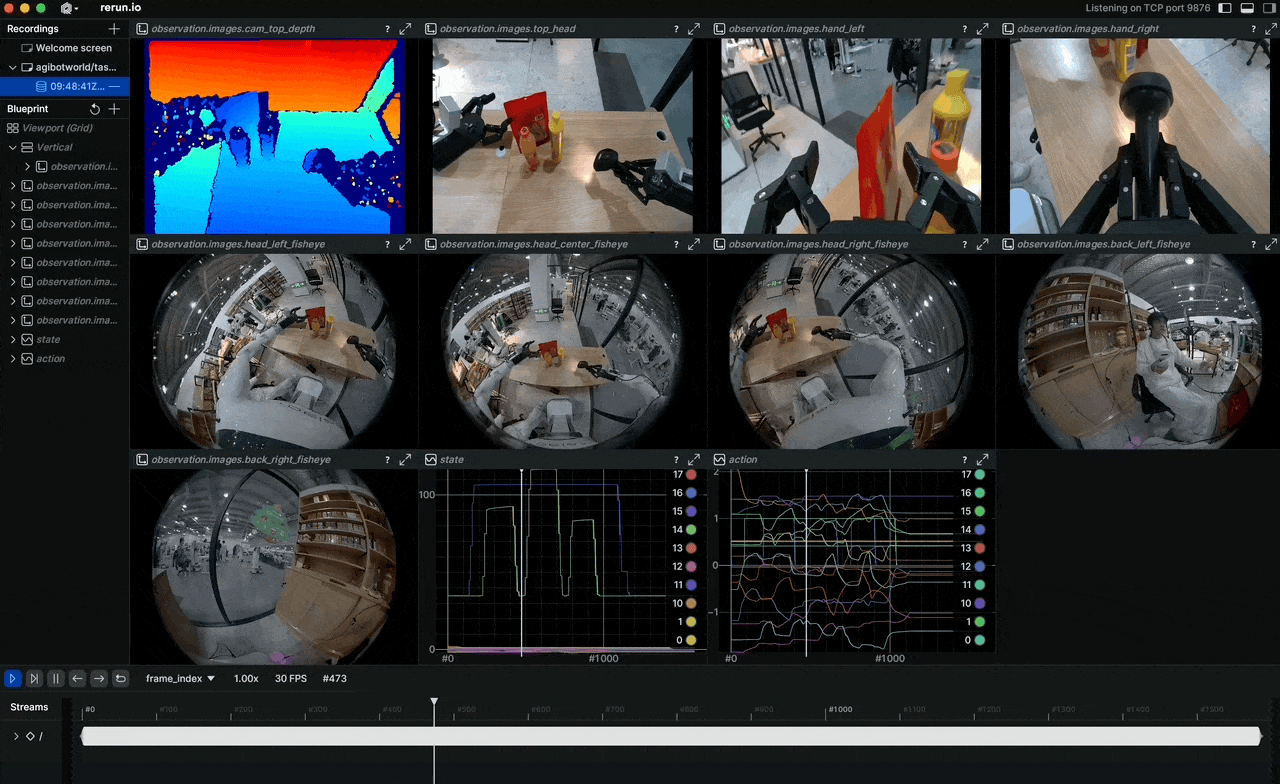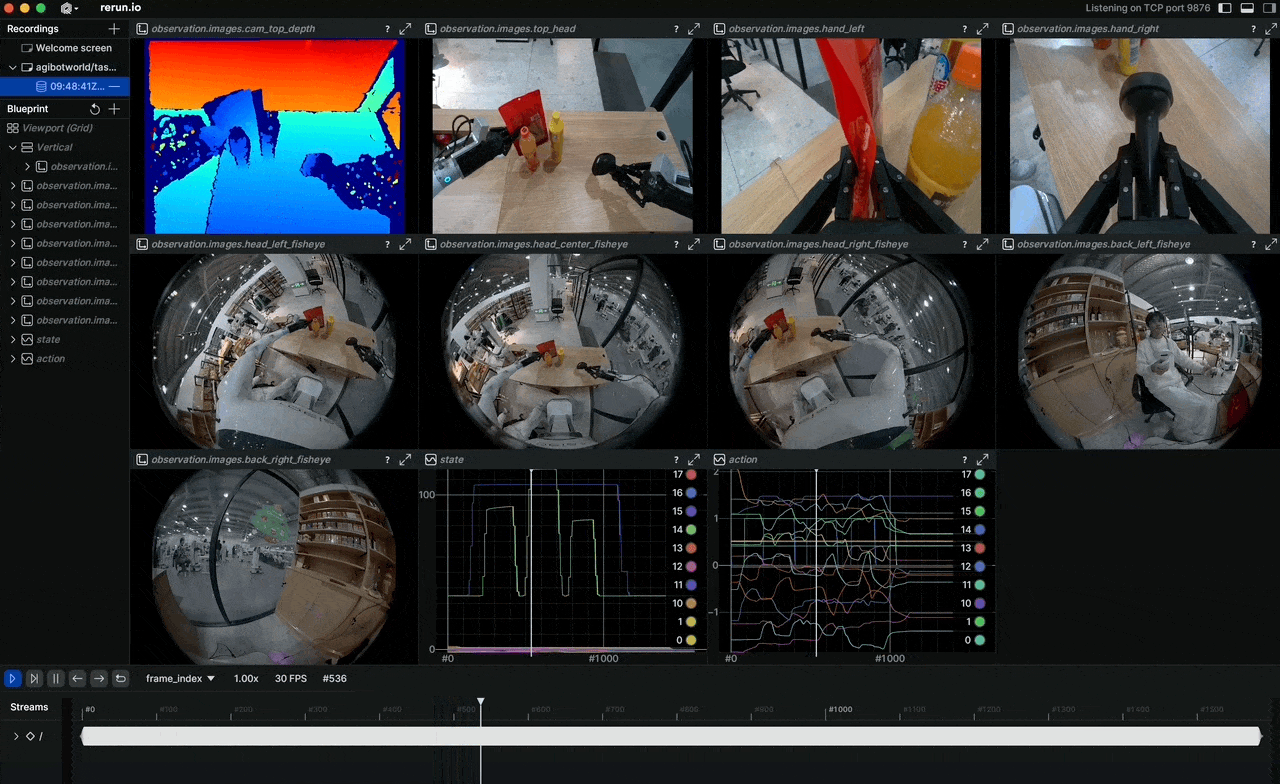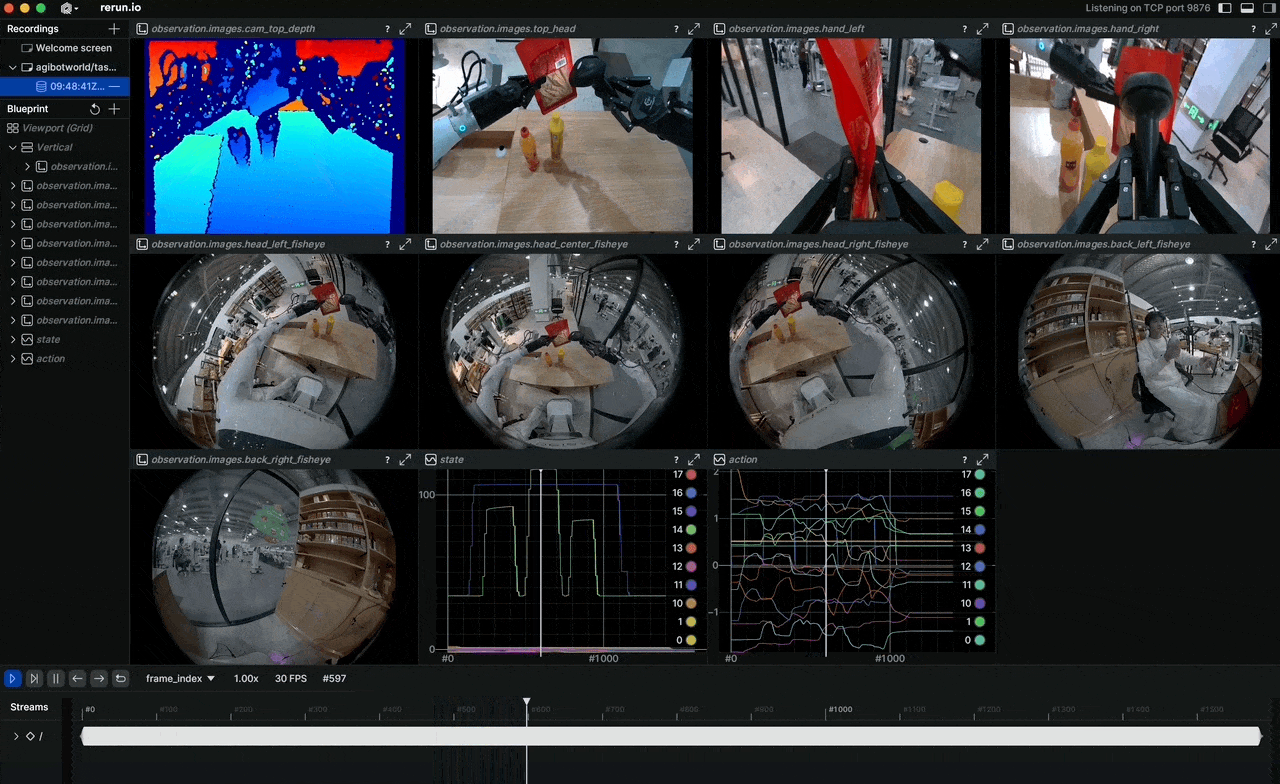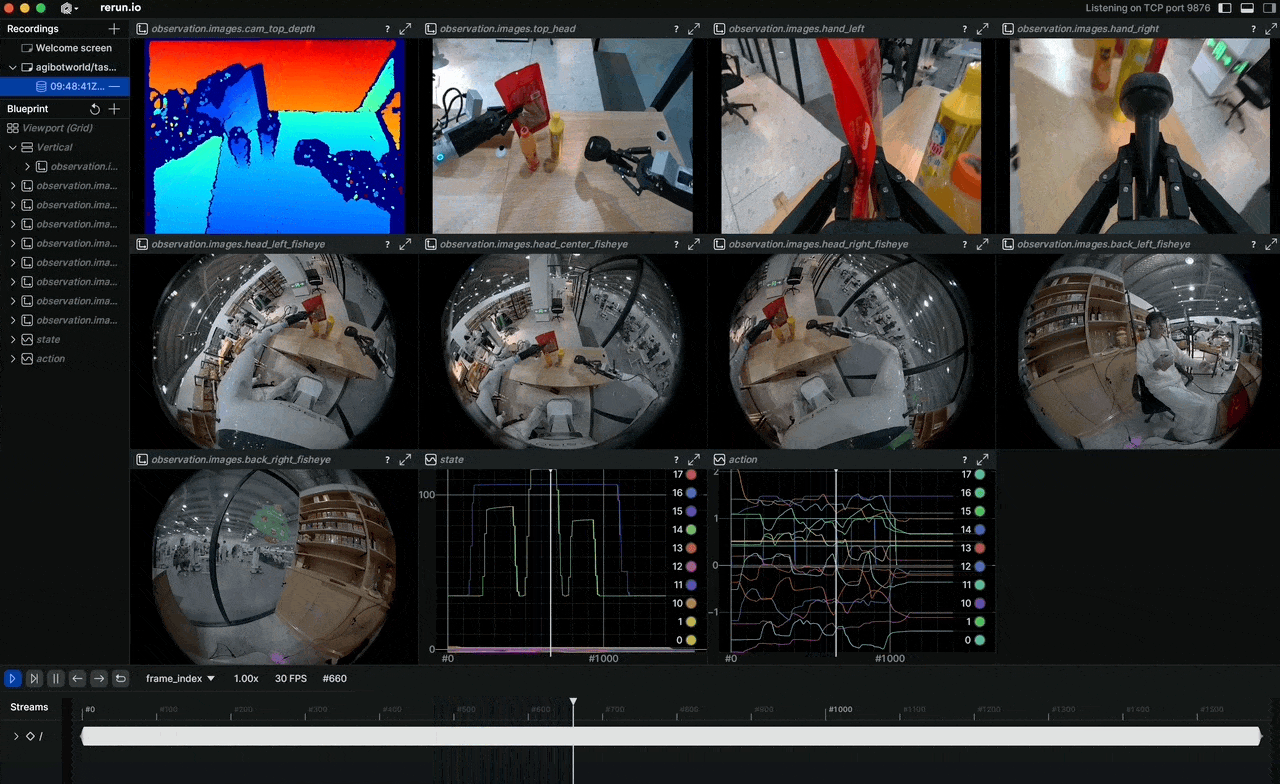
Bạn có bao giờ thắc mắc tại sao các mô hình robot học bắt chước vẫn còn chật vật khi gặp tình huống chưa thấy bao giờ? Câu trả lời thường nằm ở chất lượng và quy mô dữ liệu huấn luyện. Tháng 4/2026, AGIBOT mở nguồn AGIBOT WORLD 2026 — dataset được xây dựng hoàn toàn từ dữ liệu thế giới thực, không một pixel nào là tổng hợp ở phase đầu tiên.
Đây không phải lần đầu ngành robotics thấy dataset lớn, nhưng AGIBOT WORLD 2026 khác ở chỗ: quy mô và cách thu thập. Hơn 100 robot đồng nhất thu thập dữ liệu song song, teleoperator được huấn luyện bài bản, và mọi episode đều có annotation phân cấp từ task-level xuống tới từng keyframe. Cộng đồng nghiên cứu đang gọi đây là "by far the largest dataset for humanoid robots."
Bài toán gốc: Tại sao data thật quan trọng hơn tưởng?
Trong imitation learning, robot học bắt chước bằng cách quan sát và sao chép các demonstration từ expert. Nghe đơn giản, nhưng có một vấn đề cốt lõi: distribution shift. Khi robot thực thi, nó sẽ gặp những trạng thái không có trong dữ liệu huấn luyện — và mỗi lỗi nhỏ có thể khuếch đại thành lỗi lớn hơn (còn gọi là compounding errors).
Data tổng hợp (synthetic) từ simulator giúp giải quyết vấn đề quy mô, nhưng lại tạo ra sim-to-real gap: ánh sáng không thật, texture đồ vật không chính xác, contact dynamics sai. Mô hình huấn luyện trên data tổng hợp thường bị "giật mình" khi gặp thế giới thực.
AGIBOT WORLD 2026 chọn hướng ngược lại: 100% real-world data, thu thập trong môi trường thực tế — không gian thương mại, căn hộ, nhà kho. Chi phí thu thập cao hơn nhiều, nhưng mô hình huấn luyện xong có thể deploy thẳng mà không cần domain adaptation.

Nền tảng thu thập: Robot AGIBOT G2
Toàn bộ dataset được thu thập trên AGIBOT G2 — robot humanoid bánh xe công nghiệp với những thông số đáng nể:
| Thông số | Giá trị |
|---|---|
| Chiều cao | 175 cm |
| Cân nặng | 55 kg |
| Bậc tự do | 49+ DoF |
| Tay (mỗi bên) | 7-DoF, có force sensor |
| Payload | 5 kg/tay |
| Tần số thu thập | 30 Hz |
| IP rating | IP42 |
| Onboard compute | Rhino R1 (500 TOPS) + NVIDIA Jetson Thor T5000 (2070 TFLOPS) |
Điều đặc biệt ở G2 là dual 7-DoF arms với full joint torque sensors — có nghĩa là robot không chỉ ghi lại vị trí, mà còn ghi lại lực tác động tại từng khớp. Đây là dữ liệu force-control quan trọng cho các task đòi hỏi contact dynamics chính xác như lắp linh kiện điện tử hay xử lý vật liệu mỏng.
Hệ thống cảm biến đầy đủ: LiDAR cho 3D mapping, RGB-D cho depth perception, nhiều camera RGB cho góc quan sát 360°, cảm biến xúc giác (tactile) trên đầu ngón tay, và IMU. Tất cả được đồng bộ hóa trong một pipeline duy nhất.
Kiến trúc Dataset: 5 Phase — 5 Hướng nghiên cứu
AGIBOT WORLD 2026 được thiết kế theo 5 phase phát hành, mỗi phase tương ứng với một hướng nghiên cứu cốt lõi trong embodied AI:
Phase 1: Imitation Learning ✅ LIVE (April 2026)
Phase 2: Primitive Discovery 🔜 Sắp ra
Phase 3: Multi-granularity 🔜 Sắp ra
Language Conditioning
Phase 4: Reasoning to Action 🔜 Sắp ra
Phase 5: World Model 🔜 Sắp ra
Phase 1 — Imitation Learning (đang mở): Hàng trăm giờ dữ liệu thu thập chủ yếu trong môi trường thương mại và dịch vụ. Bao gồm task-level demonstrations, error-recovery trajectories (quan trọng cho robustness), và hierarchical annotations.
Điểm đặc biệt: Free-form Collection. Khác với nhiều dataset dùng kịch bản cố định, AGIBOT sử dụng free-form collection mode: teleoperator thực hiện task dựa trên điều kiện thực tế tại từng thời điểm, không theo script. Kết quả là diversity cao hơn đáng kể về:
- Loại đồ vật (object categories)
- Cấu hình ban đầu (initial configurations)
- Thứ tự thực thi (execution sequences)
Format & Cấu trúc Dữ liệu
Dataset được host trên Hugging Face tại agibot-world/AgiBotWorld2026 với format tương thích LeRobot v2.1.
AgiBotWorld2026/
├── meta/
│ ├── info.json # Schema: camera names, sensors, dimensions
│ └── episodes.jsonl # Episode-level metadata (task, duration, quality)
├── data/
│ └── *.parquet # Joint states, actions, force data (30Hz)
└── videos/
└── *.mp4 # Synchronized camera streams
Annotation phân cấp — đây là điểm mạnh nhất của dataset:
Task level
└── Atomic Skill level (primitive actions: grasp, move, place...)
└── 2D BBox level (vật thể liên quan trong mỗi skill)
└── Keyframe level (các frame quan trọng nhất)
Annotation 3 cấp này cho phép nghiên cứu nhiều vấn đề khác nhau: imitation learning toàn bộ task, primitive discovery (học atomic skills độc lập), hay language-conditioned manipulation với nhiều độ chi tiết ngôn ngữ.
Các modalities có sẵn:
observation.images.cam_*: Multi-camera RGB streamsobservation.images.cam_*_depth: RGB-D streamsobservation.state: Full joint states (49+ DoF)observation.tactile: Fingertip tactile signalsaction: Target joint positions/velocitiesaction.force: Force/torque data at wrist

GO-1: Mô hình ViLLA Tiên tiến
Song song với dataset, AGIBOT phát hành GO-1 — mô hình foundation cho manipulation với kiến trúc hoàn toàn mới: Vision-Language-Latent-Action (ViLLA).
Câu hỏi đặt ra: tại sao không dùng VLA thông thường? VLA (Vision-Language-Action) model truyền thống đưa ra action trực tiếp từ vision + language input. Vấn đề là khoảng cách ngữ nghĩa quá lớn giữa "hiểu ngôn ngữ hình ảnh" và "điều khiển cánh tay robot". ViLLA thêm một tầng trung gian — latent action tokens — để bridge khoảng cách này.
Kiến trúc ViLLA (3 tầng)
┌────────────────────────────────────────────┐
│ VLM Backbone │
│ (scene understanding + language) │
└────────────────────┬───────────────────────┘
│ visual + language features
┌──────────▼──────────┐
│ Latent Planner │ ← Masked Language Modeling
│ (MoE module) │ → discrete latent action tokens
└──────────┬──────────┘
│ latent tokens
┌──────────▼──────────┐
│ Action Expert │ ← Diffusion objective
│ │ → low-level joint commands (30Hz)
└─────────────────────┘
VLM Backbone: Được pre-train trên lượng lớn internet data — cho khả năng hiểu ngữ cảnh, nhận dạng đồ vật, và follow language instruction tổng quát.
Latent Planner (MoE): Sử dụng masked language modeling để sinh ra các discrete latent action tokens. Được train trên data từ nhiều embodiment khác nhau và cả human demonstrations — giúp model xây dựng "từ điển hành động" chung.
Action Expert: Module diffusion-based, nhận latent tokens và regress ra low-level joint commands qua quá trình iterative denoising. Diffusion objective phù hợp để model phân phối liên tục của action, đặc biệt cho manipulation phức tạp nhiều mode.
Cài đặt môi trường
# Clone repo
git clone https://github.com/OpenDriveLab/AgiBot-World.git
cd AgiBot-World
# Tạo conda environment
conda create -n agibot python=3.10 -y
conda activate agibot
# Cài dependencies (CUDA 12.4 required)
pip install -e ".[go1]"
# Download dataset từ Hugging Face
pip install huggingface_hub
python -c "
from huggingface_hub import snapshot_download
snapshot_download(
repo_id='agibot-world/AgiBotWorld2026',
repo_type='dataset',
local_dir='./data/AgiBotWorld2026'
)
"
Cấu hình Training
Tạo file config YAML với 3 nhóm tham số chính:
# config/go1_train.yaml
# 1. Model architecture
model:
architecture: "go1" # hoặc "go1_air" (nhẹ hơn)
action_chunk_size: 16 # số bước dự đoán cùng lúc
diffusion_steps: 10 # số bước denoising
# 2. Data / Space settings
space:
state_dim: 49 # số joint states
action_dim: 49 # số dimensions của action
control_frequency: 30 # Hz
default_prompt: "Pick up the object and place it in the box."
# 3. Training hyperparameters
training:
batch_size: 128
learning_rate: 1e-4
num_epochs: 100
warmup_steps: 1000
gradient_clip: 1.0
Chạy Training
# Set run name và bắt đầu train
RUNNAME=go1_imitation_v1 bash go1/shell/train.sh config/go1_train.yaml
# Checkpoints và logs lưu tại:
# experiment/go1_imitation_v1/
# ├── checkpoints/
# └── logs/
Inference trên Robot
from go1.model import GO1Policy
from go1.data import ObservationProcessor
# Load checkpoint
policy = GO1Policy.from_pretrained("experiment/go1_imitation_v1/checkpoints/best")
processor = ObservationProcessor(config)
# Inference loop
obs = robot.get_observation() # dict với cameras, joints, tactile
processed = processor(obs)
with torch.no_grad():
action = policy.predict(
images=processed["images"],
state=processed["state"],
language="Place the cup on the tray"
)
robot.execute_action(action)
Kết quả: GO-1 vs. SOTA
Kết quả benchmark trên AgiBot World evaluation suite:
| Mô hình | Success Rate | Task Completion Score |
|---|---|---|
| Previous SOTA | 46% | 0.61 |
| GO-1 Air | 68% | 0.71 |
| GO-1 (full) | 78% | 0.85 |
GO-1 full tăng success rate từ 46% lên 78% (+32 percentage points) so với SOTA trước đó. Latent Planner riêng mình đóng góp thêm +0.12 task completion score so với variant không có module này.
AGIBOT World Challenge tại ICRA 2026
Cùng với dataset, AGIBOT tổ chức AGIBOT World Challenge tại ICRA 2026 với prize pool $530,000 USD — một trong những cuộc thi robotics lớn nhất từ trước đến nay.
Track 1 — Reasoning to Action: Đánh giá khả năng lập luận và thực thi hành động. 10 task thách thức bao gồm dual-arm collaboration, long-horizon operations, và high-precision manipulation (logistics sorting, office organization, retail operations). Gồm 2 giai đoạn: online simulation và offline real-robot finals.
Track 2 — World Model: Huấn luyện video generation model trên AGIBOT WORLD dataset để sinh ra interaction videos của robot thực thi 10 loại task khác nhau trong các môi trường thực tế (furniture, retail, industrial).
Timeline quan trọng:
- 12/02/2026: Mở đăng ký toàn cầu
- 28/02/2026: Server thi đấu online
- 20/04/2026: Đóng submission online
- 30/04/2026: Công bố kết quả online
- 01/06/2026: Real-robot finals tại ICRA 2026
Leaderboard được cập nhật real-time trên Hugging Face tại agibot-world/AgiBotWorldChallenge-2026.
Tại sao đây là bước ngoặt?
Nhìn lại lịch sử imitation learning cho robot manipulation, vấn đề dữ liệu luôn là nút thắt cổ chai:
- 2022: RT-1 (Google) — 130k episodes, nhiều robot nhưng task đơn giản
- 2023: Open X-Embodiment — aggregate từ nhiều lab, format không đồng nhất
- 2024: RoboTwin, LIBERO — data tổng hợp quality cao nhưng sim-to-real gap còn tồn tại
- 2026: AGIBOT WORLD — 100% real-world, >1M trajectories, 217 tasks, 5 deployment scenarios
Điểm mấu chốt không phải chỉ là quy mô — mà là quy trình thu thập có hệ thống. Edge-side processing (training teleoperator, consistency verification) kết hợp với cloud-side processing (automatic annotation, manual review, algorithm closed-loop) tạo ra data quality nhất quán ở quy mô công nghiệp.
Nếu bạn đang nghiên cứu về imitation learning hay muốn hiểu tại sao các mô hình robotics tiên tiến nhất năm 2026 lại mạnh như vậy, AGIBOT WORLD 2026 là case study không thể bỏ qua.
Kết luận
AGIBOT WORLD 2026 đánh dấu sự chuyển dịch của cả ngành từ "dữ liệu đủ dùng" sang "dữ liệu chất lượng công nghiệp ở quy mô lớn." Dataset 100% real-world với annotation phân cấp 4 cấp độ, kết hợp với mô hình GO-1 ViLLA và challenge ICRA 2026 với prize pool $530K, là minh chứng rõ ràng rằng Trung Quốc đang đặt cược lớn vào embodied AI.
Với Phase 1 đã live và 4 phase tiếp theo sẽ ra trong năm 2026, đây là thời điểm tốt để bắt đầu khám phá — dù bạn là researcher, kỹ sư robotics, hay chỉ đơn giản là tò mò về tương lai của robot.
Resources:
- GitHub: OpenDriveLab/AgiBot-World
- Dataset: huggingface.co/datasets/agibot-world/AgiBotWorld2026
- Paper: AgiBot World Colosseo (arXiv:2503.06669) — IROS 2025 Best Paper Award Finalist & IEEE TRO 2026

