach: 100% real-world data, collected in actual environments — commercial spaces, apartments, warehouses. Collection costs are far higher, but models trained this way can deploy directly without domain adaptation.

The Collection Platform: AGIBOT G2 Robot
The entire dataset is collected on the AGIBOT G2 — an industrial wheeled humanoid with impressive specifications:
| Specification | Value |
|---|---|
| Height | 175 cm |
| Weight | 55 kg |
| Degrees of Freedom | 49+ DoF |
| Arm (each side) | 7-DoF with force sensors |
| Payload | 5 kg per arm |
| Collection frequency | 30 Hz |
| IP Rating | IP42 |
| Onboard compute | Rhino R1 (500 TOPS) + NVIDIA Jetson Thor T5000 (2070 TFLOPS) |
The standout feature of the G2 is its dual 7-DoF arms with full joint torque sensors — meaning the robot captures not just positions but the forces at each joint. This force-control data is critical for tasks requiring precise contact dynamics such as electronics assembly or handling thin materials.
The full sensor suite includes LiDAR for 3D mapping, RGB-D for depth perception, multiple RGB cameras for 360° awareness, fingertip tactile sensors, and IMU — all synchronized in a single pipeline.
Dataset Architecture: 5 Phases, 5 Research Directions
AGIBOT WORLD 2026 is structured around 5 release phases, each corresponding to a core research direction in embodied AI:
Phase 1: Imitation Learning ✅ LIVE (April 2026)
Phase 2: Primitive Discovery 🔜 Coming soon
Phase 3: Multi-granularity 🔜 Coming soon
Language Conditioning
Phase 4: Reasoning to Action 🔜 Coming soon
Phase 5: World Model 🔜 Coming soon
Phase 1 — Imitation Learning (now open): Hundreds of hours of data collected primarily in commercial and service environments. Includes task-level demonstrations, error-recovery trajectories (crucial for robustness), and hierarchical annotations.
Key differentiator: Free-form Collection. Unlike many datasets that use fixed scripts, AGIBOT uses a free-form collection mode where teleoperators execute tasks based on real-time conditions — not a predetermined script. The result is significantly higher diversity across:
- Object categories
- Initial configurations
- Execution sequences
Data Format & Structure
The dataset is hosted on Hugging Face at agibot-world/AgiBotWorld2026 in a format compatible with LeRobot v2.1.
AgiBotWorld2026/
├── meta/
│ ├── info.json # Schema: camera names, sensors, dimensions
│ └── episodes.jsonl # Episode-level metadata (task, duration, quality)
├── data/
│ └── *.parquet # Joint states, actions, force data (30 Hz)
└── videos/
└── *.mp4 # Synchronized camera streams
Four-level hierarchical annotation — the dataset's greatest strength:
Task level
└── Atomic Skill level (primitives: grasp, move, place...)
└── 2D BBox level (objects involved in each skill)
└── Keyframe level (most important frames)
This three-tier annotation structure enables research into complete task imitation learning, primitive discovery (learning atomic skills independently), or language-conditioned manipulation at multiple levels of granularity.
Available modalities:
observation.images.cam_*: Multi-camera RGB streamsobservation.images.cam_*_depth: RGB-D streamsobservation.state: Full joint states (49+ DoF)observation.tactile: Fingertip tactile signalsaction: Target joint positions/velocitiesaction.force: Force/torque data at wrist

GO-1: The ViLLA Model Architecture
Alongside the dataset, AGIBOT releases GO-1 — a manipulation foundation model built on an entirely new architecture: Vision-Language-Latent-Action (ViLLA).
Why not use a standard VLA? Traditional Vision-Language-Action models predict actions directly from vision and language inputs. The problem is the enormous semantic gap between "understanding visual-language context" and "controlling a robot arm." ViLLA adds an intermediate layer — latent action tokens — to bridge this gap.
ViLLA Architecture (3 Layers)
┌────────────────────────────────────────────┐
│ VLM Backbone │
│ (scene understanding + language) │
└────────────────────┬───────────────────────┘
│ visual + language features
┌──────────▼──────────┐
│ Latent Planner │ ← Masked Language Modeling
│ (MoE module) │ → discrete latent action tokens
└──────────┬──────────┘
│ latent tokens
┌──────────▼──────────┐
│ Action Expert │ ← Diffusion objective
│ │ → low-level joint commands (30 Hz)
└─────────────────────┘
VLM Backbone: Pre-trained on large-scale internet data — provides general scene understanding, object recognition, and language instruction following.
Latent Planner (MoE): Uses masked language modeling to generate discrete latent action tokens. Trained on data from multiple embodiments and human demonstrations — building a shared "action vocabulary."
Action Expert: A diffusion-based module that receives latent tokens and regresses low-level joint commands via iterative denoising. The diffusion objective is well-suited for modeling the continuous, multi-modal distribution of manipulation actions.
Environment Setup
# Clone the repository
git clone https://github.com/OpenDriveLab/AgiBot-World.git
cd AgiBot-World
# Create conda environment
conda create -n agibot python=3.10 -y
conda activate agibot
# Install dependencies (CUDA 12.4 required)
pip install -e ".[go1]"
# Download dataset from Hugging Face
pip install huggingface_hub
python -c "
from huggingface_hub import snapshot_download
snapshot_download(
repo_id='agibot-world/AgiBotWorld2026',
repo_type='dataset',
local_dir='./data/AgiBotWorld2026'
)
"
Training Configuration
Create a YAML config file with three main parameter groups:
# config/go1_train.yaml
# 1. Model architecture
model:
architecture: "go1" # or "go1_air" (lighter variant)
action_chunk_size: 16 # steps predicted per inference
diffusion_steps: 10 # denoising iterations
# 2. Data / Space settings
space:
state_dim: 49 # number of joint states
action_dim: 49 # action space dimensions
control_frequency: 30 # Hz
default_prompt: "Pick up the object and place it in the box."
# 3. Training hyperparameters
training:
batch_size: 128
learning_rate: 1e-4
num_epochs: 100
warmup_steps: 1000
gradient_clip: 1.0
Running Training
# Set run name and start training
RUNNAME=go1_imitation_v1 bash go1/shell/train.sh config/go1_train.yaml
# Checkpoints and logs are saved at:
# experiment/go1_imitation_v1/
# ├── checkpoints/
# └── logs/
Inference on Robot
from go1.model import GO1Policy
from go1.data import ObservationProcessor
# Load checkpoint
policy = GO1Policy.from_pretrained("experiment/go1_imitation_v1/checkpoints/best")
processor = ObservationProcessor(config)
# Inference loop
obs = robot.get_observation() # dict with cameras, joints, tactile
processed = processor(obs)
with torch.no_grad():
action = policy.predict(
images=processed["images"],
state=processed["state"],
language="Place the cup on the tray"
)
robot.execute_action(action)
Results: GO-1 vs. State of the Art
Benchmark results on the AgiBot World evaluation suite:
| Model | Success Rate | Task Completion Score |
|---|---|---|
| Previous SOTA | 46% | 0.61 |
| GO-1 Air | 68% | 0.71 |
| GO-1 (full) | 78% | 0.85 |
GO-1 full raises the success rate from 46% to 78% (+32 percentage points) compared to the previous state of the art. The Latent Planner module alone contributes an additional +0.12 task completion score compared to variants without it.
AGIBOT World Challenge at ICRA 2026
Alongside the dataset, AGIBOT is running the AGIBOT World Challenge at ICRA 2026 with a $530,000 USD prize pool — one of the largest robotics competitions ever organized.
Track 1 — Reasoning to Action: Evaluates reasoning and action execution capabilities. 10 progressively challenging tasks including dual-arm collaboration, long-horizon operations, and high-precision manipulation (logistics sorting, office organization, retail operations, daily services). Two stages: online simulation and offline real-robot finals.
Track 2 — World Model: Train video generation models on the AGIBOT WORLD dataset to produce interaction videos of robots executing 10 task types across real-world environments (furniture, retail, industrial settings).
Key Timeline:
- 12 Feb 2026: Global registration opens
- 28 Feb 2026: Online competition servers live
- 20 Apr 2026: Online submission deadline
- 30 Apr 2026: Online stage results announced
- 01 Jun 2026: Real-robot finals at ICRA 2026
The leaderboard is updated in real time at agibot-world/AgiBotWorldChallenge-2026 on Hugging Face.
Why This Is a Turning Point
Looking back at the history of imitation learning for robot manipulation, data has always been the bottleneck:
- 2022: RT-1 (Google) — 130k episodes, multiple robots but simple tasks
- 2023: Open X-Embodiment — aggregated from many labs, inconsistent formats
- 2024: RoboTwin, LIBERO — high-quality synthetic data but sim-to-real gap remains
- 2026: AGIBOT WORLD — 100% real-world, >1M trajectories, 217 tasks, 5 deployment scenarios
The key point isn't just scale — it's the systematic collection pipeline. Edge-side processing (teleoperator training, robot consistency verification) combined with cloud-side processing (automatic annotation, manual review, algorithm closed-loop verification) produces consistent data quality at industrial scale.
If you're researching imitation learning or want to understand why the most advanced robotics models of 2026 perform so well, AGIBOT WORLD 2026 is a case study you cannot skip.
Conclusion
AGIBOT WORLD 2026 marks the industry's shift from "data that's good enough" to "industrial-quality data at scale." A 100% real-world dataset with four-level hierarchical annotations, combined with the GO-1 ViLLA model and a $530K ICRA 2026 challenge, is clear evidence that China is placing a major bet on embodied AI.
With Phase 1 already live and four more phases coming throughout 2026, now is the right time to start exploring — whether you're a researcher, a robotics engineer, or simply curious about the future of robotics.
Resources:
- GitHub: OpenDriveLab/AgiBot-World
- Dataset: huggingface.co/datasets/agibot-world/AgiBotWorld2026
- Paper: AgiBot World Colosseo (arXiv:2503.06669) — IROS 2025 Best Paper Award Finalist & IEEE TRO 2026

